

python中怎么通过10行代码完成图像识别功能

这篇文章将为大家详细讲解有关python中怎么通过10行代码完成图像识别功能,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
ImageAI是一个 python 库,旨在使开发人员能够使用简单的几行代码构建具有包含深度学习和计算机视觉功能的应用程序和系统,下面将使用ImageAI为大家分享一下如何通过10行代码完成图像识别。

ImageAI安装工作
要使用ImageAI执行对象检测,您需要做的就是:
在计算机系统上安装Python 安装ImageAI及其依赖项 下载对象检测模型文件 运行示例代码(只有10行) 那么我们现在开始:
从官方Python语言网站下载并安装Python 3。 通过pip安装:TensorFlow,OpenCV, Keras, ImageAI
pip3 install tensorflowpip3 install opencv-pythonpip3 install keraspip3 install imageai --upgrade3)通过此文章中的链接下载用于对象检测的RetinaNet模型文件:
https://towardsdatascience.com/object-detection-with-10-lines-of-code-d6cb4d86f606
运行程序
太好了。我们现在已经安装了依赖项,可以编写第一个对象检测代码了。创建一个Python文件并给它起一个名字(例如,FirstDetection.py),然后将下面的代码写进去。将要检测的RetinaNet模型文件图像复制到包含python文件的文件夹中。
from imageai.Detection import ObjectDetectionimport osexecution_path =os.getcwd()detector = ObjectDetection()detector.setModelTypeAsRetinaNet()detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h6"))detector.loadModel()detections = detector.detectObjectsFromImage( input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"))for eachObject in detections:print(eachObject["name"] , " : " ,eachObject["percentage_probability"] )需要注意的是,如果你在运行遇到这个错误:
ValueError: Unable to import backend : theano python mymodel.py那么你可以尝试:
import osos.environ['KERAS_BACKEND'] = 'tensorflow'fromimageai.Detection import ObjectDetection然后运行代码并等待结果打印在控制台中。一旦结果打印到控制台中,转到您的FirstDetection.py所在的文件夹,您将发现保存了一个新图像。看看下面的两个图像样本和检测后保存的新图像。
检测前:  如何用10行代码完成目标检测 检测后:
如何用10行代码完成目标检测 检测后: 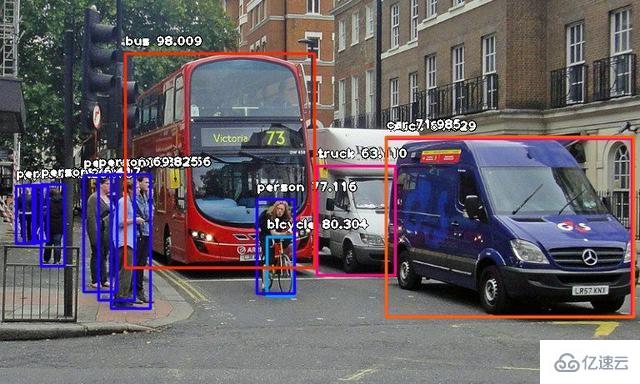 如何用10行代码完成目标检测 数据结果
如何用10行代码完成目标检测 数据结果
我们可以看到程序会打印输出一些各个物体的概率数据:
person : 55.8402955532074person : 53.21805477142334person : 69.25139427185059person : 76.41745209693909bicycle : 80.30363917350769person : 83.58567953109741person : 89.06581997871399truck : 63.10953497886658person : 69.82483863830566person : 77.11606621742249bus : 98.00949096679688truck : 84.02870297431946car : 71.98476791381836可以看出来程序可以对图片中的以下目标进行检测:
人,自行车,卡车,汽车,公交车。
大家可以直接将自己希望检测的照片放到程序里面运行看看效果。
原理解释
现在让我们解释一下10行代码是如何工作的。
from imageai.Detection import ObjectDetectionimport osexecution_path= os.getcwd()在上面的3行代码中,我们在第一行导入了ImageAI对象检测类,在第二行导入了python os类,并定义了一个变量来保存python文件、RetinaNet模型文件和图像所在的文件夹的路径。
detector = ObjectDetection()detector.setModelTypeAsRetinaNet()detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h6"))detector.loadModel()detections =detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path ,"imagenew.jpg"))在上面的代码中,我们定义对象检测类在第一线,将模型类型设置为RetinaNet在第二行,设置模型路径的路径在第三行RetinaNet模型,该模型加载到对象检测类在第四行,然后我们称为检测函数,解析输入图像的路径和输出图像路径在第五行。
for eachObject in detections: print(eachObject["name"] , " : ", eachObject["percentage_probability"] )在上面的代码中,我们在第一行迭代了detector.detectObjectsFromImage函数返回的所有结果,然后在第二行打印出图像中检测到的每个对象的模型名称和百分比概率。
关于“python中怎么通过10行代码完成图像识别功能”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












