

python爬虫urllib中的异常模块如何处理

这篇文章主要介绍“python爬虫urllib中的异常模块如何处理”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“python爬虫urllib中的异常模块如何处理”文章能帮助大家解决问题。
urllib中的异常处理
在我们写爬虫程序时,若出现url中的错误,那么我们就无法爬取我们想要的内容,对此,我们引入了urllib中的异常处理。
url的组成部分
URL由6个部分组成:eg:
https://www.baidu.com/s?wd=易烊千玺
协议(http/https)
主机(www.baidu.com)
端口号(80/443)
路径(s)
参数(wd=易烊千玺)
锚点
常见的端口号:
http(80) https(443) mysql(3306) oracle(1521) redis(6379) mongodb(27017)
URLError
通常来说,URLError报错通常为url地址中主机部分的错误:
实例:
url = 'https://www.baidu.com1/'运行结果:
urllib.error.URLError: <urlopen error [Errno 11001] getaddrinfo failed
HTTPError
这个异常的通常是url地址中参数或是路径的错误。
实例:
url = 'https://www.jianshu.com/p/3388cf148dba1'运行结果:
urllib.error.HTTPError: HTTP Error 404: Not Found
简介
HTTPError类是URLError类的子类
导入的包urllib.error.HTTPError/urllib.error.URLError
http错误:http错误是针对浏览器无法连接到服务器而增加的出来的错误提示,引导并告诉浏览者该页是出了什么问题。
通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更健壮,可以通过try -except进行捕获异常。
Urllib.error 模块
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
urllib.error 包含了两个方法,URLError 和 HTTPError。
URLError 是 OSError 的一个子类,用于处理程序在遇到问题时会引发此异常(或其派生的异常)。
HTTPError 是 URLError 的一个子类,用于处理特殊 HTTP 错误例如作为认证请求的时候,包含的属性 code 为 HTTP 的状态码, reason 为引发异常的原因,headers 为导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
异常处理
用try except语句块捕获并处理异常,其基本语法结构如下所示:
try:可能产生异常的代码块
except [ (Error1, Error2, … ) [as e] ]:处理异常的代码块1
except [ (Error3, Error4, … ) [as e] ]:处理异常的代码块2
except [Exception]:处理其它异常
实例:
原url= ‘https://www.jianshu.com/p/3388cf148dba’
源码:
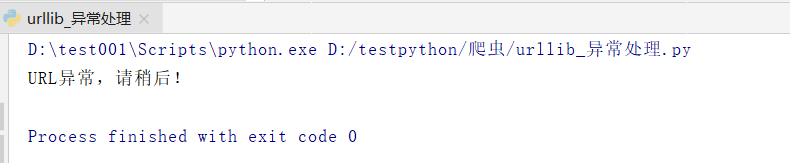
import urllib.requestimport urllib.errorurl = 'https://www.jianshu.com1/p/3388cf148dba'# url的组成 eg:https://www.baidu.com/s?wd=易烊千玺# 1.协议(http/https) 2.主机(www.baidu.com) 3.端口号(80/443) 4.路径(s) 5.参数(wd=易烊千玺) 6.锚点# 常见的端口号# http(80) https(443) mysql(3306) oracle(1521) redis(6379) mongodb(27017)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'}try: request = urllib.request.Request(url = url,headers = headers) response = urllib.request.urlopen(request) content = response.read().decode('utf8') print(content)except urllib.error.HTTPError: print('HTTP异常,请稍后!')except urllib.error.URLError: print('URL异常,请稍后!')URLError
url = ‘https://www.jianshu.com1/p/3388cf148dba’
运行结果:
HTTPError
url = ‘https://www.jianshu.com/p/3388cf148dba111’
运行结果:

关于“python爬虫urllib中的异常模块如何处理”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注编程网行业资讯频道,小编每天都会为大家更新不同的知识点。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341















