

nginx笔记


Nginx 是一款轻量级的 Web 服务器、反向代理服务器,它内存占用少、启动速度快、并发能力强,在互联网项目中有广泛应用。
文章目录
一、简介
-
Nginx 是什么?
- Nginx是一款轻量级的 Web 服务器、反向代理服务器,由于它的内存占用少,启动极快,高并发能力强,在互联网项目中广泛应用。
- 总结:高性能的HTTP和反向代理web服务器
-
Nginx 的不同版本:
-
开源版:
- Nginx
- OpenResty(lua脚本扩展)
- Tengine(C语言扩展)
-
商业版:Nginx Plus
-
-
yum安装
yum -y install nginx -
常用指令
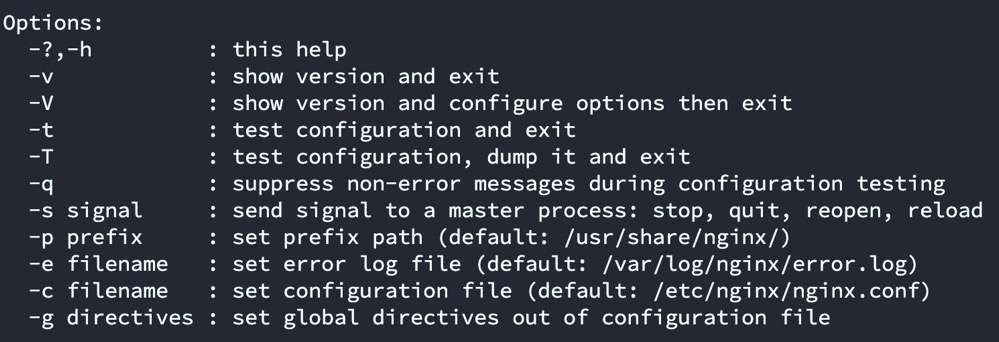
nginx# 启动nginx -v# 查看版本号nginx -V# 查看已安装模块nginx -t# 测试(常在修改配置文件后使用)nginx -h# 显示帮助文档ps -ef | grep nginx # 查看启动进程nginx -s stop# 强制停止nginx -s quit# 安全停止nginx -s reload# 重新加载配置(主进程不变,工作进程平滑重启)![在这里插入图片描述]()
-
配置文件架构
. 全局配置|-- event|-- http|-- server|-- location -
常用 include 全局配置引入其他配置文件:
include /usr/share/nginx/modules/*.conf; -
语法规范:所有语句均以分号
;结尾。 -
工作特点
存在主线程与工作进程之分,master进程指挥 worker 进程工作,worker进程数常与服务器核心数一致,可设为 auto 。
- master进程
- worker进程
> ps -ef|grep nginxroot 1627 1 0 03:10 ? 00:00:00 nginx: master process nginxnginx 1628 1627 0 03:10 ? 00:00:00 nginx: worker processnginx 1629 1627 0 03:10 ? 00:00:00 nginx: worker process# 全局配置worker_processes auto;![在这里插入图片描述]()
-
服务器权限控制
- nginx在服务上使用新建用户来进行权限控制,主进程除外由 root 创建。
- 所创建的用户在配置文件第一行,我们也可以采用 ps 来进行查看。
user nginx;ps -ef |grep nginxroot 954 1 nginx: master process /usr/sbin/nginxnginx 89135 954 nginx: worker process- 权限控制所产生的一些 bug :管理员上传到服务器的文件没有赋予 nginx 用户查看与管理的权限,导致无法访问(出错时查看错误日志error.log),授予权限 777 即可。
-
Host请求头诠释:
-
Host 是 HTTP/1.1 协议中唯一必须携带的请求头,如果缺失就会返回 400 状态码( curl 等操作中默认携带)。
-
作用:指明请求服务器的域名/IP地址和端口号。
-
组成:域名+端口号,如 test.com:1998 。
-
在 HTTP/2 以及 HTTP/3 中,以伪头
:authority代替。
-

-
常见服务器扩容方式:
- 垂直扩容:硬件设备物理扩容。
- 水平扩容:使用多台提供相同内容的服务器(集群化)。
- 分布式扩容:动静分离、服务分离。
三种扩容方式并没优劣之分,实际使用中依据情况而进行选择、优化。
-
动静分离思想:
- 静态资源放在 nginx 服务器。
- 动态请求由其他服务器处理(例如 Tomcat )。
-
其他注意点
- 修改静态 html 页面无需重启 nginx 。
root为默认的网站目录位置。- 存在网站默认访问目录,若不配置 root 路径,自动寻找当前安装位置的 html 目录。
-
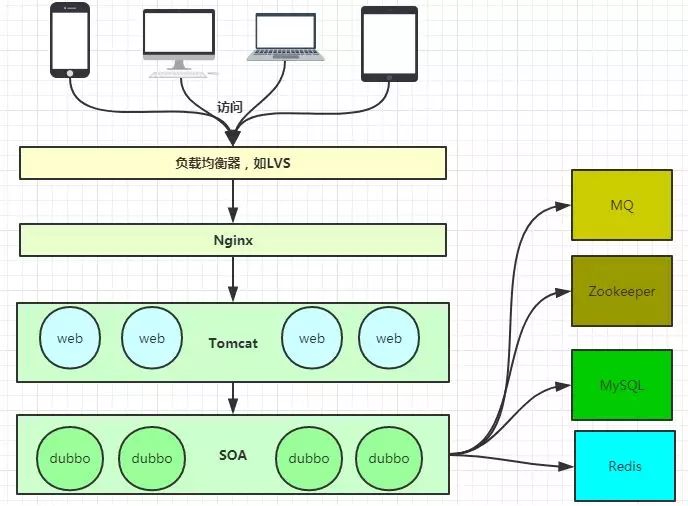
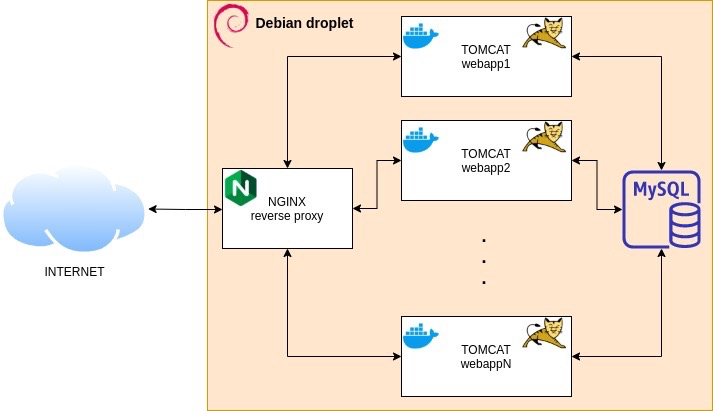
架构图:nginx + Tomcat 是一套流行的前后端分离架构。
![在这里插入图片描述]()
-
keepalived 说明:
keepalived 首先要求使用者申请一个公网 IP 地址,然后将域名绑定到该公网 IP( IP 实际上与机器的 mac 地址相绑定)。该公网 IP 在 keepalived 的加持下可以在多台机上的 mac 上“漂移”,从而实现高可用!
![]()

二、常用配置
一些简单的配置
1、listen
监听指定 ip 端口
listen 127.0.0.1:8000;listen 127.0.0.1;# 监听指定 ip 所有端口listen 8000;# 监听指定端口(常用)listen *:8000;# 通配符,同上server {# 监听多个端口 listen 443 ssl http2; listen [::]:443 ssl http2; listen 80; listen 81; server_name example.com ;}2、server_name
-
简介
- 配置域名
- 适用通配符
*(但只能用在开头结尾,不能用于中间) - 适用正则表达式(波浪线
~开头标识)
-
匹配优先级(高到低)
- 准确匹配
- 通配符匹配
- 正则表达式匹配
-
范例
server_name www.baidu.com;server_name *.baidu.com;server_name www.baidu.*;server_name ~^www\.\w+\.com$;# 正则表达式: www 开头,com 结尾server {listen 80;server_name www.thinkstu.com;}
3、location
-
支持多种匹配模式。
-
匹配优先级:
- 准确匹配:
= - 正则前缀匹配:
^~ - 前缀匹配:
/abc - 正则匹配:
~、~*(区分、不区分大小写) - 通用匹配:
/
(注意:当同级匹配冲突时,首先依据长度优先、其次依据匹配次序优先)
![]()
- 准确匹配:
-
匹配优先级规则:
- 判断精准命中
- 判断正则前缀匹配
- 判断普通命中。如果有多个命中,取最长的匹配
- 判断正则表达式,由上到下开始匹配**(一旦匹配成功1个,立即返回结果并结束,所以正则需要注意放置顺序)**。
- 判断通用匹配
/
-
范例
location / {}location /abc {}location =/abc {}location ~ /abc {}location ^~ /abc {} -
匿名location:
@符完成错误信息展示- 只提供给内部访问,拒绝外部用户访问;可返回字符串JSON说明或跳转至首页。
# 404状态码转为200,表示错误已处理并返回 @error 内容error_page 404 =200 @error;location @error{ return 503 "{'msg':'error'}";# 状态码冲突时,此处失效、error_page优先 # rewrite ^(/.*)$ http://$host/ permanent;}-
=[response]更改响应码。 -
编写格式:等号前有空格、后无空格。
-
**小tips:**精确匹配初始域名,加快解析速度
location = / {}

4、sendfile
-
简介:开启高效的文件传输模式,默认关闭(强烈建议开启!)。
sendfile on; -
为什么能加快文件传输效率?
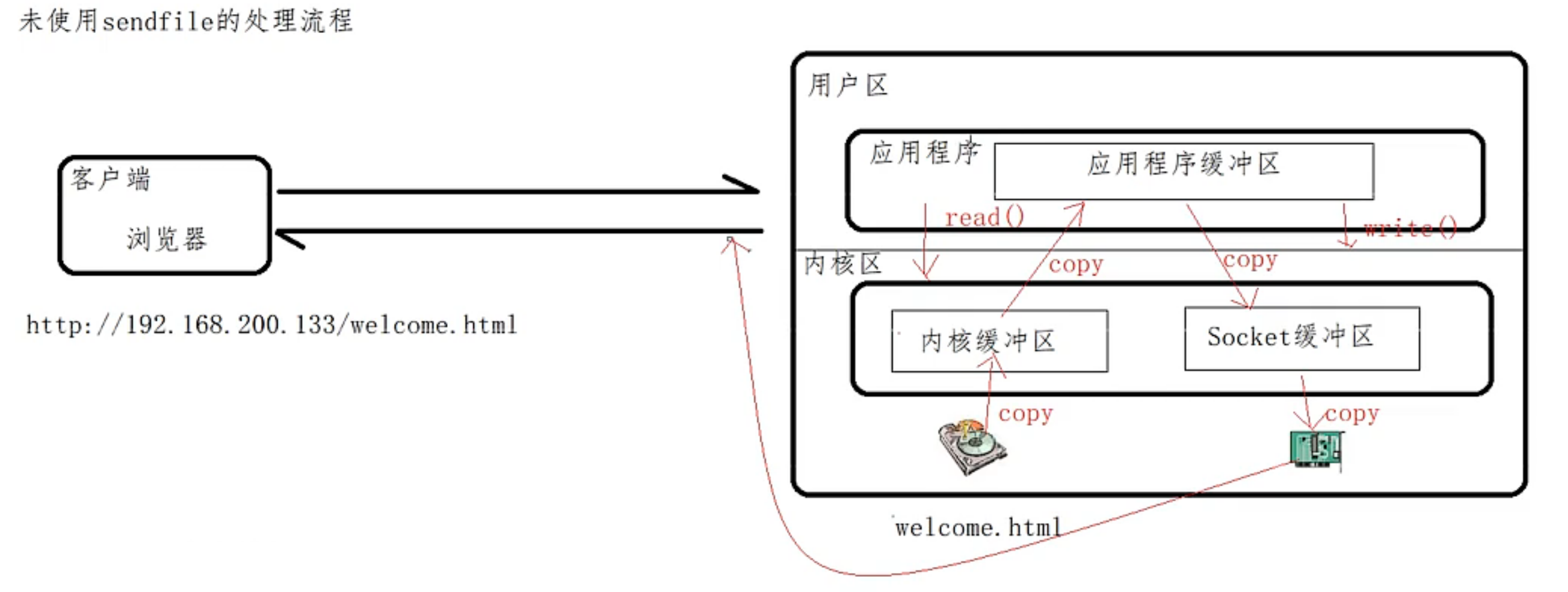
- 未使用 sendfile 之前:操作系统 4 次文件拷贝。
![image-20221018080231485]()
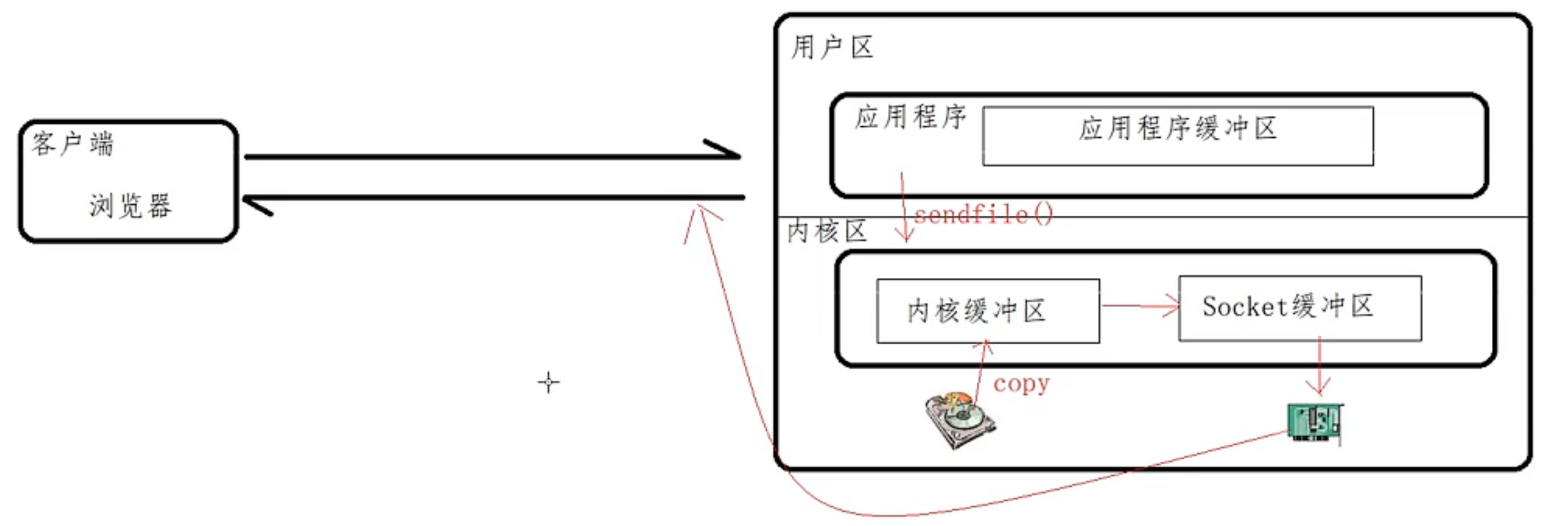
- 使用 sendfile 之后:2 次文件拷贝。
![image-20221018080327028]()
5、nodelay/push
必须开启 sendfile 才能使用 nodelay 与 nopush
-
tcp_nodelay:(默认开启)接收到请求后立即向服务器转发,速度快、资源利用率差。
-
tcp_nopush:接收到请求后缓冲再向服务器转发,速度慢、资源利用率高。
-
nopush 与 nodelay 共同使用:
-
Linux V2.5.9 允许,它能够极大提升效率。
-
在正常情况下使用 nopush 传输数据。
-
当碰上最后一次传输数据时,使用 nodelay 直接传送(避免缓冲区不满导致空转)。
> uname -aLinux VM-12-16-centos 3.10.0-1160.76.1.el7.x86_64 -
6、add_header
-
作用:添加 http 请求头。
-
表示形式:键值对,可选用 always 表示无论浏览器是否支持、总是配置。
add_header key value [always];add_header cache-control max-age=600;
7、set 变量
简介:nginx 中设置,使用变量时携带美元 $ 符号。
location /test { set $abc '123'; return 200 $abc;}8、if
-
简介:与编程 if 语句大致类似
-
语法规则:
- if 与括号之间加空格
- if 不能直接判断变量,必须借助“中间参数”
-
判断条件:
- 空、 0 表示 false。
- = 、 != 比较变量与字符串是否相等。
-f 和 !-f 用来判断是否存在文件-d 和 !-d 用来判断是否存在目录-e 和 !-e 用来判断是否存在文件或目录-x 和 !-x 用来判断文件是否可执行location /test { default_type text/plain; set $abc ''; if ($abc){return 403;} return 200;} -
对图片文件判断 并 设置过期时间(可用于反向代理配置中,优化逻辑)
if ($uri ~ ^.*\.(png|jpg|jpeg|gif)$){ expires 3600;} -
简单范例:
- 判断请求是否存在参数
- 判断请求文件是否存在:
-f - 判断是否包含指定字符:正则表达式
if ($args){}if (-f $request_filename){}if ($http_user_agent ~ Safari)# 正则if ($http_user_agent !~ Safari)# 取反if ($http_user_agent ~* Safari)# 不区分大小写
9、return
-
简介:
- return 中止整个程序,并向浏览器回送重定向响应。
- 浏览器发送两次请求
- 默认302临时重定向,可修改为 301 永久重定向。
-
简单使用
location /test { return https://thinkstu.com/; # return 302 https://thinkstu.com/; # return 301 https://thinkstu.com/;}![]()

10、keepalive
尚需大量实践
- 两种不同的类型
- TCP keepalive
- Http keealive
- nginx配置 keepalive:
# 时间为 0 表示关闭 keepalivekeepalicve_timeout 0s;keepalicve_timeout 65s;# 单个连接中可处理的请求数量# 表示不与某些浏览器建立长连接# 最长连接时间(超过强制关闭)keepalive_request 1000;keepalive_disable msie6;keepalive_time 1h;- 另外注意
send_timeout默认为 60s ,表示超过 60s 则关闭本次链接,所以它的值不能比 keepalive小。
send_timeout: 120s;- 反向代理与 keepalive:
- 设置最大支持保持数量。
- 默认 HTTP 版本号 1.0 ,我们需要 1.1(效率更高)。
- nginx 默认不支持长连接(为 close ),其会将客户端发送过来的 keepalive 请求覆盖,所以我们要清除它!
keepalive 100;keepalive_timeout 65s;keepalive_request 1000;proxy_http_version 1.1;proxy_set_header Connnection " ";三、常用操作
1、Gzip压缩
宝塔面板默认配置
-
简介
- 一种网页压缩技术,经过压缩后页面大小可以变为原来的 30% 甚至更小。
- 旧版本浏览器可能不支持(使用 gzip_disable 进行排除设置)
- 压缩配置在许多地方比较统一、可生成 conf 文件后使用 include 引入。
- 默认只对 text/html 进行压缩,其他自行设置(不建议设置成通配符
*,部分文件格式已压缩,二次压缩不仅费时费力、而且可能会适得其反)
-
常用配置
gzip on;# 开启(默认关闭)gzip_min_length 1k;# 最小压缩限值,建议 1KBgzip_comp_level 2;# 压缩等级1-9,动态设置考虑性能比gzip_min_length 1kb;# 最小压缩启动值gzip_buffers 4 16k;# 默认,无需配置gzip_http_version 1.1;# 默认 1.1,无需配置gzip_types text/plain application/javascript application/x-javascript text/javascript text/css application/xml text/html;# 压缩类型gzip_vary on;# header标识:告知浏览器使用 gzip 压缩gzip_disable "MSIE [1-6]\.";# 排除旧版本浏览器,支持正则表达式gzip_proxied expired no-cache no-store private auth;# 反向代理时设置-
gzip_proxied:作为反向代理时使用,表示是否对服务端返回的结果进行 gzip 压缩,参数表示浏览器作出相应表示时才启动。
gzip_proxied expired no-cache no-store private auth;![]()
-
-
gzip_static插件:
- 非原装、需手动编译。
- 功能:解决 gzip 与 sendfile 冲突问题。
- 原理:将动态压缩改为静态压缩。事先将文件压缩成
.gz,请求时返回压缩文件。

2、正则表达式
- 正则规则
.: 匹配除换行符以外的任意字符?: 重复0次或1次+: 重复1次或更多次*: 重复0次或更多次\d:匹配数字^: 匹配字符串的开始$: 匹配字符串的介绍{n}: 重复n次{n,}: 重复n次或更多次[c]: 匹配单个字符c[a-z]: 匹配a-z小写字母的任意一个():小括号之间匹配的内容,在后面依次序使用$1、$2等表示。
- nginx使用
~:严格正则,区分大小写~*:宽松正则,不区分大小写^~:前缀正则,如果匹配到则直接返回。!~:严格正则取反。!~*:宽松正则取反。
3、rewrite重写
-
简介:重写 url 使请求重定向,浏览器发送2次请求。
-
规则:
- 只能在 server、location 块与 if 语句中使用。
- 只对域名后边的除去传递参数的字符起作用。
# 对 https://a.com/1/11010.json?b=10 而言仅 /1/11010.json 可重写。 -
正则延伸:
^/:匹配全部^(/.*)$:匹配全部,后用$1承接。
-
重写标志位:标识重写方式
- redirect:302临时重定向
- permanent:301永久重定向
- last:行完毕后,重新在所有规则中匹配。
- break:执行完毕后,再次匹配本条规则。
示例:
![]()
-
常用变量:rewrite 使用 nginx 全局参数。
变量 说明 $request_uri 变量中存储了当前请求的URI,并且携带请求参数。 $args url请求参数 $uri 获取 uri $document_uri 功能和 $uri 一样 $host 服务器 server_name 值 $http_user_agent 浏览器代理信息 $document_root 请求对应的root目录,未设置则指向nginx自带html目录 $content_length Content-Length $content_type Content-Type $http_cookie cookie $limit_rate 存储服务器对网络连接速率的限制,默认0不限制。 $remote_addr 客户端 IP 地址 $remote_port 客户端与服务端建立连接的端口号(指客户端的) $remote_user 存储客户端的用户名,需要有认证模块才能获取 $scheme 访问协议,如http $server_addr 服务端的地址 $server_name 客户端请求到达的服务器的名称 $server_port 客户端请求到达服务器的端口号 $server_protocol 存储客户端请求协议的版本,如"HTTP/1.1" $request_body_file 存储发给后端服务器的本地文件资源的名称 $request_method 存储客户端的请求方式,比如"GET","POST"等 $request_filename 存储当前请求的资源文件的路径名 -
rewrite_log 日志:该指令用来指明是否开启 URL 重写日志输出功能,开启后将以 notice 级别向 error.log 日志中输出信息(配置相应 error 日志文件中的输出级别为 notice ,这将会输出大量日志记录),不建议使用该功能。
location /test { rewrite ^(/.*)$ https://$host$1 permanent; rewrite_log on;#开启 error_log /var/log/nginx/error.log notice;}

4、rewrite范例
-
强制HTTPS
if ($server_port !~ 443){ rewrite ^(/.*)$ https://$host$1 permanent;# 永久重定向} -
目录对换
/123456/xxxx -> /xxxx?id=123456rewrite ^/(\d+)/(.+)/ /$2?id=$1 last; -
指定浏览器对换指定路径
location / {if ( $http_user_agent ~* MSIE ){#ie浏览器使用此url资源rewrite ^(.*)$ /msie/$1 break;}if ( $http_user_agent ~* chrome ){#谷歌浏览器使用此url资源rewrite ^(.*)$ /chrome/$1 break;}} -
将
a.com/b跳转至b.a.comrewrite ^/b$ http://b.a.com permanent;rewrite ^/b/(.*)$ http://b.a.com/$1 permanent; -
a.com跳转到www.a.comif ($host = 'a.com' ) { rewrite ^/(.*)$ http://www.a.com/$1 permanent; } -
指定页面返回404
# /a/数字.htmlbrewrite ^/a/([0-9]+)\.html$ /404.html last;
5、跨域
-
简介:
- 跨域天生存在,跨域是因为浏览器的同源策略安全限制。
- nginx 解决跨域问题比较容易。
- 跨域是指利用 axios 等框架发送 get/post 等请求时会遇到的问题,而非 img 标签中 class="lazy" data-src 属性访问时会遇到的问题,class="lazy" data-src 中的只可能是防盗链!
- 当浏览器要发送跨域对象的时候,会自动携带 origin 属性值,未跨域时不发送 origin 。
-
理解参考文献:
-
CSRF理解:
- CSRF的作用是保护用户安全,属于一种安全模式,我们每个人都应该积极的使用携带此模式的浏览器。
- 部分浏览器不携带此功能(或许有人可以简单的开发一款),由此会造成损失!而该损失只会由使用的用户承担,那么试问谁会无聊的去使用这一款浏览器呢?Chrome也可以关闭此功能,不过这也就意味着关闭了一些安全模式(在Chrome中这的确被称为__安全模式)。
- 首先,当浏览器想要发送一个【跨域请求】时会先发送 一个OPTION 方法的预检请求。
- 服务器不支持 → 返回CSRF失败。
- 服务器支持该跨域请求,响应头中带有
Access-Control-Allow-Origin http://unmeta.cn;,通过。
- 然后浏览器检查本地存储,携带适配该请求域名以及文件路径的cookie,开始发送…
- 进而,服务器处理…,返回响应信息。
- 浏览器接收到响应…
-
利用请求头允许跨域:
即跨域会自动发送 Origin 请求头,服务器设置 Allow-Origin 链接与请求方式。
add_header Access-Control-Allow-Origin http://unmeta.cn;add_header Access-Control-Allow-Methods GET,POST;
6、防盗链
valid_referers 与 $invalid_referer 结合使用
-
简介:
- 防盗链天生不存在,人为后期添加。
- 服务器设置 referer 策略,客户端按照规则请求。
- Referer 字段实际上告诉了服务器,用户在访问当前资源之前的位置,可以用作一些限制。但是 referer 本身易于改变,普通用户也可以通过一些浏览器扩展修改相应值。
-
三种情景发送【referer】:
- 用户点击网页上的链接。
- 用户发送表单。
- 网页加载静态资源,比如加载图片、脚本、样式。
<img class="lazy" data-src="foo.jpg"><script class="lazy" data-src="foo.js"></script><link href="foo.css" rel="stylesheet"> -
不发送 referer 的两种原生方法:
-
rel:a、area 和 form 三个标签可以使用
rel="noreferrer"属性,一旦使用,该元素就不会发送Referer字段,但是 rel 局限只能单个设置。<a href="..." rel="noreferrer" target="_blank">点击按钮</a> -
Referrer Policy:更为强大的 w3c 标准,可应用 3 种场景、 8 种模式,常用2种模式(origin、no-referrer,发送与不发送)。
- HTTP 头信息(服务器负责解析)
- 标签(服务器负责解析)
- html属性(浏览器负责解析)
Referrer-policy: no-referrer<meta name="referrer" content="origin"><img class="lazy" data-src="..." referrerpolicy="origin">
-
-
nginx 图片防盗链【配置】
- none:如果 referer 为空,允许访问。
- blocked:如果请求头中的 referer 不为空,则允许不带“http://”、“https://”等协议头访问。
- 具体的域名或 IP 。
location ~ .*\.(css|js|png|jpg|jpeg)$ { root /usr/share/nginx/html/images; # 只允许空 referer 与 thinkstu.com 进行跳转访问 valid_referers none thinkstu.com; # 若为 true,即 “无效的referer” 成立,返回 403 Forbidden 标识 if ($invalid_referer){ return 403; }}- 防盗链并重写至默认图片(例如违规提示等)
if ($invalid_referer){ rewrite ^/ /2.jpg break;}
7、适配移动设备
适配移动端/桌面端设备
-
借助开源脚本:国外 detect mobile browsers
-
源码详解:
# 设置变量:mobile_rewrite = 非移动端set $mobile_rewrite do_not_perform;# 如果是移动端的话:mobile_rewrite = 移动端if ($http_user_agent ~* "是移动端") { set $mobile_rewrite perform;}# 判断是否为移动端,进行相应操作if ($mobile_rewrite = perform) { rewrite ^(/.*)$ http://mobile.网址.com/$1 redirect break; # 或者更改 root 目录 # root /html/mobile;}
8、获取 IP 地址
-
获取 IP 地址主要分为两种情况:
- nginx想要获得 IP 地址:查看 access.log 日志。
- 后端服务器想要获得 IP 地址:nginx 设置全新请求头将 IP 地址传输至后端。
-
为什么后端服务器不能像以往一样直接获取用户 IP 地址?
因为后端服务器接收到的“网际层面IP地址”永远只能是 nginx 服务器的 IP 地址。
-
nginx设置IP转发头:
proxy_set_header x_forwarded_for $remote_addr; -
如何防止前端伪造 IP 请求头?
只要我们在配置中设置了 x_forwarded_for ,就会自动覆盖掉用户写的 x_forwarded_for ,以此来达到目的。
# 覆盖用户私自声明的 x_forwarded_forproxy_set_header x_forwarded_for $remote_addr; -
如何避免多级 nginx 链重写 x_forwarded_for 请求头?
- 第一种方法:第一个 nginx 服务器重写 x_forwarded_for ,后面不重写。
- 第二种方法:所有nginx服务器均重写不一样的请求头。
9、乱码修复
server 与 location 中均可配置。
server {# ... charset utf-8;}10、简易下载站点
-
简介:将服务器上的某目录开放访问,点击下载。
-
4个配置:
- autoindex:为 on 时,访问目录中会生成目录列表,点击下载。
- autoindex_exact_size:是否精确显示。
- on:无单位、字节显示(默认)。
- off:有单位,人性化阅读方式。
- autoindex_format:可选 html/json/jsonp/xml,默认 html(点击下载)。
- autoindex_localtime:
- on:推荐。显示文件被加入到服务器时时间。
- off:默认。显示文件 GMT 时间。
autoindex on;autoindex_exact_size off;autoindex_format html;autoindex_localtime on; -
简易下载站
# 地址最后带有斜杆,表示访问目录location =/test/ { autoindex on; autoindex_exact_size off; autoindex_format html; autoindex_localtime on;}# 正则匹配,声明强制下载location ~* ^/test/.*$ { add_header Content-Disposition "attachment;";}![]()

11、禁止访问
返回 403 Forbidden 状态码
即可以使用 deny 实现,也可以使用 allow 实现
-
简介:
- 禁止特定 IP 访问。
- 禁止访问特定文件
- 一般推荐新建配置文件
blocksip.conf来实现。
-
简单配置(allow相同)
deny all;deny 127.0.0.1;deny 123.1.1.0/24; # 123.1.1.1 ~ 123.1.1.254![]()
-
叠加 limit_except语法进行配置:
limit_except GET { allow 192.168.1.0/32; deny all;}- location块中使用
- method 参数可以是 GET、HEAD、POST、PUT、DELETE 等。
- 允许 GET 也将使 HEAD 被允许。
-
范例:
- 禁止访问指定后缀文件
- 禁止访问指定目录(正则前缀形式)
location ~/\.ht {deny all;# 善用 deny all;}location ~ ^/(cron|templates)/ {deny all;}

12、root目录
通过更改 root 根目录实现:重定向资源访问路径
location ~* \.(gif|jpg|jpeg|png|css|js|ico)$ { root /webroot/res/;}13、 压测工具
Apache压测工具: httpd-tools
yum install httpd-toolsab -n 1000 -c 30 https://baidu.com/- -n:压测次数
- -c:并发量
- 链接:最后要以
/结尾,否则报错。
14、简易登录验证
-
简介:小型化认证工具,明文传输、易受攻击。
-
使用流程:
- httpd-tools生成验证文件
- nginx配置
-
httpd-tools生成验证文件:
-
yum 安装 httpd-tools ,使用 htpasswd 指令生成账号密码。
-
nginx 配置认证,可以位于 server、location 等。
-
选择 nginx 用户可以访问的目录,生成账号密码文件
yum install httpd-tools# 创建一个新文件记录用户(回车输入密码)htpasswd -c /usr/local/nginx/conf/htpasswd username # 追加一个用户htpasswd -b /usr/local/nginx/conf/htpasswd username password# 删除一个用户htpasswd -D /usr/local/nginx/conf/htpasswd username# 验证一个用户的账号密码htpasswd -v /usr/local/nginx/conf/htpasswd username![]()
-
-
nginx配置:
- 设置备注信息,备注信息是否显示与浏览器版本有关;
- 备注信息可以为空但是必须要设置,否则无法开启验证模式。
auth_basic "请输入账号密码";auth_basic_user_file /usr/share/nginx/users/login_01;![]()


15、快速返回
利用 return 语句
-
简介:nginx 可以代替实际的服务器,快速返回某些字符串(JSON格式等)。
-
实现:server、location中均可使用。
location / {default_type text/JSON;charset utf-8;return 200 "{'msg':'ok'}";}
16、错误页面
error_page
针对错误页面的处理,我们拥有2种策略:
- 返回404页面
- 重定向至其他页面(例如首页)
- 返回一些数据信息(例如JSON)
error_page 404 =302 http://a.com;error_page 404 =200 /index.html;# 这里虽然标识为200,但是依旧会返回302进行重定向error_page 404 =200 '{'code':'200','msg':'error'}';17、宝塔说明
-
简介:
- 宝塔安装的 nginx 资源主要分布在宝塔目录 www 下。
- 命名方式为:bt-nginx版本号,如bt-nginx122。
-
架构:
- 全局配置:
/www/server/nginx/conf/nginx.conf - 项目分别配置:
/www/server/panel/vhost/nginx/- panel:面板
- vhost:virtual host 虚拟主机
![]()
- 全局配置:
-
宝塔 nginx 历史配置文件目录
/www/backup/file_history/www/server/panel/vhost/nginx/java_emptyForward-0.conf

18、隐藏版本号
nginx 服务器在返回的响应头中包含版本信息,而某些版本可能存在漏洞,为防止其他人利用版本漏洞进行攻击,我们可以选择不返回版本信息。
server_tokens off;
19、浏览器接收类型
-
简介:
- 其实就是定义服务器的返回数据类型,即浏览器接收到的数据类型。
- 可以在 http 或 server、location 中配置。
Content-Type: text/html; charset=utf-8 -
优先级(从上至下):
- 响应头设置
Content-Disposition或Content-Type - 设置 nginx 映射文件
mime.types - 设置nginx 配置属性
default_type
- 响应头设置
-
简单实现:
- 当未能识别文件类型时,默认下载
- 强制下载(响应头设置)
- 普通文本类型(响应头设置)
location / {default_type application/octet-stream;}location / {add_header Content-Disposition "attachment;"; # add_header Content-Type 'text/plain; charset=utf-8';;}
20、模块编译
由于一些环境因素,后续我可能还会回到这
-
简介:
- 必须要掌握的技能。
- 编译安装新模块的时候,必须要把旧的模块参数带上,否则原配置会被覆盖。
-
流程
- 重新编译 nginx 模块
- 将新模块(新生成的 objs 目录)覆盖旧模块。
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module --with-http_realip_module --with-http_image_filter_module --without-http_rewrite_modulemakecp new__ old__![]()

21、Range
断点续传
-
简介:nginx 支持 Range 请求头,可实现断点续传,默认开启。
-
Range请求头格式(单位默认字节):
Range: bytes=0-10 -
文件下载业务关闭 Range 的方法:
- 将返回文件格式更改为
octet-stream - 流形式不会显示有终点等信息,所以“下载永无终点”,除非服务器自己暂停传输。
add_header Content-type application/octet-stream; - 将返回文件格式更改为
-
反向代理时关闭 Range
# 覆盖用户 range 请求头,范围超过原文件字节大小即可。# accept-ranges其实没用,放在这里只是为了提示用户。add_header Accept-Ranges none;proxy_set_header range 'bytes=0-10000000000'; -
转发请求头至Tomcat:正常情况下无需配置,但发现 range 未生效时可配置。
proxy_set_header Range $http_range;
四、缓存
web缓存作用于浏览器
代理缓存作用于代理服务器
1、web缓存
深入理解浏览器缓存:传送门
-
简介:
- nginx 实现 web 缓存主要依赖浏览器缓存,数据缓存在客户端。
- 304状态码表示使用缓存。
-
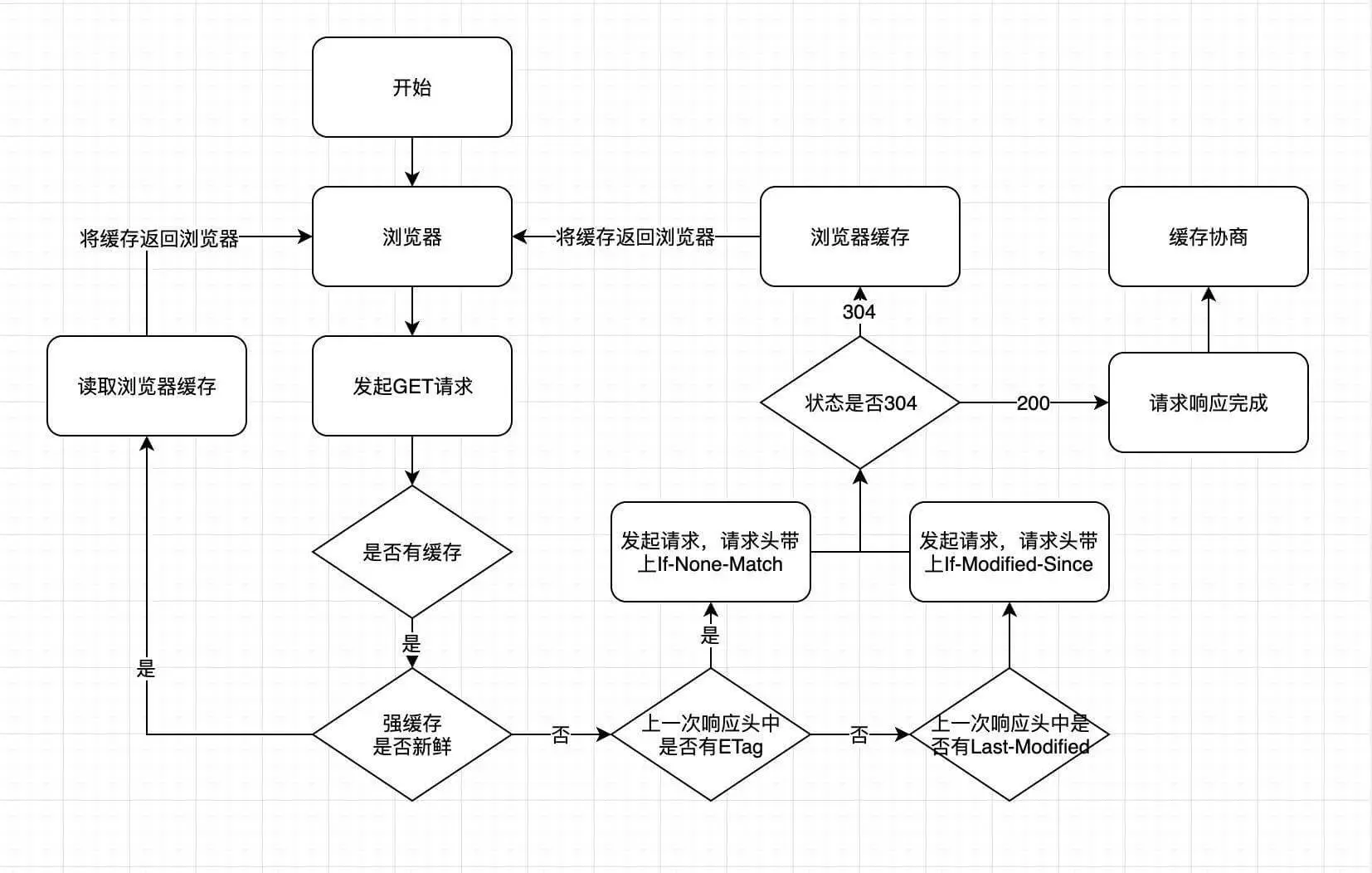
2种缓存类型
- 强缓存:直接获取本地缓存,不向服务器发送任何信息(expires与Cache-Control)。
- 弱缓存:先向服务器发送请求确认缓存是否有效,有效则用、无则请求更新(last-modified与eTag)
-
浏览器缓存响应图
![img]()
-
强缓存优于弱缓存!存在强缓存则弱缓存不会进行!
-
注意:
- 初次在浏览器地址栏中直接回车,相当于先访问内存,看内存中有无缓存数据,有则直接使用。
- 后面再次回车,都相当于刷新当前页面。
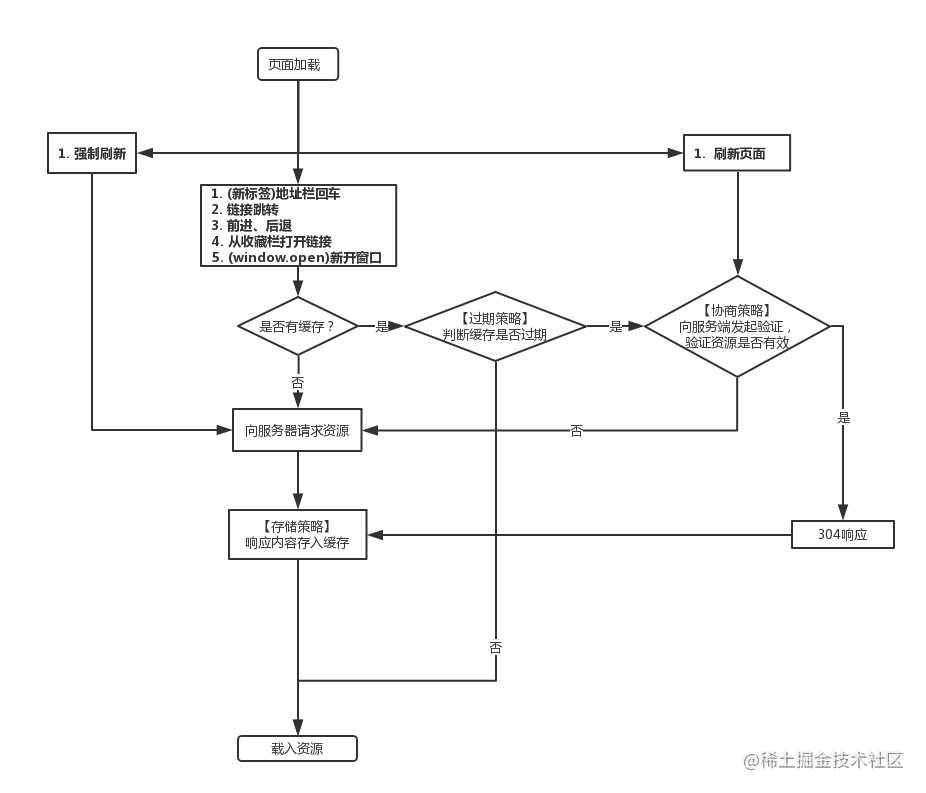
此外,这里提一个概念,webkit 资源分为主资源和派生资源。主资源是地址栏输入的 URL 请求返回的资源,派生资源是主资源中所引用的 JS、CSS、图片等资源。
在 Chrome 中,主资源通常会首先发起一个网络请求试探是否过期,派生资源则会先在本地判断资源是否过期。强缓存生效时的区别在于新标签打开为
from disk cache,而当前页刷新派生资源是from memory cache。
![不同访问方式下的浏览器资源判断]()
-
-
Cache-Control请求头参数
指令 说明 must-revalidate 可缓存但必须再向服务器进行确认 no-cache 缓存前必须确认其有效性 no-store 不缓存任何请求 no-transform 代理不可更改媒体类型 public 浏览器、代理服务器均可缓存 private 浏览器可以缓存、代理服务器不可缓存(默认取值) proxy-revalidate 要求中间缓存服务器对缓存的响应有效性再进行确认 max-age=[秒] 缓存有效期 s-maxage=[秒] 公共缓存服务器响应的最大 Age 值 -
expires 与 Cache-Control: max-age=1000 区别:
- expires:http 1.0 协议,兼容老系统。
- max-age:最新标准。如果设置了此,则会忽略 expires。
Expires 缺点: 返回的到期时间是服务器端的时间。存在问题:如果客户端的时间与服务器的时间相差很大,那么误差就很大,所以在HTTP 1.1版开始,使用Cache-Control: max-age=秒替代(相对时间)。
-
实例:缓存 js/css/image 文件
location ~.*\.(css|js|png|jpg|jpeg)$ { expires 86400s;} -
注意:
分布式系统里多台机器间文件的last-modified必须保持一致,以免负载均衡到不同机器导致比对失败,**分布式系统尽量关闭掉Etag(每台机器生成的Etag都会不一样)。**但是 if-modified只能精确到秒级(如果每秒进行了多次修改则存在隐患),而 Etag 能每次都能判断。
http { etag off;} -
只有返回的资源带有
Last-Modified标识,而浏览器再次请求该资源时才会自动带上If-Modified-Since请求头。另外If-Modified-Since只能作用于 GET、HEAD 请求。 -
什么情况下服务器会发送last-modified ?
- 静态资源自动发送。
- 动态资源(例如API接口类)不发送。
-
禁用 last-modified的两种方法:
- 覆盖请求头(置空表示不发送):
add_header Last_modified "";- 服务器关闭 if-modified-since 功能:即不对 if-modified-since 进行响应,直接进行 200 数据的返回。
if_modified_since off;
2、代理缓存
注意,应避免给
XHR类请求设置代理缓存
-
示意图:
![]()
-
原理阐释:
- nginx将接收到的请求 url 经过 md5 加密生成密文 key。
- 用 key 来充当缓存的键,值即内容。
-
缓存目录思想:
创建 1 个缓存总目录,然后利用参数值令 nginx 自行创建子缓存目录。
-
先打开
proxy_buffering# 默认已开启,但这里要防止被其他配置关闭(否则不生效也不报错)proxy_buffering on; -
总体配置思想
- proxy_cache,开启代理缓存(默认为空值、关闭)。
- proxy_cache_path,配置缓存区大小,缓存路径、有效时间等。
- levels:缓存目录层级
- keys_zone:缓存 key 区的名称及大小,1m 大概能存储 8000 个 key 值。
- inactive:缓存有效时间,如 1d 表示一天后就会删除。
- max_size:最大总缓存空间
proxy_cache_path /usr/local/nginx_cache levels=2:1 keys_zone=mycache:10m inactive=1d max_size=1g;proxy_cache mycache;![]()
-
额外配置
- proxy_cache_key:web 缓存的key值,存在如下默认值(3部分加起来就是完整的 url)。
$scheme$proxy_host$request_uri- proxy_cache_min_uses:资源被访问多少次之后才开启缓存,默认值 1 。
- proxy_cache_valid:可以针对不同的状态码设置不同的缓存时间。
proxy_cache_valid 200 302 10m;proxy_cache_valid 404 1m;# 为 404 页面缓存 1 分钟proxy_cache_valid any 1m;- proxy_cache_methods:设置可以缓存的请求方式,默认 Get/Head 。
proxy_cache_methods GET|POST|PUT|DELETE; -
清除缓存:
rm -rf删除:但存在不便,适合一下子情况所有缓存的情况。- ngx_cache_purge:第三方插件需安装,库较老、不符合现今情况。
-
不缓存与不使用缓存
- 出发点:不是所有的数据都需要 nginx 服务器都需要缓存,有时候可能会适得其反。
- 两者含义并不一样:
- proxy_no_cache:设置在什么情况下不缓存数据。
- proxy_cache_bypass:设置在什么情况下不使用缓存的数据。
- 两者配置形式一样:或运算,只要在配置条件中满足存在任何一个条件即生效。
- $cookie_xxx:当 Cookie 中包含该 key 时生效。
- $arg_xxx:当请求参数 arg 中包含该 key 时生效。
proxy_no_cache $cookie_nocache $arg_nocache $arg_leaf;proxy_cache_bypass $cookie_nocache $arg_nocache $arg_leaf; -
浏览器查看是否击中缓存
![]()
- HIT:击中
- MISS:未击中。



五、爬虫过滤
初级爬虫过滤
高级爬虫过滤
1、拦截特定请求
初级爬虫过滤
-
简介:
- 利用正则表达式对 agent 进行辨别和拦截。
- 如果我使用了 okhttp ,则不能禁止 okhttp ,只能禁别的,因为我还要用!
-
简单实现:禁止某些爬虫与空 agent 访问。
location / { root /usr/share/nginx/html; index index.html index.htm index.php; if ($http_user_agent ~* "python|java|curl|wget|postman|apipost|httpclient|Apifox|^$"){ return 503; }} -
curl模拟各种爬虫
curl -A '' test.comcurl -I -A 'okhttp' test.com# -I 只返回状态码与响应头,不返回 body -
禁止搜索引擎爬虫:当我们不想被搜索引擎爬虫干扰时使用,下面参数只列出了部分搜索引擎爬虫。
if ($http_user_agent ~ "FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) { return 503;}
2、限流限速
高级爬虫过滤
-
简介:
-
nginx默认不限流。
-
限制请求速率:limit_req_zone
-
限制并发数:limit_conn_zone
-
限制网速:limit_rate
-
-
原理:(传送门)
- 漏桶算法:永远匀速处理请求,超出则抛弃相应请求并返回503。
- 令牌桶算法:当桶里储备有物资时,可处理大量突发请求;当物资被消耗殆尽时,匀速处理请求,除非桶里再次缓存。(相当于漏桶算法的强化版)
-
限制请求速率 ngx_http_limit_req_module
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=1r/s;server { location / { limit_req zone=mylimit burst=10 nodelay; }}-
**注意:**limit_req_zone 只是设置限流参数,如果要生效的话,必须和 limit_req 配合使用。
-
$binary_remote_addr:使用二进制 IP 存储辨别客户端(压缩内存占用量)。
-
zone:myLimit:10m 表示一个大小为10M,名字为 myLimit 的内存区域,1M 能存储16000个 IP 地址的访问信息。
-
rate:rate=1r/s 表示每秒最多处理 1 个请求。实际上 nginx 以毫秒为粒度追踪请求,所以是每 1000 毫秒 1 个请求。
-
burst:在超过设定的访问速率后缓存的请求数(单独设置还是要等待、依次进行)。
-
nodelay:表示不延迟。设置 no_delay 后,第一个到达的请求和队列中的请求会立即进行处理,不会出现等待的请求。通常与 burst 搭配使用提高突发请求响应。
-
-
限制并发数 ngx_http_limit_conn_module
limit_conn_zone $binary_remote_addr zone=perip:10m;limit_conn_zone $server_name zone=perserver:10m;limit_req_status 510;# 失败时默认返回503,可自定义400-599server { location / { limit_conn perserver 50;limit_conn perip 5; }}- 注意:并非所有的连接都被计数,只有在服务器处理了请求并且已经读取了整个请求头时,连接才被计数。
- limit_conn perip 10:key 是 $binary_remote_addr,表示限制单个IP同时最多能持有10个连接。
- limit_conn perserver 100: key 是 $server_name,表示虚拟主机(server) 同时能处理并发连接的总数为100。
-
限制网速 ngx_http_core_module
- limit_rate:限速,默认单位为字节 Byte。
- 案例:20MB 之前不限速,之后限速为 100KB/s 。
limit_rate_after 20m;limit_rate 100k; -
设置访问白名单:白名单不限流。
limit_req_zone $limit_key zone=mylimit:10m rate=10r/s;geo $limit { default 1; 10.0.0.0/8 0; 192.168.0.0/24 0; 172.20.0.35 0;}map $limit $limit_key { 0 ""; 1 $binary_remote_addr;}
3、爬虫炸弹
-
简介
- 利用 gzip ,将 10GB 文件压缩至 1MB。
- 当非法客户端请求时返回,使其解析并消耗资源。
-
实现过程:
- Linux
dd指令制作压缩前大小为 10GB 的文件,置入/html目录。 - nginx 配置 location 信息。
dd if=/dev/zero bs=1M count=10240 | gzip > 10Glocation / {# 如果是非法请求 if ($http_user_agent ~* "python|apipost|postman|Apifox|^$"){ rewrite ^(/.*)$ /10G last; }}location =/10G { gzip off; add_header Content-Type 'text/plain'; add_header Cache-Control no-store; add_header Content-Encoding gzip;} - Linux
六、代理
1、正向代理
代理用户,本质为请求转发
实现:
- nginx服务器开启正向代理功能,监听某一端口、并对发送至该端口的所有请求转发。
- 用户将所有请求都转发至nginx服务器(需配置用户本机的代理规则),由nginx代理用户对其他网站进行访问。
server{listen 80;location / {proxy_pass http://$host$request_uri;}}2、反向代理
upstream + proxy_pass
-
简介:
- 反向代理常作负载均衡,在某些时候两者的含义是模糊的。
-
负载均衡的作用:
- 提高并发处理性能
- 实现故障转移
- 增强可扩展性(灵活)
- 过滤非法请求
-
3种常见负载均衡策略
-
用户手动选择:牺牲体验。
![]()
-
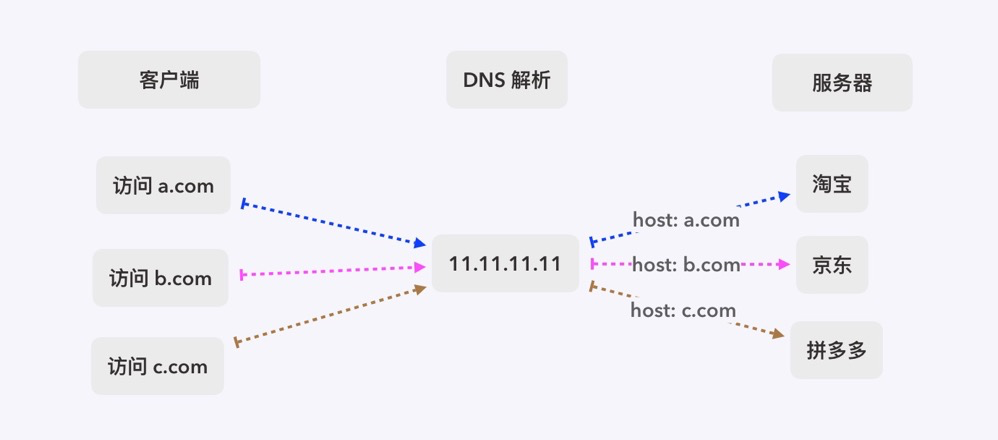
DNS轮询:利用单一域名可同时解析多个 ip 的特点,但是弊端也很明显,灵活性低、可靠性低、分配不均衡。
![]()
-
nginx反向代理:解决以上问题。
-
-
【简单配置】
- upstream(上游):定义一组可使用的服务器。
- server:此处的 server 即 upstream 下的服务器地址、端口配置。
# 定义 upstream ,命名为 backendupstream backend{ server 127.0.0.1:8081 weight=1; server 127.0.0.1:8082 weight=2; server 127.0.0.1:8083 weight=10;}location / { proxy_pass http://backend; default_type text/plain;}server{ listen 8081; # listen 8082; # listen 8083; server_name localhost; default_type text/plain;} -
【进阶配置】
反向代理叙述:所有带有 proxy 开头的指令全部都是反向代理配置。
- proxy_set_header:在将请求发送给后端服务器之前,更改请求头信息。
- proxy_connect_timeout:配置Nginx与后端代理服务器尝试建立连接的超时时间。
- proxy_read_timeout:配置Nginx向后端服务器组发出read请求后,等待相应的超时时间。
- proxy_send_timeout:配置Nginx向后端服务器组发出write请求后,等待相应的超时时间。
- proxy_redirect:用于修改后端服务器返回的响应头中的Location和Refresh。
![]()
-
在作反向代理时,
location路径末尾加或不加斜线/d的区别:location /test/ { proxy_pass http://127.0.0.1/;# proxy_pass http://127.0.0.1;}假设想请求 abc.html,真实访问路径如下:
-
加:
http://127.0.0.1/abc.html -
不加:
http://127.0.0.1/test/abc.html
总结:如果我不加的话,他就会替我加!(包括location路径中的一切)
-
-
负载均衡状态
用于标注服务器状况
状态 概述 down 当前的 server 暂不参与负载均衡 backup 预留的备份服务器 max_fails 允许请求失败的次数 fail_timeout 失败之后 server 暂停接受请求的时间 max_conns 限制的最大接收连接数(默认 0 ,即不受限制) -
backup:原可用的所有服务都不可用时才会生效。
-
max_fails + fail_timeout:两者通常结合使用。
-
范例:当该服务器在 10s 内出现 3 次失败后,暂时该服务器在下一个时间段 10s 内的使用( fail_timeout 描述的是时间段)。
- max_fails 默认值为 1 ,fail_timeout默认值为 10 。
- 在原始情况下,404 不被认为是失败的访问,可自定义配置。
server 127.0.0.1:8081 max_fails=3 fail_timeout=10s;proxy_next_upstream error timeout invalid_header http_500 http_503 http_404; -
-
负载均衡策略
算法名称 说明 轮询 默认 weigth 权重,默认 1 ip_hash 依据ip分配 url_hash 依据URL分配 cookie_hash 依据 Cookie 内的某些字段分配,如 session least_conn 最少连接优先选择 fair 依据响应时间(第三方模块) upstream backend{ip_hash;least_conn;hash $request_uri;# 基于 Java 中的 Java Session Idhash $cookie_JSESSIONID server 127.0.0.1:8081 weigth=1; server 127.0.0.1:8082; server 127.0.0.1:8083;}



3、反向代理实战
-
对特定资源实现负载均衡
upstream imagebackend{ server 127.0.0.1:8081; server 127.0.0.1:8082;}upstream videobackend{ server 127.0.0.1:8083; server 127.0.0.1:8084;}server{ listen 80; server_name localhost; # image locatio /image/ { proxy_pass http://imagebackend; } # video locatio /video/ { proxy_pass http://videobackend; }} -
对不同域名实现负载均衡
upstream aaa{ server 127.0.0.1:8081; server 127.0.0.1:8082;}upstream bbb{ server 127.0.0.1:8083; server 127.0.0.1:8084;}server{ listen 80; server_name one.com; locatio / { proxy_pass http://aaa; }}server{ listen 80; server_name two.com; locatio / { proxy_pass http://bbb; }}
七、Lua
lua 是一门简洁、轻量、可扩展的脚本语言,其采用 C 语言编写。
1、入门
-
简介:Lua的设计目的是为了嵌入到其他应用程序,从而为其他应用程序提供灵活的扩展和定制功能。
-
安装:绝大部分 Linux 系统已默认安装 Lua 。
yum install -y lua -
2种执行模式:
- 交互式:命令行回车,一问一答,ctrl + C 退出。
- 脚本式:编写脚本文件,统一执行。
-
交互式
lua![]()
-
脚本式
- 带 lua
# 编辑、执行vim lua_01lua lua_01- 不带 lua:文件中加上执行头信息:#! /usr/bin/lua ,后再赋于执行权限、执行。
vim lua_01#! /usr/bin/luaprint("Hello Lua")chmod 777 lua_01./lua_01![]()
-
语法细则:分号
;加不加都行 -
注释
- 单行注释
--注释内容- 多行注释
--[[注释内容--]]- 取消多行注释:相当于两个单行注释
---[[注释失效--]] -
变量定义:
- 命名规则与其他语言规则类似,例如 Java。
- 弱定义、弱类型 -> 无需提前定义直接使用,类型也不用声明。
nil表示未赋值(nil /nɪl/:零、空)。- 全局变量:默认即全局变量
- 局部变量:需加关键字 local 声明,否则会被当成全局变量。
- 注意:Lua内部全局变量的命名规则为 -> 以下划线开头连接大写字母的变量名。所以一般约定我们不这么定义变量,以免和 Lua 冲突。
> a=10> print(a)10> local b=20> print(b)nil> local c=30; print(c)30 -
关键字
![]()
-
部分运算规则:
10^2 --> 10010==10 --> true10~=10--> falseandornot --> 逻辑非.. --> 字符串连接,例:"aa".."bb",输出 aabb#--> 返回字符串长度,例:#"hello",输出 5 -
8种数据类型
nil# 空、无效值booleannumber# 数值,包含 integer 整数、float 双精度(这与其他语言不同)stringfunction# 函数table# 表thread# 线程userdata# 用户数据- 可以使用
type()来检测数据类型
> print(type(123))number注意:
-
只要将变量名赋值为 nil,那么垃圾回收就会释放该变量所占用的内存。
-
在boolean中,lua 只会将 false 与 nil 视为假,其余均为真!
-
不管是 integer 或者 float ,
type()返回的均为 number。
字符串声明:
- 单行声明:单引号或者双引号。
- 多行声明:
[[ sample ]]
> a="123"> b="456"> c=[[>> 7>> 8>> 9>> ]] - 可以使用
-
table数据类型:lua 中最主要和最为强大的数据结构,可以以一种简单的方式表达数组、集合、记录等内容。**注意:**数组下标从 1 开始。
> a={}> b={"A","B","C"}> print(b[1])A> arr["A"]=10> arr["B"]=20> arr[1]-- 当为以上的方式书写时,不能用序号获取nil> arr["A"]10> arr = {"A",X=10,"B",Y=20}> arr[1]A> arr[2]-- 注意此时的序号关系B> arr.X-- 注意这种书写方式10 -
函数
- 格式
function 函数名(参数)-- 具体内容end- 范例
> function add(n,m)>> print(n+m)>> end> add(1,2)3> function add(...)>> a,b,c=...>> return a,b,c>> end> q,w,e=add(1,2,3)> print(q,w,e)1 2 3 -
if语句:end作终结符
if thenelseif thenelse-- precedureend- 范例
> function testif(age)>> if age <= 18 then>> return "未成年">> elseif age <= 45 then>> return "中年人">> else >> return "老年人">> end>> end> print(testif(20))中年人 -
while与repeat:end、until 作终结符,不支持 a++ 类语法。
> function testwhile()>> i=10>> while i<20 do>> print(i)>> i=i+1>> end>> end> function testrepeat()>> i=10>> repeat>> print(i)>> i=i-1>> until i<1>> end



2、openResty
openResty = nginx + lua
-
简介: nginx 直接操作缓存,避免将请求转发至真正后端(少了一层)。
-
centos安装
sudo yum-config-manager --add-repo https://openresty.org/yum/cn/centos/OpenResty.reposudo yum install openresty -
组件图
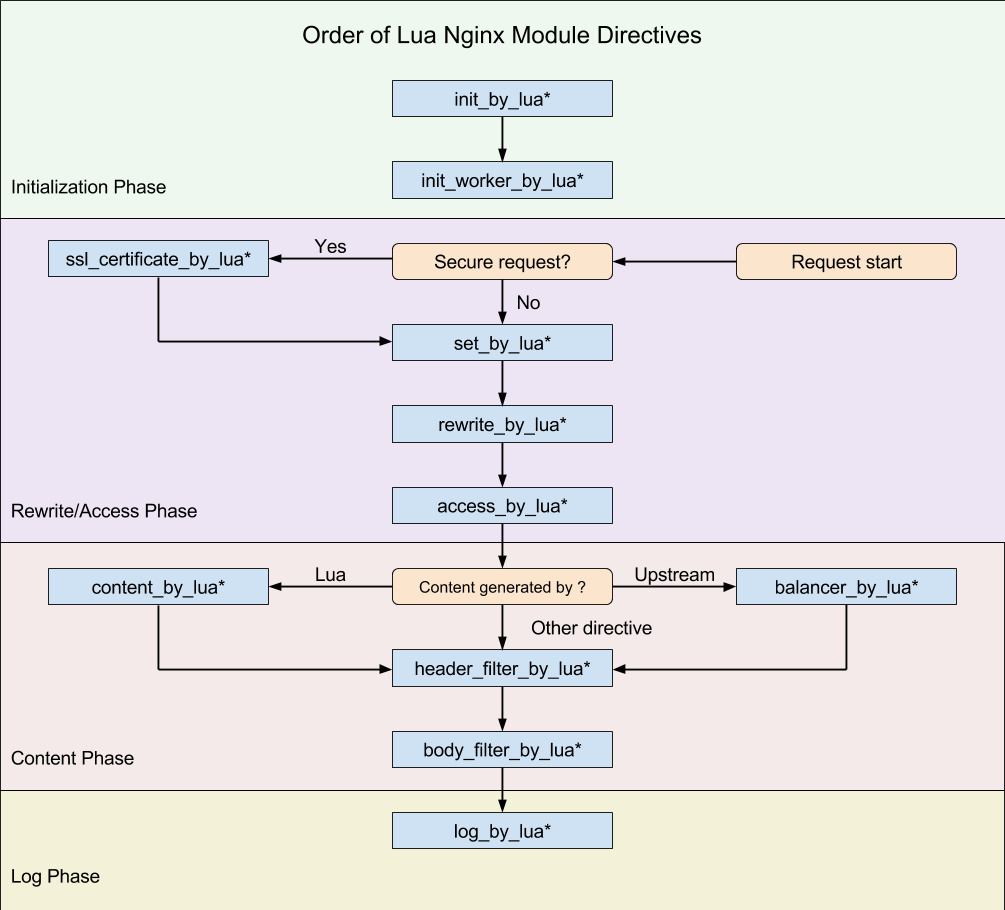
来源地址:https://blog.csdn.net/qq_35760825/article/details/128251533
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341


















