

Lyft 基于 Flink 的大规模准实时数据分析平台(附FFA大会视频)

")
如何基于 Flink 搭建大规模准实时数据分析平台?在 Flink Forward Asia 2019 上,来自 Lyft 公司实时数据平台的徐赢博士和计算数据平台的高立博士分享了 Lyft 基于 Apache Flink 的大规模准实时数据分析平台。
查看FFA大会视频。
本次分享主要分为四个方面:
- Lyft 的流数据与场景
- 准实时数据分析平台和架构
- 平台性能及容错深入分析
- 总结与未来展望
重要:文末「阅读原文」可查看 Flink Forward Asia 大会视频。
一、Lyft 的流数据与场景
关于 Lyft
Lyft 是位于北美的一个共享交通平台,和大家所熟知的 Uber 和国内的滴滴类似,Lyft 也为民众提供共享出行的服务。Lyft 的宗旨是提供世界最好的交通方案来改善人们的生活。

Lyft 的流数据场景
Lyft 的流数据可以大致分为三类,秒级别、分钟级别和不高于 5 分钟级别。分钟级别流数据中,自适应定价系统、欺诈和异常检测系统是最常用的,此外还有 Lyft 最新研发的机器学习特征工程。不高于 5 分钟级别的场景则包括准实时数据交互查询相关的系统。

Lyft 数据分析平台架构
如下图所示的是 Lyft 之前的数据分析平台架构。Lyft 的大部分流数据都是来自于事件,而事件产生的来源主要有两种,分别是手机 APP 和后端服务,比如乘客、司机、支付以及保险等服务都会产生各种各样的事件,而这些事件都需要实时响应。
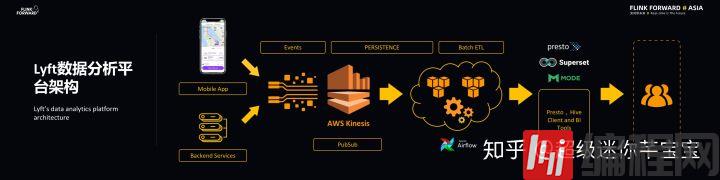
在分析平台这部分,事件会流向 AWS 的 Kinesis 上面,这里的 Kinesis 与 Apache Kafka 非常类似,是一种 AWS 上专有的 PubSub 服务,而这些数据流都会量化成文件,这些文件则都会存储在 AWS 的 S3 上面,并且很多批处理任务都会弹出一些数据子集。在分析系统方面,Lyft 使用的是开源社区中比较活跃的 presto 查询引擎。Lyft 数据分析平台的用户主要有四种,即数据工程师、数据分析师以及机器学习专家和深度学习专家,他们往往都是通过分析引擎实现与数据的交互。
既往平台的问题
Lyft 之所以要基于 Apache Flink 实现大规模准实时数据分析平台,是因为以往的平台存在一些问题。比如较高的延迟,导入数据无法满足准实时查询的要求;并且基于 Kinesis Client Library 的流式数据导入性能不足;导入数据存在太多小文件导致下游操作性能不足;数据 ETL 大多是高延迟多日多步的架构;此外,以往的平台对于嵌套数据提供的支持也不足。

二、准实时数据分析平台和架构
准实时平台架构
在新的准实时平台架构中,Lyft 采用 Flink 实现流数据持久化。Lyft 使用云端存储,而使用 Flink 直接向云端写一种叫做 Parquet 的数据格式,Parquet 是一种列数据存储格式,能够有效地支持交互式数据查询。Lyft 在 Parquet 原始数据上架构实时数仓,实时数仓的结构被存储在 Hive 的 Table 里面,Hive Table 的 metadata 存储在 Hive metastore 里面。
平台会对于原始数据做多级的非阻塞 ETL 加工,每一级都是非阻塞的(nonblocking),主要是压缩和去重的操作,从而得到更高质量的数据。平台主要使用 Apache Airflow 对于 ETL 操作进行调度。所有的 Parquet 格式的原始数据都可以被 presto 查询,交互式查询的结果将能够以 BI 模型的方式显示给用户。
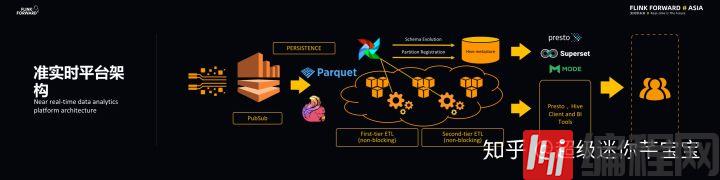
平台设计
Lyft 基于 Apache Flink 实现的大规模准实时数据分析平台具有几个特点:
- 首先,平台借助 Flink 实现高速有效的流数据接入,使得云上集群规模缩减为原来的十分之一,因此大大降低了运维成本。
- 其次,Parquet 格式的数据支持交互式查询,当用户仅对于某几个列数据感兴趣时可以通过分区和选择列的方式过滤不必要的数据,从而提升查询的性能。
- 再次,基于 AWS 的云端存储,平台的数据无需特殊存储形式。
- 之后,多级 ETL 进程能够确保更好的性能和数据质量。
- 最后,还能够兼顾性能容错及可演进性。

平台特征及应用
Lyft 准实时数据分析平台需要每天处理千亿级事件,能够做到数据延迟小于 5 分钟,而链路中使用的组件确保了数据完整性,同时基于 ETL 去冗余操作实现了数据单一性保证。

数据科学家和数据工程师在建模时会需要进行自发的交互式查询,此外,平台也会提供实时机器学习模型正确性预警,以及实时数据面板来监控供需市场健康状况。
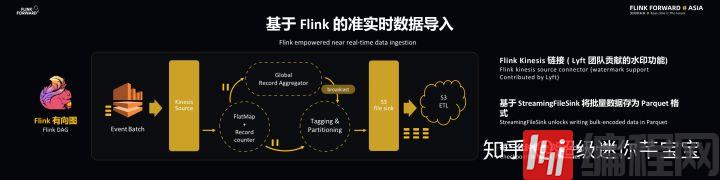
基于 Flink 的准实时数据导入
下图可以看到当事件到达 Kinesis 之后就会被存储成为 EventBatch。通过 Flink-Kinesis 连接器可以将事件提取出来并送到 FlatMap 和 Record Counter 上面,FlatMap 将事件打撒并送到下游的 Global Record Aggregator 和 Tagging Partitioning 上面,每当做 CheckPoint 时会关闭文件并做一个持久化操作,针对于 StreamingFileSink 的特征,平台设置了每三分钟做一次 CheckPoint 操作,这样可以保证当事件进入 Kinesis 连接器之后在三分钟之内就能够持久化。
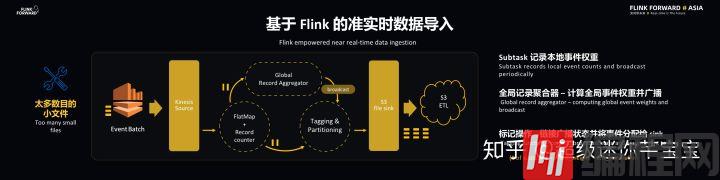
以上的方式会造成太多数量的小文件问题,因为数据链路支持成千上万种文件,因此使用了 Subtasks 记录本地事件权重,并通过全局记录聚合器来计算事件全局权重并广播到下游去。而 Operator 接收到事件权重之后将会将事件分配给 Sink。
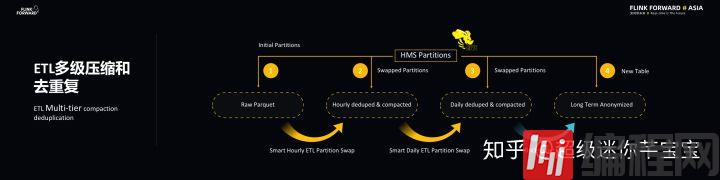
ETL 多级压缩和去重
上述的数据链路也会做 ETL 多级压缩和去重工作,主要是 Parquet 原始数据会经过每小时的智能压缩去重的 ETL 工作,产生更大的 Parquet File。同理,对于小时级别压缩去重不够的文件,每天还会再进行一次压缩去重。对于新产生的数据会有一个原子性的分区交换,也就是说当产生新的数据之后,ETL Job 会让 Hive metastore 里的表分区指向新的数据和分区。这里的过程使用了启发性算法来分析哪些事件必须要经过压缩和去重以及压缩去重的时间间隔级别。此外,为了满足隐私和合规的要求,一些 ETL 数据会被保存数以年计的时间。
三、平台性能及容错深入分析
事件时间驱动的分区感测
Flink 和 ETL 是通过事件时间驱动的分区感测实现同步的。S3 采用的是比较常见的分区格式,最后的分区是由时间戳决定的,时间戳则是基于 EventTime 的,这样的好处在于能够带来 Flink 和 ETL 共同的时间源,这样有助于同步操作。此外,基于事件时间能够使得一些回填操作和主操作实现类似的结果。Flink 处理完每个小时的事件后会向事件分区写入一个 Success 文件,这代表该小时的事件已经处理完毕,ETL 可以对于该小时的文件进行操作了。
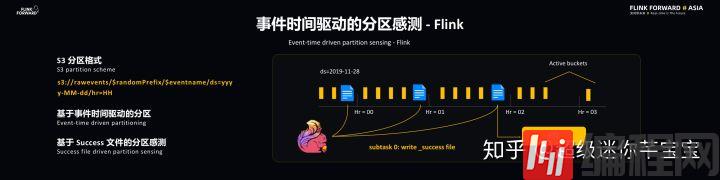
Flink 本身的水印并不能直接用到 Lyft 的应用场景当中,主要是因为当 Flink 处理完时间戳并不意味着它已经被持久化到存储当中,此时就需要引入分区水印的概念,这样一来每个 Sink Source 就能够知道当前写入的分区,并且维护一个分区 ID,并且通过 Global State Aggregator 聚合每个分区的信息。每个 Subtasks 能够知道全局的信息,并将水印定义为分区时间戳中最小的一个。

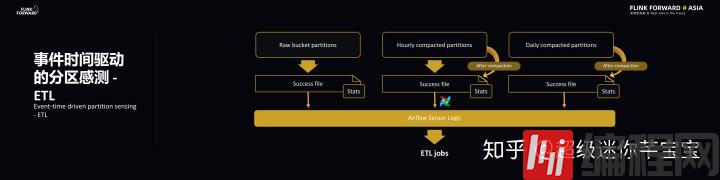
ETL 主要有两个特点,分别是及时性和去重,而 ETL 的主要功能在于去重和压缩,最重要的是在非阻塞的情况下就进行去重。前面也提到 Smart ETL,所谓 Smart 就是智能感知,需要两个相应的信息来引导 Global State Aggregator,分别是分区完整性标识 SuccessFile,在每个分区还有几个相应的 States 统计信息能够告诉下游的 ETL 怎样去重和压缩以及操作的频率和范围。
Schema 演进的挑战
ETL 除了去重和压缩的挑战之外,还经常会遇到 Schema 的演化挑战。Schema 演化的挑战分为三个方面,即不同引擎的数据类型、嵌套结构的演变、数据类型演变对去重逻辑的影响。

S3 深入分析
Lyft 的数据存储系统其实可以认为是数据湖,对于 S3 而言,Lyft 也有一些性能的优化考量。S3 本身内部也是有分区的,为了使其具有并行的读写性能,添加了 S3 的熵数前缀,在分区里面也增加了标记文件,这两种做法能够极大地降低 S3 的 IO 性能的影响。标识符对于能否触发 ETL 操作会产生影响,与此同时也是对于 presto 的集成,能够让 presto 决定什么情况下能够扫描多少个文件。

Parquet 优化方案
Lyft 的准实时数据分析平台在 Parquet 方面做了很多优化,比如文件数据值大小范围统计信息、文件系统统计信息、基于主键数据值的排序加快 presto 的查询速度以及二级索引的生成。

基于数据回填的平台容错机制
如下两个图所示的是 Lyft 准实时数据分析平台的基于数据回填的平台容错机制。对于 Flink 而言,因为平台的要求是达到准实时,而 Flink 的 Job 出现失效的时候可能会超过一定的时间,当 Job 重新开始之后就会形成两个数据流,主数据流总是从最新的数据开始往下执行,附加数据流则可以回溯到之前中断的位置进行执行直到中断结束的位置。这样的好处是既能保证主数据流的准实时特性,同时通过回填数据流保证数据的完整性。

对于 ETL 而言,基于数据回填的平台容错机制则表现在 Airflow 的幂等调度系统、原子压缩和 HMS 交换操作、分区自建自修复体系和 Schema 整合。

四、总结与未来展望
体验与经验教训
利用 Flink 能够准实时注入 Parquet 数据,使得交互式查询体验为可能。同时,Flink 在 Lyft 中的应用很多地方也需要提高,虽然 Flink 在大多数情况的延时都能够得到保证,但是重启和部署的时候仍然可能造成分钟级别的延时,这会对于 SLO 产生一定影响。
此外,Lyft 目前做的一件事情就是改善部署系统使其能够支持 Kubernetes,并且使得其能够接近 0 宕机时间的效果。因为 Lyft 准实时数据分析平台在云端运行,因此在将数据上传到 S3 的时候会产生一些随机的网络情况,造成 Sink Subtasks 的停滞,进而造成整个 Flink Job 的停滞。而通过引入一些 Time Out 机制来检测 Sink Subtasks 的停滞,使得整个 Flink Job 能够顺利运行下去。
ETL 分区感应能够降低成本和延迟,成功文件则能够表示什么时候处理完成。此外,S3 文件布局对性能提升的影响还是非常大的,目前而言引入熵数还属于经验总结,后续 Lyft 也会对于这些进行总结分析并且公开。因为使用 Parquet 数据,因此对于 Schema 的兼容性要求就非常高,如果引入了不兼容事件则会使得下游的 ETL 瘫痪,因此 Lyft 已经做到的就是在数据链路上游对于 Schema 的兼容性进行检查,检测并拒绝用户提交不兼容的 Schema。

未来展望
Lyft 对于准实时数据分析平台也有一些设想。
- 首先,Lyft 希望将 Flink 部署在 Kubernetes 集群环境下运行,使得 Kubernetes 能够管理这些 Flink Job,同时也能够充分利用 Kubernetes 集群的高可扩展性。
- 其次,Lyft 也希望实现通用的流数据导入框架,准实时数据分析平台不仅仅支持事件,也能够支持数据库以及服务日志等数据。
- 再次,Lyft 希望平台能够实现 ETL 智能压缩以及事件驱动 ETL,使得回填等事件能够自动触发相应的 ETL 过程,实现和以前的数据的合并,同时将延时数据导入来对于 ETL 过程进行更新。
- 最后,Lyft 还希望准实时数据分析平台能够实现存储过程的改进以及查询优化,借助 Parquet 的统计数据来改善 presto 的查询性能,借助表格管理相关的开源软件对存储管理进行性能改善,同时实现更多的功能。
原文链接
本文为阿里云原创内容,未经允许不得转载。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












