

Python如何破解反爬虫

本篇文章给大家分享的是有关Python如何破解反爬虫,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
通过用JS在本地生成随机字符串的反爬虫机制,在利用Python写爬虫的时候经常会遇到的一个问题。
破解有道翻译反爬虫机制
web端的有道翻译,在之前是直接可以爬的。也就是说只要获取到了他的接口,你就可以肆无忌惮的使用他的接口进行翻译而不需要支付任何费用。那么自从有道翻译推出他的API服务的时候,就对这个接口做一个反爬虫机制。这个反爬虫机制在爬虫领域算是一个非常经典的技术手段。那么他的反爬虫机制原理是什么?如何破解?接下来带大家一探究竟。
一、正常的爬虫流程:

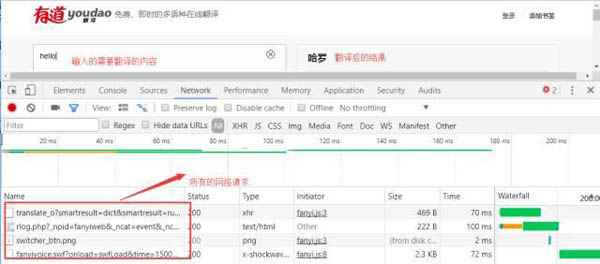
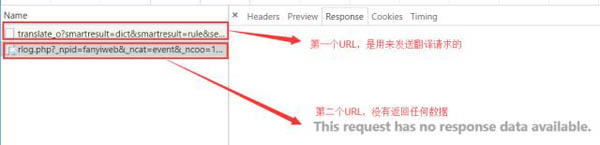
在上图,我们可以看到发送了很多的网络请求,这里我们点击***个网络请求进行查看:


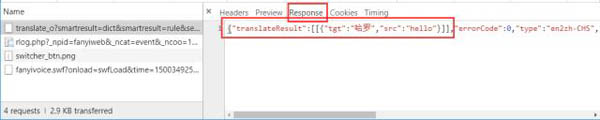

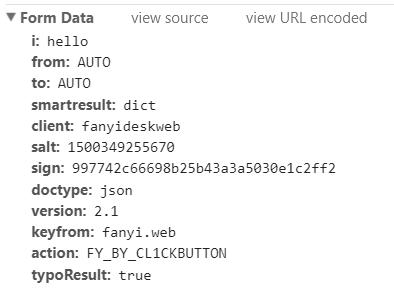
对其中几个比较重要的数据进行解释:

其他的数据类型暂时就不怎么重要了,都是固定写法,我们后面写代码的时候直接鞋子就可以了。到现在为止,我们就可以写一个简单的爬虫,去调用有道翻译的接口了。这里我们使用的网络请求库是Python3自带的urllib,相关代码如下:


二、破解反爬虫机制:

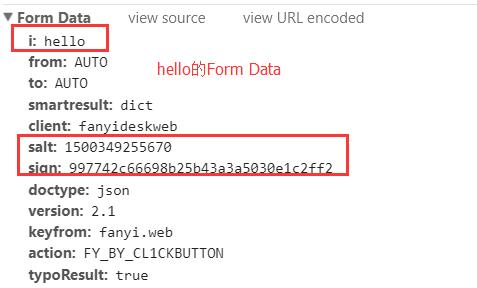



然后把格式化后的代码,复制下来,用sublime或者pycharm打开都可以,然后搜索salt,可以找到相关的代码:
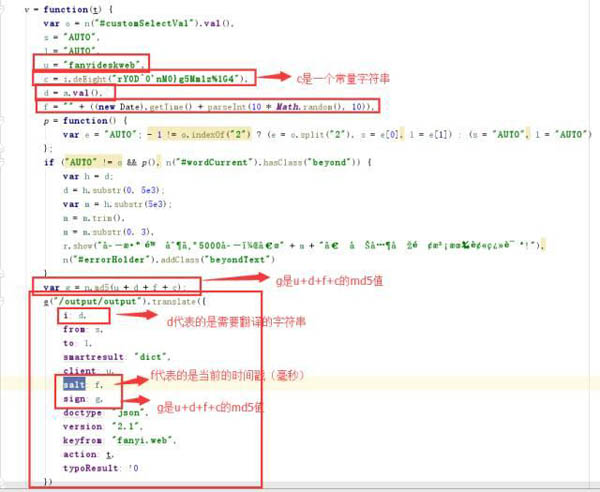

知道salt和sign的生成原理后,我们就可以写Python代码,来对接他的接口了,以下是相关代码:

以上就是Python如何破解反爬虫,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注编程网行业资讯频道。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341













