

Kubernetes弹性伸缩全场景中如何解析概念延伸与组件布局


Kubernetes弹性伸缩全场景中如何解析概念延伸与组件布局,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
传统弹性伸缩的困境
弹性伸缩是 Kubernetes 中被大家关注的一大亮点,在讨论相关的组件和实现方案之前。首先想先给大家扩充下弹性伸缩的边界与定义,传统意义上来讲,弹性伸缩主要解决的问题是容量规划与实际负载的矛盾。
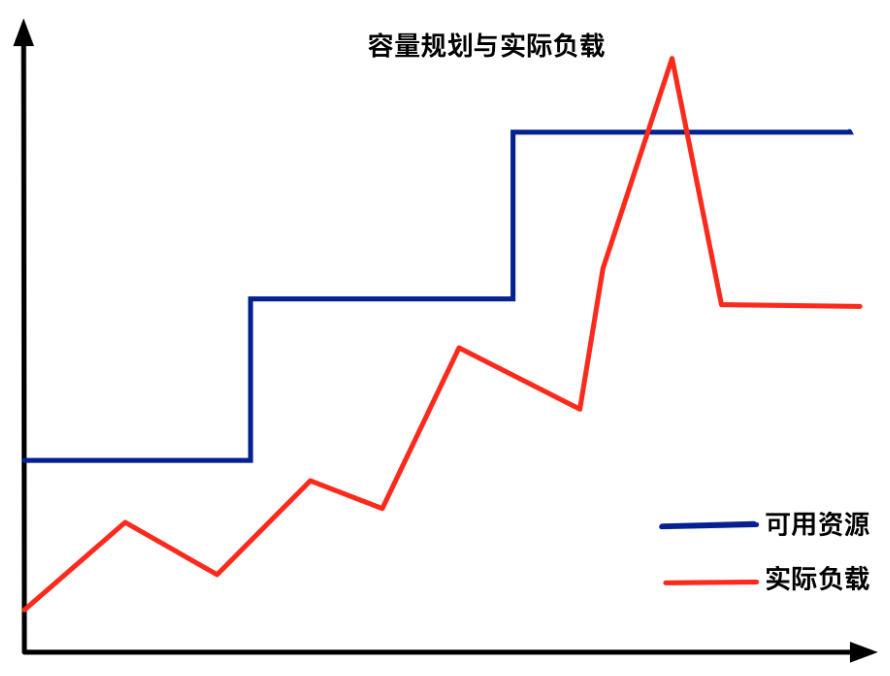
如上图所示,蓝色的水位线表示集群的容量随着负载的提高不断的增长,红色的曲线表示集群的实际的负载真实的变化。而弹性伸缩要解决的就是当实际负载出现激增,而容量规划没有来得及反应的场景。
常规的弹性伸缩是基于阈值的,通过设置一个资源缓冲水位来保障资源的充盈,通常 15%-30% 左右的资源预留是比较常见的选择。换言之就是通过一个具备缓冲能力的资源池用资源的冗余换取集群的可用。
这种方式表面上看是没有什么问题的,确实在很多的解决方案或者开源组件中也是按照这种方式进行实现的,但是当我们深入的思考这种实现方案的时候会发现,这种方式存在如下三个经典问题。
1. 百分比碎片难题
在一个 Kubernetes 集群中,通常不只包含一种规格的机器,针对不同的场景、不同的需求,机器的配置、容量可能会有非常大的差异,那么集群伸缩时的百分比就具备非常大的迷惑性。假设我们的集群中存在 4C8G 的机器与 16C32G 的机器两种不同规格,对于 10% 的资源预留,这两种规格是所代表的意义是完全不同的。
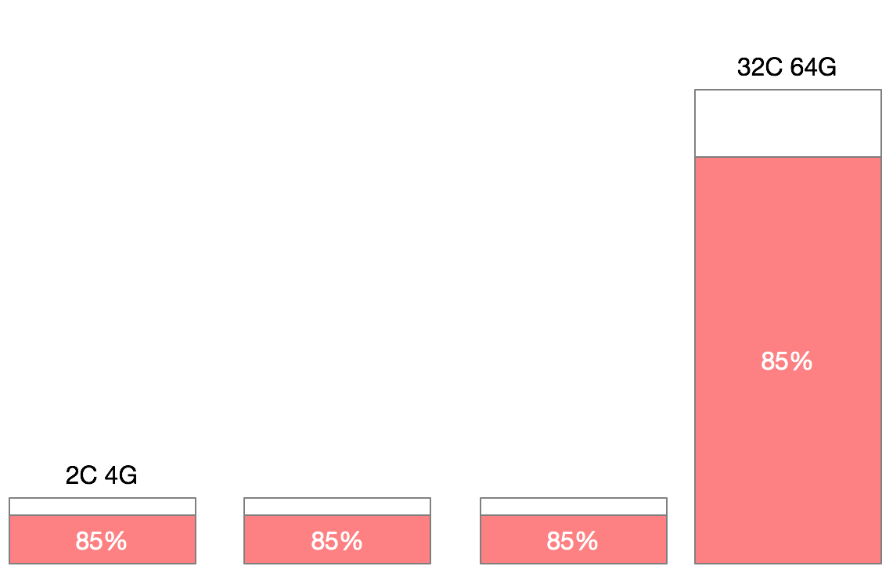
特别是在缩容的场景下,通常为了保证缩容后的集群不处在震荡状态,我们会一个节点一个节点或者二分法来缩容节点,那么如何根据百分比来判断当前节点是处在缩容状态就尤为重要,此时如果大规格机器有较低的利用率被判断缩容,那么很有可能会造成节点缩容后,容器重新调度后的争抢饥饿。如果添加判断条件,优先缩容小配置的节点,则有可能造成缩容后资源的大量冗余,最终集群中可能会只剩下所有的巨石节点。
2. 容量的规划炸弹
还记得在没有使用容器前,是如何做容量规划的吗?一般会按照应用来进行机器的分配,例如,应用 A 需要 2 台 4C8G 的机器,应用 B 需要 4 台 8C16G 的机器,应用 A 的机器与应用 B 的机器是独立的,相互不干扰。到了容器的场景中,大部分的开发者无需关心底层的资源了,那么这个时候容量规划哪里去了呢?
在 Kubernetes 中是通过 Request 和 Limit 的方式进行设置,Request 表示资源的申请值,Limit 表示资源的限制值。既然 Request 和 Limit 才是容量规划的对等概念,那么这就代表着资源的实际计算规则要根据 Request 和 Limit 才更加准确。而对于每个节点预留资源阈值而言,很有可能会造成小节点的预留无法满足调度,大节点的预留又调度不完的场景。
3. 资源利用率困境
集群的资源利用率是否可以真的代表当前的集群状态呢?当一个 Pod 的资源利用率很低的时候,不代表就可以侵占它所申请的资源。在大部分的生产集群中,资源利用率都不会保持在一个非常高的水位,但从调度来讲,资源的调度水位应该保持在一个比较高的水位。这样才能既保证集群的稳定可用,又不过于浪费资源。
如果没有设置 Request 与 Limit,而集群的整体资源利用率很高这意味着什么?这表示所有的 Pod 都在被以真实负载为单元进行调度,相互之间存在非常严重的争抢,而且简单的加入节点也丝毫无法解决问题,因为对于一个已调度的 Pod 而言,除了手动调度与驱逐之外没有任何方式可以将这个 Pod 从高负载的节点中移走。那如果我们设置了 Request 与 Limit 而节点的资源利用率又非常高的时候说明了什么呢?很可惜这在大部分的场景下都是不可能的,因为不同的应用不同的负载在不同的时刻资源的利用率也会有所差异,大概率的情况是集群还没有触发设置的阈值就已经无法调度 Pod 了。
弹性伸缩概念的延伸
既然基于资源利用率的弹性伸缩有上述已知的三个问题,有什么办法可以来解决呢?随着应用类型的多样性发展,不同类型的应用的资源要求也存在越来越大的差异。弹性伸缩的概念和意义也在变化,传统理解上弹性伸缩是为了解决容量规划和在线负载的矛盾,而现在是资源成本与可用性之间的博弈。如果将常见的应用进行规约分类,可以分为如下四种不同类型:
1. 在线任务类型
比较常见的是网站、API 服务、微服务等常见的互联网业务型应用,这种应用的特点是对常规资源消耗较高,比如 CPU、内存、网络 IO、磁盘 IO 等,对于业务中断容忍性差。
2. 离线任务类型
例如大数据离线计算、边缘计算等,这种应用的特点是对可靠性的要求较低,也没有明确的时效性要求,更多的关注点是成本如何降低。
3. 定时任务类型
定时运行一些批量计算任务是这种应用的比较常见形态,成本节约与调度能力是重点关注的部分。
4. 特殊任务类型
例如闲时计算的场景、IOT 类业务、网格计算、超算等,这类场景对于资源利用率都有比较高的要求。
单纯的基于资源利用率的弹性伸缩大部分是用来解决第一种类型的应用而产生的,对于其他三种类型的应用并不是很合适,那么 Kubernetes 是如何解决这个问题的呢?
Kubernetes 的弹性伸缩布局
Kubernetes 将弹性伸缩的本质进行了抽象,如果抛开实现的方式,对于不同应用的弹性伸缩而言,该如何统一模型呢? Kubernetes 的设计思路是将弹性伸缩划分为保障应用负载处在容量规划之内与保障资源池大小满足整体容量规划两个层面。简单理解,当需要弹性伸缩时,优先变化的应该是负载的容量规划,当集群的资源池无法满足负载的容量规划时,再调整资源池的水位保证可用性。而两者相结合的方式是无法调度的 Pod 来实现的,这样开发者就可以在集群资源水位较低的时候使用 HPA、VPA 等处理容量规划的组件实现实时极致的弹性,资源不足的时候通过 Cluster-Autoscaler 进行集群资源水位的调整,重新调度,实现伸缩的补偿。两者相互解耦又相互结合,实现极致的弹性。
在 Kubernetes 的生态中,在多个维度、多个层次提供了不同的组件来满足不同的伸缩场景。如果我们从伸缩对象与伸缩方向两个方面来解读 Kubernetes 的弹性伸缩的话,可以得到如下的弹性伸缩矩阵。
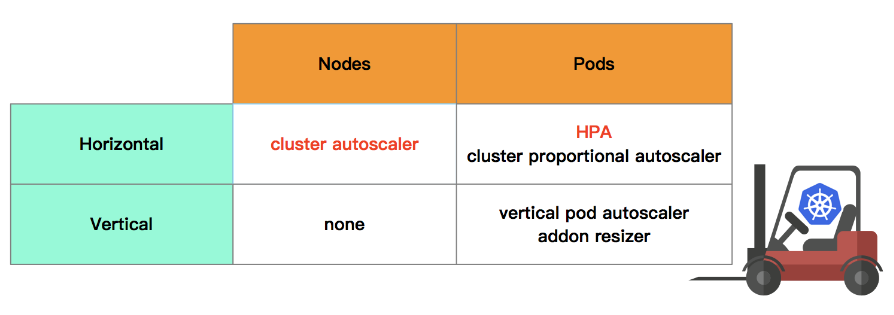
cluster-autoscaler: kubernetes 社区中负责节点水平伸缩的组件,目前处在 GA 阶段 (General Availability, 即正式发布的版本)。
HPA: kubernetes 社区中负责 Pod 水平伸缩的组件,是所有伸缩组件中历史最悠久的,目前支持
autoscaling/v1、autoscaling/v2beta1与autoscaling/v2beta2, 其中autoscaling/v1只支持 CPU 一种伸缩指标,在autoscaling/v2beta1中增加支持 custom metrics,在autoscaling/v2beta2中增加支持 external metrics。cluster-proportional-autoscaler: 根据集群的节点数目,水平调整 Pod 数目的组件,目前处在 GA 阶段。
vetical-pod-autoscaler: 根据 Pod 的资源利用率、历史数据、异常事件,来动态调整负载的 Request 值的组件,主要关注在有状态服务、单体应用的资源伸缩场景,目前处在 beta 阶段。
addon-resizer: 根据集群中节点的数目,纵向调整负载的 Request 的组件,目前处在 beta 阶段。
在这五个组件中, cluster-autoscaler、 HPA、 cluster-proportional-autoscaler 是目前比较稳定的组件,建议有相关需求的开发者进行选用。
对于百分之八十以上的场景,我们建议客户通过 HPA 结合 cluster-autoscaler 的方式进行集群的弹性伸缩管理, HPA 负责负载的容量规划管理而 cluster-autoscaler 负责资源池的扩容与缩容。
看完上述内容,你们掌握Kubernetes弹性伸缩全场景中如何解析概念延伸与组件布局的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注编程网行业资讯频道,感谢各位的阅读!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












