

【python】爬取豆瓣电影排行榜Top250存储到Excel文件中【附源码】


英杰社区![icon-default.png?t=N7T8]() https://bbs.csdn.net/topics/617804998
https://bbs.csdn.net/topics/617804998
一、背景
近年来,Python在数据爬取和处理方面的应用越来越广泛。本文将介绍一个基于Python的爬虫程
序,用于抓取豆瓣电影Top250的相关信息,并将其保存为Excel文件。
程序包含以下几个部分:
导入模块:程序导入了 BeautifulSoup、re、urllib.request、urllib.error、xlwt等模块。
定义函数:
- geturl(url):接收一个URL参数,返回该URL页面内容。
- getdata(baseurl):接收一个基础URL参数,遍历每一页的URL,获取电影信息数据,以列表形式返回。
- savedata(datalist,savepath):接收电影信息数据和保存路径参数,将数据保存到Excel文件中。
二、导入必要的模块:
代码首先导入了需要使用的模块:requests、lxml和csv。
import requests
from lxml import etree
import csv如果出现模块报错
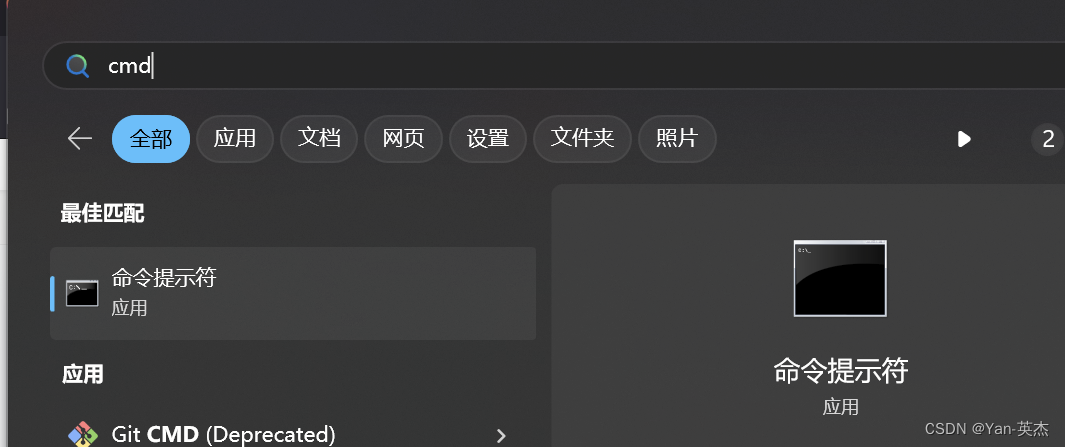
进入控制台输入:建议使用国内镜像源
pip install 模块名称 -i https://mirrors.aliyun.com/pypi/simple
我大致罗列了以下几种国内镜像源:
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple
阿里云
https://mirrors.aliyun.com/pypi/simple/
豆瓣
https://pypi.douban.com/simple/
百度云
https://mirror.baidu.com/pypi/simple/
中科大
https://pypi.mirrors.ustc.edu.cn/simple/
华为云
https://mirrors.huaweicloud.com/repository/pypi/simple/
腾讯云
https://mirrors.cloud.tencent.com/pypi/simple/
三、定义了函数来解析每个电影的信息:
设置了请求头部信息,以模拟浏览器的请求,函数返回响应数据的JSON格式内容。
def getSource(url):
# 反爬 填写headers请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
response = requests.get(url, headers=headers)
# 防止出现乱码
response.encoding = 'utf-8'
# print(response.text)
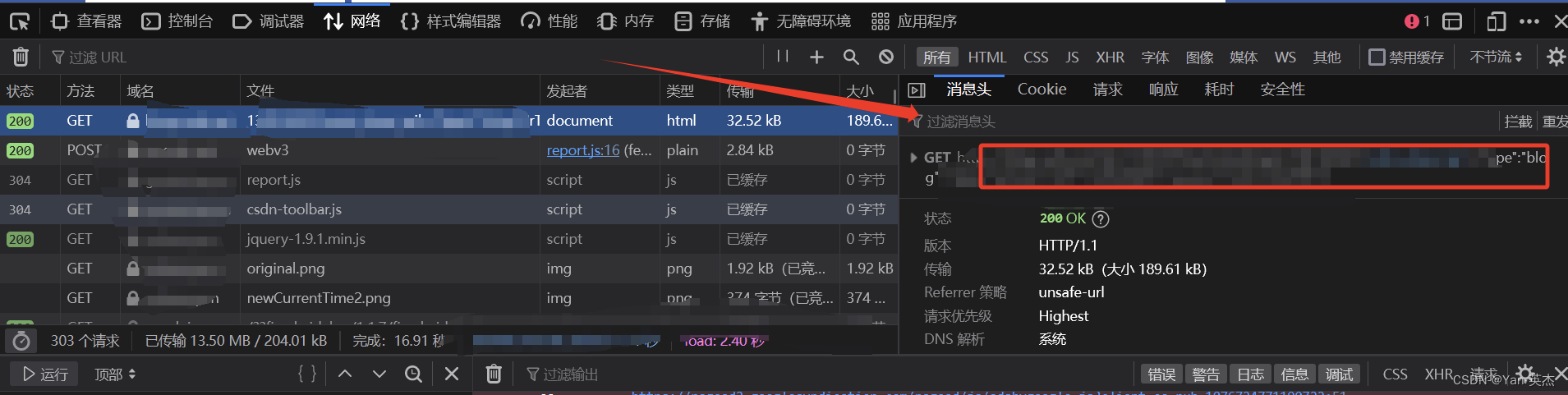
return response.text如何获取请求头:
火狐浏览器:
- 打开目标网页并右键点击页面空白处。
- 选择“检查元素”选项,或按下快捷键Ctrl + Shift + C(Windows)
- 在开发者工具窗口中,切换到“网络”选项卡。
- 刷新页面以捕获所有的网络请求。
- 在请求列表中选择您感兴趣的请求。
- 在右侧的“请求标头”或“Request Headers”部分,即可找到请求头信息。
将以下请求头信息复制出来即可
四、源代码:
该爬虫程序使用了Python的第三方库BeautifulSoup和正则表达式模块,通过解析HTML页面并进行匹配,提取了电影详情链接、图片链接、影片中文名、影片外国名、评分、评价数、概述以及相关信息等数据,最后将这些数据保存到Excel文件中。
from bs4 import BeautifulSoup
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #指定URL,获取网页数据
import xlwt #进行excel操作
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist= getdata(baseurl)
savepath = ".\\豆瓣电影top250.xls"
savedata(datalist,savepath)
#compile返回的是匹配到的模式对象
findLink = re.compile(r'') # 正则表达式模式的匹配,影片详情
findImgclass="lazy" data-src = re.compile(r'(.*)') # 影片片名
findRating = re.compile(r'') # 找到评分
findJudge = re.compile(r'(\d*)人评价') # 找到评价人数 #\d表示数字
findInq = re.compile(r'(.*)') # 找到概况
findBd = re.compile(r'https://blog.csdn.net/m0_73367097/article/details/(.*?)
', re.S) # 找到影片的相关内容,如导演,演员等
##获取网页数据
def getdata(baseurl):
datalist=[]
for i in range(0,10):
url = baseurl+str(i*25) ##豆瓣页面上一共有十页信息,一页爬取完成后继续下一页
html = geturl(url)
soup = BeautifulSoup(html,"html.parser") #构建了一个BeautifulSoup类型的对象soup,是解析html的
for item in soup.find_all("div",class_='item'): ##find_all返回的是一个列表
data=[] #保存HTML中一部电影的所有信息
item = str(item) ##需要先转换为字符串findall才能进行搜索
link = re.findall(findLink,item)[0] ##findall返回的是列表,索引只将值赋值
data.append(link)
imgclass="lazy" data-src = re.findall(findImgclass="lazy" data-src, item)[0]
data.append(imgclass="lazy" data-src)
titles=re.findall(findTitle,item) ##有的影片只有一个中文名,有的有中文和英文
if(len(titles)==2):
onetitle = titles[0]
data.append(onetitle)
twotitle = titles[1].replace("/","")#去掉无关的符号
data.append(twotitle)
else:
data.append(titles)
data.append(" ") ##将下一个值空出来
rating = re.findall(findRating, item)[0] # 添加评分
data.append(rating)
judgeNum = re.findall(findJudge, item)[0] # 添加评价人数
data.append(judgeNum)
inq = re.findall(findInq, item) # 添加概述
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub(' 五、详解代码
导入所需模块,包括`BeautifulSoup`、`re`、`urllib`和`xlwt`。
from bs4 import BeautifulSoup
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error # 指定URL,获取网页数据
import xlwt # 进行excel操作主函数,主要包含三个步骤:获取数据、保存数据和打印成功信息。
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist = getdata(baseurl)
savepath = ".\\豆瓣电影top250.xls"
savedata(datalist, savepath)这里使用正则表达式对html页面进行匹配,获取需要的信息,返回的是匹配到的模式对象。
##compile返回的是匹配到的模式对象
findLink = re.compile(r'') # 正则表达式模式的匹配,影片详情
findImgclass="lazy" data-src = re.compile(r'(.*)') # 影片片名
findRating = re.compile(r'') # 找到评分
findJudge = re.compile(r'(\d*)人评价') # 找到评价人数 #\d表示数字
findInq = re.compile(r'(.*)') # 找到概况
findBd = re.compile(r'https://blog.csdn.net/m0_73367097/article/details/(.*?)
', re.S) # 找到影片的相关内容,如导演,演员等 获取网页数据的函数,包括以下步骤:
1. 循环10次,依次爬取不同页面的信息;
2. 使用`urllib`获取html页面;
3. 使用`BeautifulSoup`解析页面;
4. 遍历每个div标签,即每一部电影;
5. 对每个电影信息进行匹配,使用正则表达式提取需要的信息并保存到一个列表中;
6. 将每个电影信息的列表保存到总列表中。
def getdata(baseurl):
datalist = []
for i in range(0, 10):
url = baseurl + str(i * 25)
html = geturl(url)
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all("div", class_='item'):
data = []
item = str(item)
link = re.findall(findLink, item)[0]
data.append(link)
imgclass="lazy" data-src = re.findall(findImgclass="lazy" data-src, item)[0]
data.append(imgclass="lazy" data-src)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
onetitle = titles[0]
data.append(onetitle)
twotitle = titles[1].replace("/", "")
data.append(twotitle)
else:
data.append(titles)
data.append(" ")
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('将获取到的数据保存到excel文件中,包括以下步骤:
1. 创建一个excel文件;
2. 在文件中创建一个工作表;
3. 写入execl项目栏,即第一行的标题;
4. 循环保存每一部电影的信息。
def savedata(datalist, savepath):
workbook = xlwt.Workbook(encoding="utf-8", style_compression=0) ##style_compression=0不压缩
worksheet = workbook.add_sheet("豆瓣电影top250", cell_overwrite_ok=True) # cell_overwrite_ok=True再次写入数据覆盖
column = ("电影详情链接", "图片链接", "影片中文名", "影片外国名", "评分", "评价数", "概况", "相关信息") ##execl项目栏
for i in range(0, 8):
worksheet.write(0, i, column[i]) # 将column[i]的内容保存在第0行,第i列
for i in range(0, 250):
data = datalist[i]
for j in range(0, 8):
worksheet.write(i + 1, j, data[j])
workbook.save(savepath)使用`urllib`获取网页数据的函数。
def geturl(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
req = urllib.request.Request(url, headers=head)
try: ##异常检测
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"): ##如果错误中有这个属性的话
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html程序入口,执行主函数,并打印成功信息。
if __name__ == '__main__':
main()
print("爬取成功!!!")六、效果展示
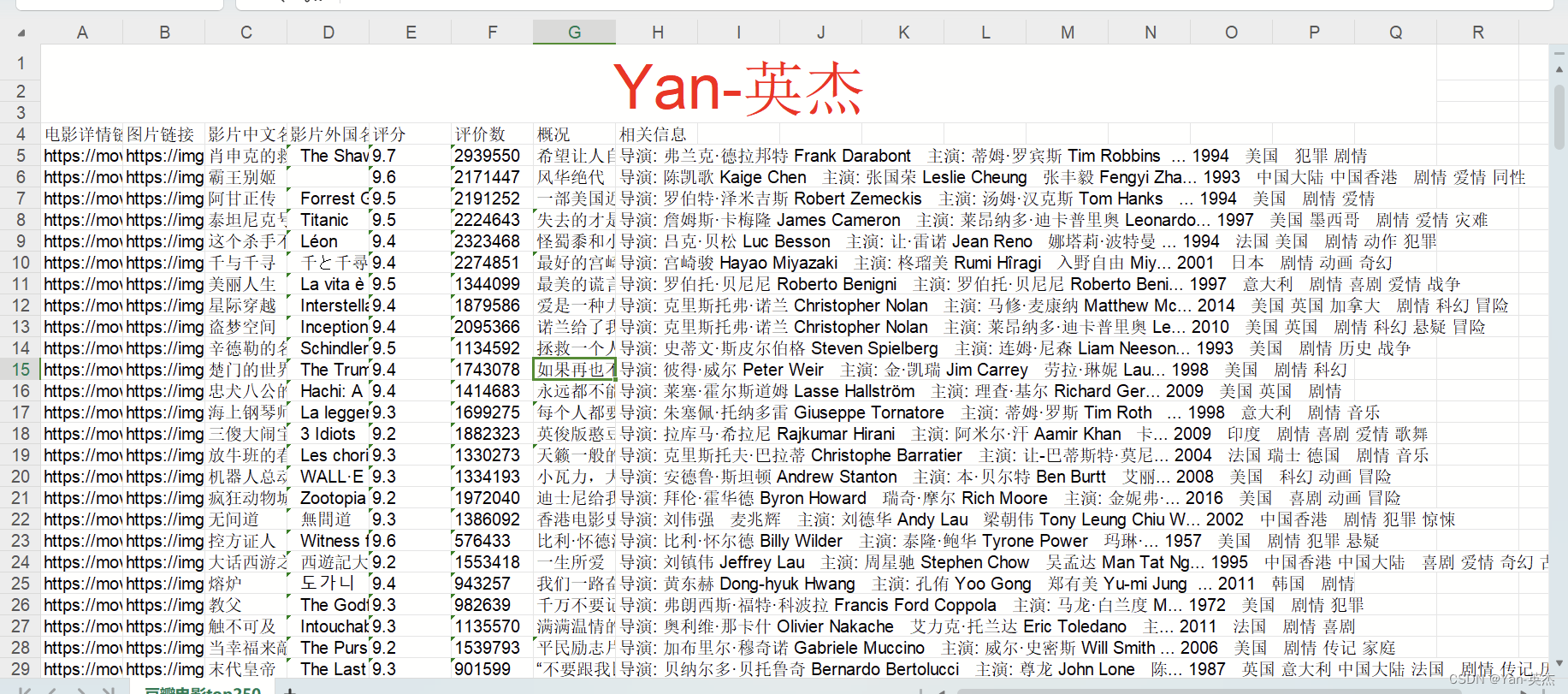
七、文末送书

参与活动
1️⃣参与方式:关注、点赞、收藏,评论(人生苦短,我一天我也懒得卷)
2️⃣获奖方式:程序随机抽取 3位,每位小伙伴将获得一本书
3️⃣活动时间:截止到 2024-1-10 22:00:00
注:活动结束后会在我的主页动态如期公布中奖者,包邮到家。
购买链接 https://product.dangdang.com/29643392.html
https://product.dangdang.com/29643392.html
这本书是美国人工智能领域的权威经典教材,受到广大师生的广泛好评。中文版更是被近百所高校采用,作为专业教科书使用。
本书第 2 版出版于 2018 年,恰恰在过去的5年中,人工智能技术有了突破性的进展,大模型即是其中的代表。第3版在第 2 版的基础上进行了内容调整和升级,以跟上技术发展的步伐。新增了深度学习、人工智能安全和人工智能编程等新进展、新成果。
全书内容包括人工智能的历史、思维和智能之辩、图灵测试、搜索、博弈、知识表示、产生式系统、专家系统、机器学习、深度学习、自然语言处理(NLP)、自动规划、遗传算法、模糊控制、安全等。此外,它还介绍了一些新技术和应用,如机器人、高级计算机博弈等。
这本书是美国人工智能领域的权威经典教材,受到广大师生的广泛好评。中文版更是被近百所高校采用,作为专业教科书使用。
本书第 2 版出版于 2018 年,恰恰在过去的5年中,人工智能技术有了突破性的进展,大模型即是其中的代表。第3版在第 2 版的基础上进行了内容调整和升级,以跟上技术发展的步伐。新增了深度学习、人工智能安全和人工智能编程等新进展、新成果。
全书内容包括人工智能的历史、思维和智能之辩、图灵测试、搜索、博弈、知识表示、产生式系统、专家系统、机器学习、深度学习、自然语言处理(NLP)、自动规划、遗传算法、模糊控制、安全等。此外,它还介绍了一些新技术和应用,如机器人、高级计算机博弈等。
来源地址:https://blog.csdn.net/m0_73367097/article/details/134193251
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341













