

MySQL 教程---菜鸟教程


文章目录
- MySQL 教程
- 登录 MySQL
- 数据库操作
- 数据类型
- 创建数据表
- 删除数据表
- 插入数据
- 查询数据
- WHERE 子句
- UPDATE 更新
- DELETE 子句
- LIKE 子句
- UNION 操作符
- 排序
- 分组 GROUP BY 语句
- 连接的使用
- NULL 值处理
- 事务
- ALTER 命令
- 索引
- 临时表
- 复制表
- 序列使用
- 处理重复数据
MySQL 教程
关系型数据库管理系统(RDBMS)
RDBMS 术语:
- 数据库:数据库是一些关联表的集合。
- 数据表:表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列:一列包含了相同类型的数据,例如邮政编码的数据。
- 行:一行是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:用于关联两个表。
- 复合键:复合键将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排列的一种结构。类似于书籍的目录。
- 参照完整性:参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
MySQL 为关系型数据库(Relational Database Management System), 这种所谓的"关系型"可以理解为"表格"的概念, 一个关系型数据库由一个或数个表格组成, 如图所示的一个表格:
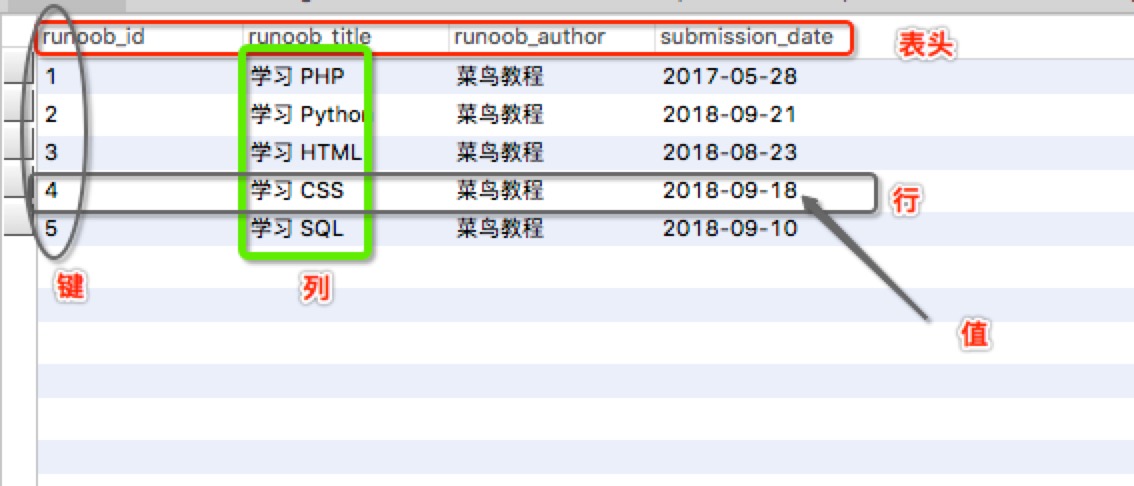
- 表头(header): 每一列的名称;
- 列(col): 具有相同数据类型的数据的集合;
- 行(row): 每一行用来描述某条记录的具体信息;
- 值(value): 行的具体信息, 每个值必须与该列的数据类型相同;
- 键(key): 键的值在当前列中具有唯一性。
登录 MySQL
如果我们要登录本机的 MySQL 数据库,只需要输入以下命令即可:
mysql -u root -p
按回车确认, 如果安装正确且 MySQL 正在运行, 会得到以下响应:
Enter password:
若密码存在, 输入密码登录, 不存在则直接按回车登录。登录成功后你将会看到 Welcome to the MySQL monitor... 的提示语。
然后命令提示符会一直以 mysql> 加一个闪烁的光标等待命令的输入, 输入 exit 或 quit 退出登录。
数据库操作
创建数据库:
CREATE DATABASE 数据库名;
删除数据库:
drop database 数据库名;
选择数据库:
use 数据库名;
数据类型
MySQL 支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
数值类型
MySQL 支持所有标准 SQL 数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL 和 NUMERIC),以及近似数值数据类型(FLOAT、REAL 和 DOUBLE PRECISION)。
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。
创建数据表
以下为创建MySQL数据表的SQL通用语法:
CREATE TABLE table_name (column_name column_type);
以下例子中我们将在 RUNOOB 数据库中创建数据表runoob_tbl:
USE RUNOOB;CREATE TABLE IF NOT EXISTS runoob_tbl( runoob_id INT UNSIGNED AUTO_INCREMENT, runoob_title VARCHAR(100) NOT NULL, runoob_author VARCHAR(40) NOT NULL, submission_date DATE, PRIMARY KEY (runoob_id))ENGINE=InnoDB DEFAULT CHARSET=utf8;实例解析:
如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
ENGINE 设置存储引擎,CHARSET 设置编码。
删除数据表
以下为删除MySQL数据表的通用语法:
DROP TABLE table_name ;
USE RUNOOB;DROP TABLE runoob_tbl;插入数据
以下为向MySQL数据表插入数据通用的 INSERT INTO SQL语法:
INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN );以下实例中我们将向 runoob_tbl 表插入三条数据:
use RUNOOB;INSERT INTO runoob_tbl (runoob_title, runoob_author, submission_date)VALUES("学习 PHP", "菜鸟教程", NOW()),("学习 MySQL", "菜鸟教程", NOW()),("JAVA 教程", "RUNOOB.COM", '2016-05-06');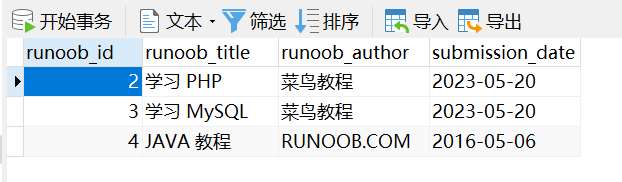
查询数据
以下实例将返回数据表 runoob_tbl 的所有记录:
读取数据表:
select * from runoob_tbl;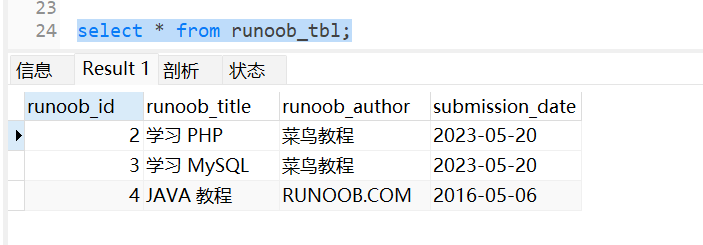
WHERE 子句
SELECT * from runoob_tbl WHERE runoob_author='菜鸟教程';
MySQL 的 WHERE 子句的字符串比较是不区分大小写的。 你可以使用 BINARY 关键字来设定 WHERE 子句的字符串比较是区分大小写的。
SELECT * from runoob_tbl WHERE BINARY runoob_author='RUNOOB.COM';实例中使用了 BINARY 关键字,是区分大小写的,所以runoob_author='runoob.com'的查询条件是没有数据的。
UPDATE 更新
以下实例将更新数据表中 runoob_id 为 3 的 runoob_title 字段值:
UPDATE runoob_tbl SET runoob_title='学习 C++' WHERE runoob_id=3;SELECT * from runoob_tbl WHERE runoob_id=3;
DELETE 子句
以下实例将删除 runoob_tbl 表中 runoob_id 为3 的记录:
DELETE FROM runoob_tbl WHERE runoob_id=3;LIKE 子句
以下我们将在 SQL SELECT 命令中使用 WHERE…LIKE 子句来从MySQL数据表 runoob_tbl 中读取数据。
实例
以下是我们将 runoob_tbl 表中获取 runoob_author 字段中以 COM 为结尾的的所有记录:
SELECT * from runoob_tbl WHERE runoob_author LIKE '%COM';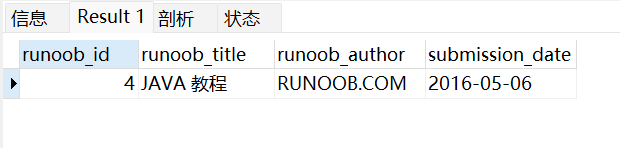
UNION 操作符
描述
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
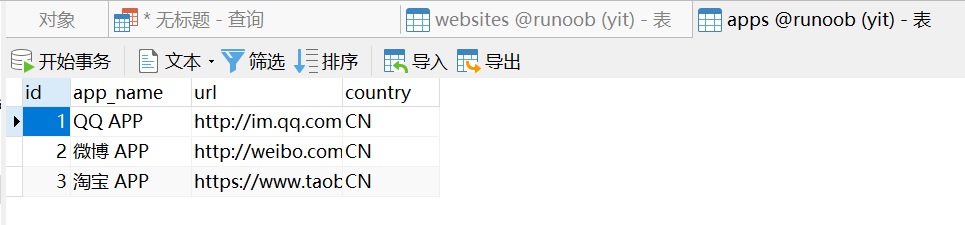
前提:创建表websites,写入数据
USE runoob;CREATE TABLE IF NOT EXISTS Websites( id INT UNSIGNED AUTO_INCREMENT, name VARCHAR(100) NOT NULL, url VARCHAR(200) NOT NULL, alexa INT, country VARCHAR(40), PRIMARY KEY (id))ENGINE=InnoDB DEFAULT CHARSET=utf8;---写数据INSERT INTO websites(name, url, alexa, country)VALUES("Google", "https://www.google.cm/", 1, "USA"),("淘宝", "https://www.taobao.com/", 13, "CN"),("菜鸟教程","http://www.runoob.com",4689, "CN"),("微博","http://weibo.com/", 20, "CN"),("Facebook","https://www.facebook.com/",3,"USA"),("stackoverflow","http://stackoverflow.com/",0,"IND");创建表apps,写入数据:
USE runoob;CREATE TABLE IF NOT EXISTS apps( id INT UNSIGNED AUTO_INCREMENT, app_name VARCHAR(100) NOT NULL, url VARCHAR(200) NOT NULL, country VARCHAR(40), PRIMARY KEY (id))ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO apps(app_name, url, country)VALUES("QQ APP","http://im.qq.com/","CN"),("微博 APP","http://weibo.com/","CN"),("淘宝 APP","https://www.taobao.com/","CN");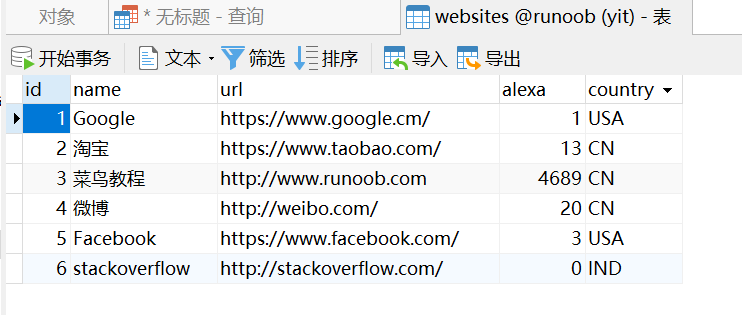
SQL UNION 实例
下面的 SQL 语句从 “Websites” 和 “apps” 表中选取所有不同的country(只有不同的值):
SELECT country FROM WebsitesUNIONSELECT country FROM appsORDER BY country;
SQL UNION ALL 实例
下面的 SQL 语句使用 UNION ALL 从 “Websites” 和 “apps” 表中选取所有的country(也有重复的值):
SELECT country FROM WebsitesUNION ALLSELECT country FROM appsORDER BY country;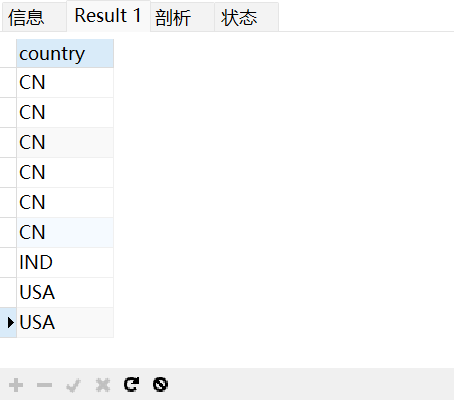
带有 WHERE 的 SQL UNION ALL
下面的 SQL 语句使用 UNION ALL 从 “Websites” 和 “apps” 表中选取所有的中国(CN)的数据(也有重复的值):
SELECT country, name FROM WebsitesWHERE country='CN'UNION ALLSELECT country, app_name FROM appsWHERE country='CN'ORDER BY country;
排序
尝试以下实例,结果将按升序及降序排列。
SELECT * from runoob_tbl ORDER BY submission_date ASC;SELECT * from runoob_tbl ORDER BY submission_date DESC;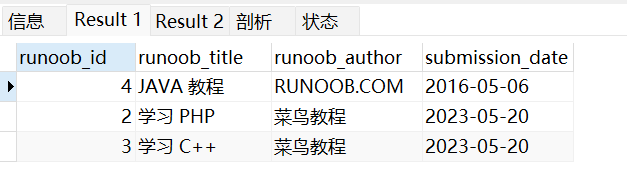

分组 GROUP BY 语句
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
已知表
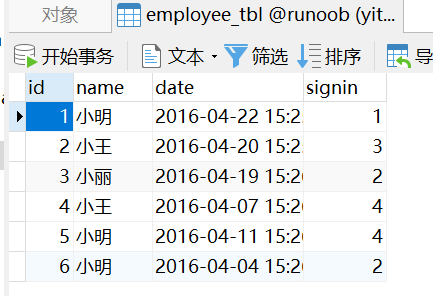
接下来我们使用 GROUP BY 语句 将数据表按名字进行分组,并统计每个人有多少条记录:
SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;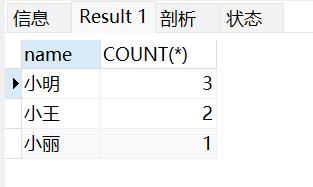
使用 WITH ROLLUP
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
例如我们将以上的数据表按名字进行分组,再统计每个人登录的次数:
SELECT name, SUM(signin) as signin_count FROM employee_tbl GROUP BY name WITH ROLLUP;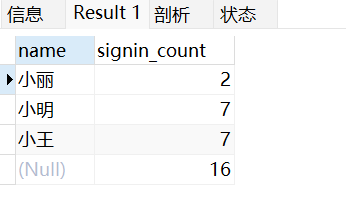
其中记录 NULL 表示所有人的登录次数。
我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法:select coalesce(a,b,c);
参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。
以下实例中如果名字为空我们使用总数代替:
SELECT coalesce(name, '总数'), SUM(signin) as signin_count FROM employee_tbl GROUP BY name WITH ROLLUP;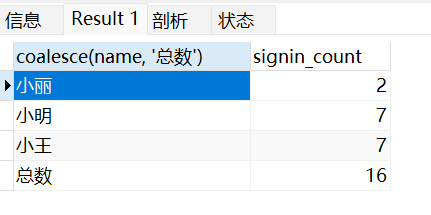
连接的使用
本章节我们将向大家介绍如何使用 MySQL 的 JOIN 在两个或多个表中查询数据。
你可以在 SELECT, UPDATE 和 DELETE 语句中使用 Mysql 的 JOIN 来联合多表查询。
JOIN 按照功能大致分为如下三类:
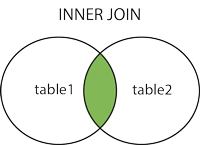
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
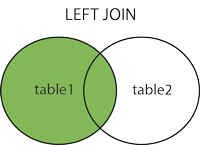
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
INNER JOIN:
已知两个表
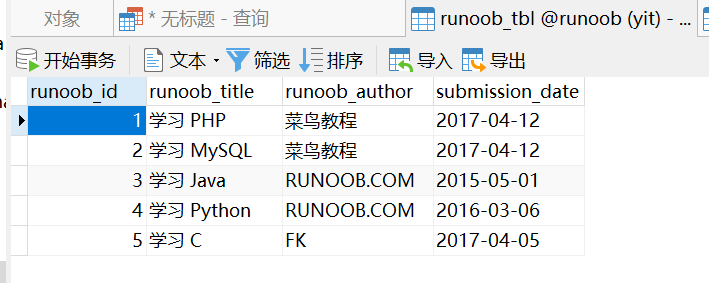
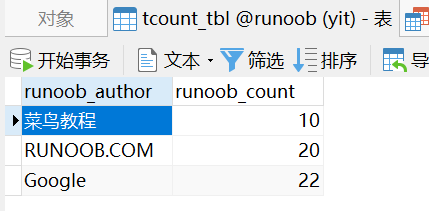
接下来我们就使用 MySQL 的 INNER JOIN 来连接以上两张表来读取 runoob_tbl 表中所有 runoob_author 字段在 tcount_tbl 表对应的 runoob_count 字段值:
SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a INNER JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
LEFT JOIN
LEFT JOIN 会读取左边数据表的全部数据,即使右边表无对应数据。
尝试以下实例,以 runoob_tbl 为左表,tcount_tbl 为右表,理解 MySQL LEFT JOIN 的应用:
SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a LEFT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
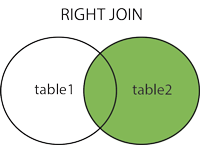
RIGHT JOIN
MySQL RIGHT JOIN 会读取右边数据表的全部数据,即使左边边表无对应数据。
尝试以下实例,以 runoob_tbl 为左表,tcount_tbl 为右表,理解MySQL RIGHT JOIN的应用:
SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a RIGHT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
NULL 值处理
MySQL提供了三大运算符:
- IS NULL: 当列的值是 NULL,此运算符返回 true。
- IS NOT NULL: 当列的值不为 NULL, 运算符返回 true。
- <=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。
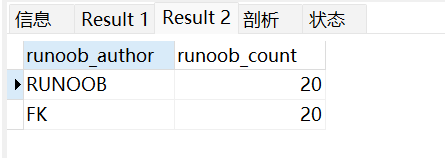
以下实例中假设数据库 RUNOOB 中的表 runoob_test_tbl 含有两列 runoob_author 和 runoob_count, runoob_count 中设置插入NULL值。
create table runoob_test_tbl(runoob_author varchar(40) NOT NULL,runoob_count INT);INSERT INTO runoob_test_tbl (runoob_author, runoob_count) values ('RUNOOB', 20);INSERT INTO runoob_test_tbl (runoob_author, runoob_count) values ('菜鸟教程', NULL);INSERT INTO runoob_test_tbl (runoob_author, runoob_count) values ('Google', NULL);INSERT INTO runoob_test_tbl (runoob_author, runoob_count) values ('FK', 20);SELECT * from runoob_test_tbl;
查找数据表中 runoob_test_tbl 列是否为 NULL,必须使用 IS NULL 和 IS NOT NULL,如下实例:
SELECT * FROM runoob_test_tbl WHERE runoob_count IS NULL;SELECT * from runoob_test_tbl WHERE runoob_count IS NOT NULL;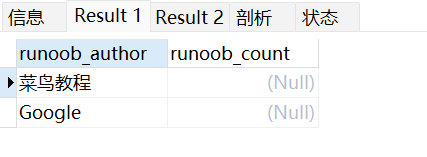
事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你既需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
-
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
-
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
-
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
-
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务控制语句:
-
BEGIN 或 START TRANSACTION 显式地开启一个事务;
-
COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
-
ROLLBACK 回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
-
SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
-
RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
-
ROLLBACK TO identifier 把事务回滚到标记点;
-
SET TRANSACTION 用来设置事务的隔离级别。InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
MYSQL 事务处理主要有两种方法:
1、用 BEGIN, ROLLBACK, COMMIT来实现
- BEGIN 开始一个事务
- ROLLBACK 事务回滚
- COMMIT 事务确认
直接用 SET 来改变 MySQL 的自动提交模式:
- SET AUTOCOMMIT=0 禁止自动提交
- SET AUTOCOMMIT=1 开启自动提交
事务测试:
CREATE TABLE runoob_transaction_test( id int(5)); # 创建数据表select * from runoob_transaction_test;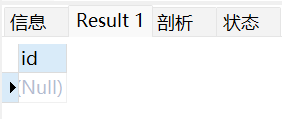
begin; # 开始事务insert into runoob_transaction_test value(5);insert into runoob_transaction_test value(6);commit; # 提交事务select * from runoob_transaction_test;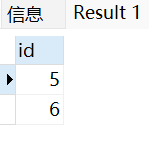
begin; # 开始事务insert into runoob_transaction_test values(7);rollback; # 回滚select * from runoob_transaction_test; # 因为回滚所以数据没有插入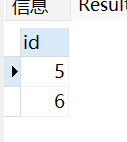
ALTER 命令
当我们需要修改数据表名或者修改数据表字段时,就需要使用到MySQL ALTER命令。
开始本章教程前让我们先创建一张表,表名为:testalter_tbl。
use RUNOOB;create table testalter_tbl(i INT,c CHAR(1));SHOW COLUMNS FROM testalter_tbl;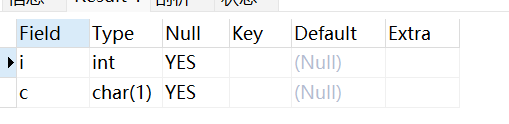
删除、添加或修改表字段
如下命令使用了 ALTER 命令及 DROP 子句来删除以上创建表的 i 字段:
ALTER TABLE testalter_tbl DROP i;如果数据表中只剩余一个字段则无法使用DROP来删除字段。
MySQL 中使用 ADD 子句来向数据表中添加列,如下实例在表 testalter_tbl 中添加 i 字段,并定义数据类型:
ALTER TABLE testalter_tbl ADD i INT;执行以上命令后,i 字段会自动添加到数据表字段的末尾。
SHOW COLUMNS FROM testalter_tbl;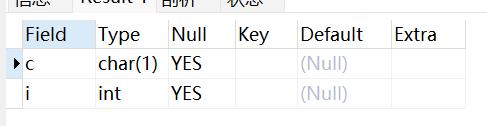
如果你需要指定新增字段的位置,可以使用MySQL提供的关键字 FIRST (设定位第一列), AFTER 字段名(设定位于某个字段之后)。
尝试以下 ALTER TABLE 语句, 在执行成功后,使用 SHOW COLUMNS 查看表结构的变化:
ALTER TABLE testalter_tbl DROP i;ALTER TABLE testalter_tbl ADD i INT FIRST;ALTER TABLE testalter_tbl DROP i;ALTER TABLE testalter_tbl ADD i INT AFTER c;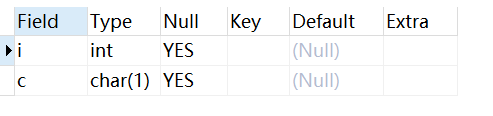
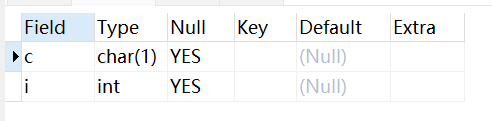
FIRST 和 AFTER 关键字可用于 ADD 与 MODIFY 子句,所以如果你想重置数据表字段的位置就需要先使用 DROP 删除字段然后使用 ADD 来添加字段并设置位置。
修改字段类型及名称
如果需要修改字段类型及名称, 你可以在ALTER命令中使用 MODIFY 或 CHANGE 子句 。
例如,把字段 c 的类型从 CHAR(1) 改为 CHAR(10),可以执行以下命令:
ALTER TABLE testalter_tbl MODIFY c CHAR(10);使用 CHANGE 子句, 语法有很大的不同。 在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型。尝试如下实例:
ALTER TABLE testalter_tbl CHANGE i j BIGINT;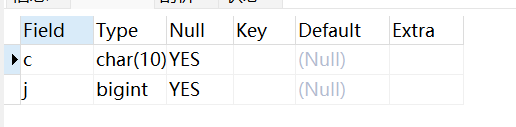
ALTER TABLE testalter_tbl CHANGE j j INT;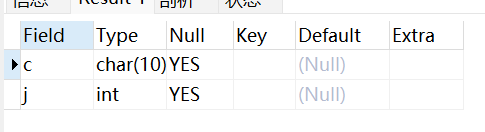
ALTER TABLE 对 Null 值和默认值的影响
当你修改字段时,你可以指定是否包含值或者是否设置默认值。
以下实例,指定字段 j 为 NOT NULL 且默认值为100 。
ALTER TABLE testalter_tbl MODIFY j BIGINT NOT NULL DEFAULT 100;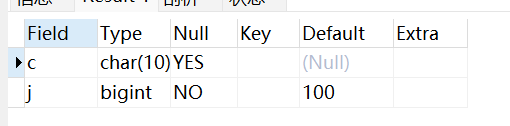
如果你不设置默认值,MySQL会自动设置该字段默认为 NULL。
ALTER TABLE testalter_tbl MODIFY j BIGINT NULL;SHOW COLUMNS FROM testalter_tbl;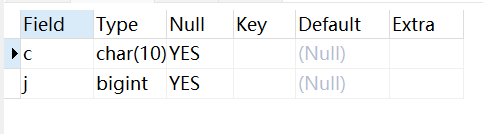
修改字段默认值
你可以使用 ALTER 来修改字段的默认值,尝试以下实例:
ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;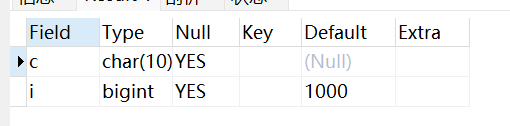
你也可以使用 ALTER 命令及 DROP子句来删除字段的默认值,如下实例:
ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;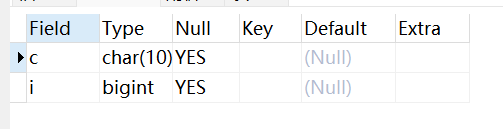
修改表名
果需要修改数据表的名称,可以在 ALTER TABLE 语句中使用 RENAME 子句来实现。
尝试以下实例将数据表 testalter_tbl 重命名为 alter_tbl:
ALTER TABLE testalter_tbl RENAME TO alter_tbl;ALTER 命令还可以用来创建及删除MySQL数据表的索引,该功能我们会在接下来的章节中介绍。
索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
普通索引
创建索引CREATE INDEX indexName ON table_name (column_name)添加索引ALTER table tableName ADD INDEX indexName(columnName)创建表的时候直接指定CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) ); 删除索引的语法DROP INDEX [indexName] ON mytable; 使用 ALTER 命令添加和删除索引
以下实例为在表中添加索引。
ALTER TABLE testalter_tbl ADD INDEX (c);以下实例删除索引:
ALTER TABLE testalter_tbl DROP INDEX c;使用 ALTER 命令添加和删除主键
主键作用于列上(可以一个列或多个列联合主键),添加主键索引时,你需要确保该主键默认不为空(NOT NULL)。实例如下:
ALTER TABLE testalter_tbl MODIFY i INT NOT NULL;ALTER TABLE testalter_tbl ADD PRIMARY KEY (i);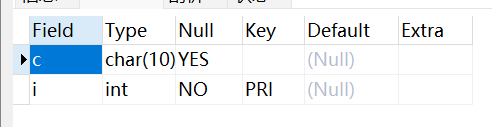
你也可以使用 ALTER 命令删除主键:
ALTER TABLE testalter_tbl DROP PRIMARY KEY;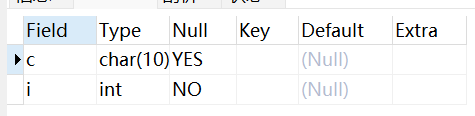
显示索引信息:
SHOW INDEX FROM table_name;临时表
MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。
创建临时表:
CREATE TEMPORARY TABLE SalesSummary (product_name VARCHAR(50) NOT NULL, total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00, avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00, total_units_sold INT UNSIGNED NOT NULL DEFAULT 0);INSERT INTO SalesSummary(product_name, total_sales, avg_unit_price, total_units_sold)VALUES('cucumber', 100.25, 90, 2);SELECT * FROM SalesSummary;
删除临时表
DROP TABLE SalesSummary;SELECT * FROM SalesSummary;
复制表
尝试以下实例来复制表 runoob_tbl 。
步骤一:
获取数据表的完整结构。
SHOW CREATE TABLE runoob_tbl;
步骤二:
修改SQL语句的数据表名,并执行SQL语句。
CREATE TABLE `clone_tbl` ( `runoob_id` int NOT NULL AUTO_INCREMENT, `runoob_title` varchar(100) NOT NULL, `runoob_author` varchar(40) NOT NULL, `submission_date` date DEFAULT NULL, PRIMARY KEY (`runoob_id`)) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8
步骤三:
如果你想拷贝数据表的数据你可以使用 INSERT INTO… SELECT 语句来实现。
INSERT INTO clone_tbl (runoob_id, runoob_title, runoob_author, submission_date)SELECT runoob_id,runoob_title, runoob_author, submission_dateFROM runoob_tbl;SELECT * FROM clone_tbl;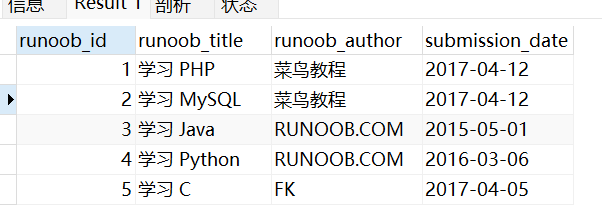
序列使用
MySQL 序列是一组整数:1, 2, 3, …,由于一张数据表只能有一个字段自增主键, 如果你想实现其他字段也实现自动增加,就可以使用MySQL序列来实现。
使用 AUTO_INCREMENT
以下实例中创建了数据表 insect, insect 表中 id 无需指定值可实现自动增长。
CREATE TABLE insect(id INT UNSIGNED NOT NULL AUTO_INCREMENT,PRIMARY KEY (id),name VARCHAR(30) NOT NULL, # type of insectdate DATE NOT NULL, # date collectedorigin VARCHAR(30) NOT NULL # where collected);INSERT INTO insect (id,name,date,origin) VALUES(NULL,'housefly','2001-09-10','kitchen'),(NULL,'millipede','2001-09-10','driveway'),(NULL,'grasshopper','2001-09-10','front yard');SELECT * FROM insect ORDER BY id;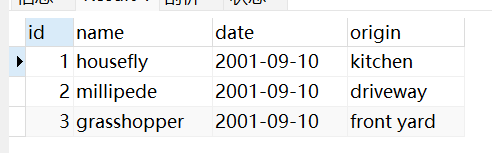
重置序列
如果你删除了数据表中的多条记录,并希望对剩下数据的AUTO_INCREMENT列进行重新排列,那么你可以通过删除自增的列,然后重新添加来实现。
ALTER TABLE insect DROP id;ALTER TABLE insectADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,ADD PRIMARY KEY (id);设置序列的开始值
CREATE TABLE insect(id INT UNSIGNED NOT NULL AUTO_INCREMENT,PRIMARY KEY (id),name VARCHAR(30) NOT NULL, date DATE NOT NULL,origin VARCHAR(30) NOT NULL)engine=innodb auto_increment=100 charset=utf8;或者你也可以在表创建成功后,通过以下语句来实现:
ALTER TABLE t AUTO_INCREMENT = 100;处理重复数据
本章节我们将为大家介绍如何防止数据表出现重复数据及如何删除数据表中的重复数据。
防止表中出现重复数据
如果你想设置表中字段 first_name,last_name 数据不能重复,你可以设置双主键模式来设置数据的唯一性, 如果你设置了双主键,那么那个键的默认值不能为 NULL,可设置为 NOT NULL。如下所示:
CREATE TABLE person_tbl( first_name CHAR(20) NOT NULL, last_name CHAR(20) NOT NULL, sex CHAR(10), PRIMARY KEY (last_name, first_name));INSERT IGNORE INTO 会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。
以下实例使用了 INSERT IGNORE INTO,执行后不会出错,也不会向数据表中插入重复数据:
INSERT IGNORE INTO person_tbl (last_name, first_name)VALUES( 'Jay', 'Thomas');INSERT IGNORE INTO person_tbl (last_name, first_name)VALUES( 'Jay', 'Thomas');统计重复数据
以下我们将统计表中 first_name 和 last_name的重复记录数:
SELECT COUNT(*) as repetitions, last_name, first_nameFROM person_tblGROUP BY last_name, first_nameHAVING repetitions > 1;过滤重复数据
在 SELECT 语句中使用 DISTINCT 关键字来过滤重复数据。
SELECT DISTINCT last_name, first_nameFROM person_tbl;你也可以使用 GROUP BY 来读取数据表中不重复的数据:
SELECT last_name, first_nameFROM person_tblGROUP BY (last_name, first_name);删除重复数据
CREATE TABLE tmp SELECT last_name, first_name, sex FROM person_tbl GROUP BY (last_name, first_name, sex);当然你也可以在数据表中添加 INDEX(索引) 和 PRIMAY KEY(主键)这种简单的方法来删除表中的重复记录。方法如下:
ALTER IGNORE TABLE person_tblADD PRIMARY KEY (last_name, first_name);来源地址:https://blog.csdn.net/yi_tong_/article/details/130783050
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341




![[mysql]mysql8修改root密码](https://static.528045.com/imgs/23.jpg?imageMogr2/format/webp/blur/1x0/quality/35)









