

【Redis入门篇】| Redis的Java客户端


目录
一: Redis的Java客户端
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/resources/clients/
Jedis:以Redis命令作为方法名称,学习成本低,简单实用。但是Jedis实例是线程不安全的,多线程环境下需要基于连接池来使用。
lettuce:lettuce是基于Netty实现的,支持同步、异步和响应式编程方式,并且是线程安全的。支持Redis的哨兵模式、集群模式和管道模式。
Redission:Redisson是一个基于Redis实现的分布式、可伸缩的Java数据结构集合。包含了诸如Map、Queue、Lock、 Semaphore、AtomicLong等强大功能。
1. Jedis快速入门
Jedis的官网地址: https://github.com/redis/jedis,我们先来个快速入门:
(1)引入依赖
redis.clients jedis 3.7.0 junit junit 4.12 test (2)建立连接:直接alt+insert生成setUp方法
创建Jedis对象,输入IP和port;调用auth()方法输入密码,调用select()方法选择数据库!
@Beforepublic void setUp() throws Exception { // 建立接连 jedis = new Jedis("192.168.2.129",6379); // 设置密码 jedis.auth("123456"); // 选择库 jedis.select(0);}(3)进行操作测试:直接alt+insert生成测试方法,手动修改方法名即可
注:对于Jedis,方法体中所调用的方法,其实就是redis中的命令!
@Testpublic void testString() { // 存数据 String set = jedis.set("name", "张三"); System.out.println("set = " + set); // 取数据 String name = jedis.get("name"); System.out.println("name = " + name);}(4)释放资源:直接alt+insert生成tearDown方法
@Afterpublic void tearDown() throws Exception { if (jedis != null) { jedis.close(); }}具体代码:
package com.zl.jedis;import org.junit.After;import org.junit.Before;import org.junit.Test;import redis.clients.jedis.Jedis;public class JedisTest { private Jedis jedis; // 建立连接 @Before public void setUp() throws Exception { // 建立接连 jedis = new Jedis("192.168.2.129",6379); // 设置密码 jedis.auth("123456"); // 选择库 jedis.select(0); } // 操作 @Test public void testString() { // 存数据 String set = jedis.set("name", "张三"); System.out.println("set = " + set); // 取数据 String name = jedis.get("name"); System.out.println("name = " + name); } @After public void tearDown() throws Exception { if (jedis != null) { jedis.close(); } }}执行结果:

2. Jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此推荐大家使用Jedis连接池代替Jedis的直连方式!
①首先定义一个工具类JedisConnectionFactory类,用来获取Jedis连接池对象;
②定义一个静态的成员变量JedisPool(jedis连接池);
③在静态代码块中,创建JedisPoolConfig对象(jedis的一些配置),并配置一些基本信息;
④创建jedis连接池对象JedisPool,参数就是JedisPoolConfig对象、IP、端口、密码等信息;
⑤最终调用JedisPool对象的getResource方法,获取连接池对象。
package com.zl.util;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;public class JedisConnectionFactory { private static final JedisPool jedisPool; static { // 配置连接池 JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); // 最大连接 jedisPoolConfig.setMaxTotal(8); // 最大空闲连接 jedisPoolConfig.setMaxIdle(8); // 最小空闲连接 jedisPoolConfig.setMinIdle(0); // 设置最长等待时间 jedisPoolConfig.setMaxWaitMillis(1000); // 创建连接池 jedisPool = new JedisPool(jedisPoolConfig, "192.168.2.129", 6379, 1000, "123456"); } // 获取Jedis对象 public static Jedis getJedis() { return jedisPool.getResource(); }}
3. SpringDataRedis快速入门
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:Spring Data Redis
①提供了对不同Redis客户端的整合(Lettuce和Jedis);
②提供了RedisTemplate统一API来操作Redis;
③支持Redis的发布订阅模型;
④支持Redis哨兵和Redis集群;
⑤支持基于Lettuce的响应式编程;
⑥支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化;
⑦支持基于Redis的JDKCollection实现;
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中(相对于直接使用jredis进行分组了):
| API | 返回值类型 | 说明 |
| redisTemplate.opsForValue() | ValueOperations | 操作String类型数据 |
| redisTemplate.opsForHash() | HashOperations | 操作Hash类型数据 |
| redisTemplate.opsForList() | ListOperations | 操作List类型数据 |
| redisTemplate.opsForSet() | SetOperations | 操作Set类型数据 |
| redisTemplate.opsForZSet() | ZSetOperations | 操作SortedSet类型数据 |
| redisTemplate | 通用的命令 |
SpringBoot已经提供了对SpringDataRedis的支持,SpringDataRedis的使用步骤:
①引入spring-boot-starter-data-redis起步依赖;
②在application.yml配置Redis信息;
③注入RedisTemplate;
(1)引入依赖
org.springframework.boot spring-boot-starter-data-redis org.apache.commons commons-pool2 (2)application.yml配置文件
注:Spring默认引入的是lettuce,要想使用jedis还要引入jedis的依赖;但是无论是lettuce还是jedis都是基于连接池创建连接的,所以需要前面的commons-pool2连接池依赖。
spring: redis: host: 192.168.2.129 port: 6379 password: 123456 lettuce: pool: max-active: 8 #最大连接 max-idle: 8 #最大空闲连接 min-idle: 0 #最小空闲连接 max-wait: 100 #连接等待时间(3)注入RedisTemplate并测试
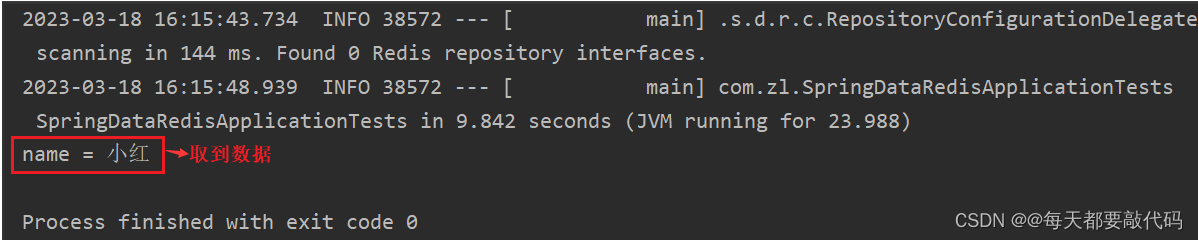
package com.zl;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.redis.core.RedisTemplate;@SpringBootTestclass SpringDataRedisApplicationTests { // 注入RedisTemplate @Autowired private RedisTemplate redisTemplate; @Test void testString() { // 插入数据,参数不仅仅是字符串,Java对象也可以 redisTemplate.opsForValue().set("name","小红"); // 获取数据 Object name = redisTemplate.opsForValue().get("name"); System.out.println("name = " + name); }}执行结果:
4. RedisSerializer配置
SpringDataRedis的序列化方式:RedisTemplate可以接收任意Object作为值写入Redis,只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:
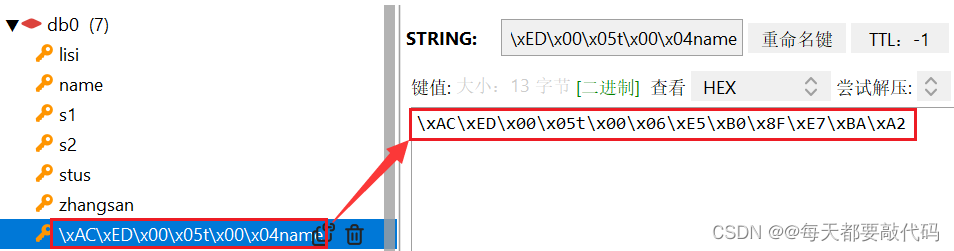
实际上这个key和value就是我们前面存入的小红(序列化后的结果);SpringDataRedis可以接收任何对象,怎么实现的?就是通过对象的数据进行序列化及反序列化!
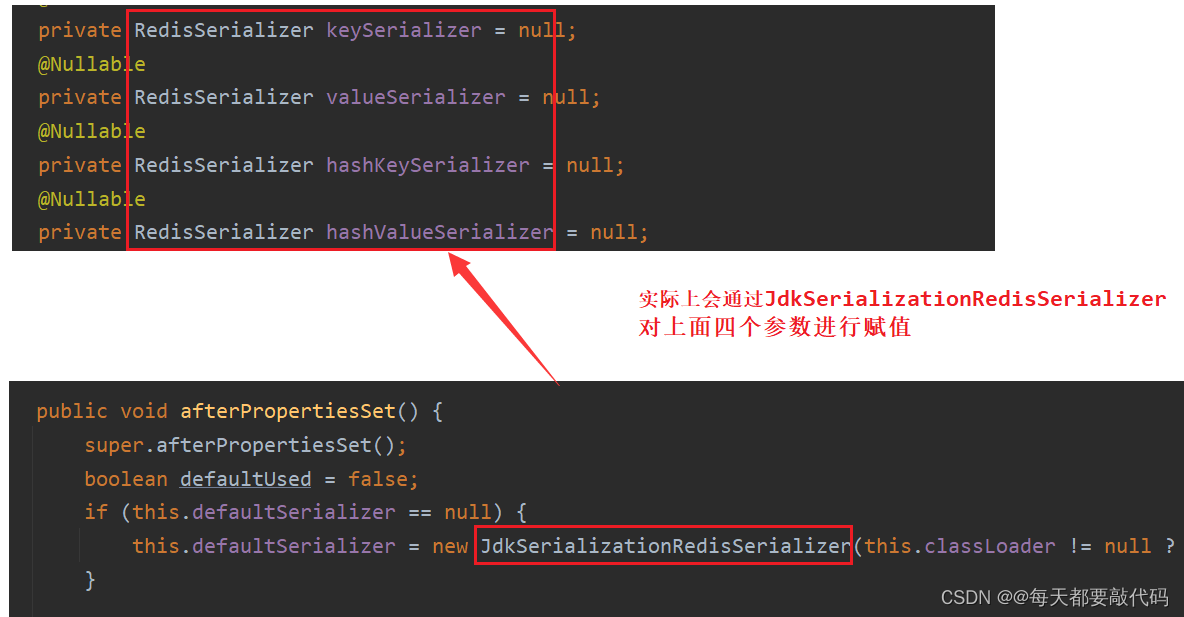
从哪里可以看出是使用了JDK的序列化方式
缺点:
①可读性差;
②内存占用较大;
有其它的序列化方式吗?
①JdkSerializationRedisSerializer:使用JDK的序列化方式,前面我们已经用过了!
②StringRedisSerializer:专门处理字符串的类型,例如key基本上都是字符串!
③GenericJackson2JsonRedisSerializer:如果value是对象,建议使用这个!
怎样做到,所存即所得呢?我们可以自定义RedisTemplate的序列化方式,代码如下:
package com.zl.config;import org.springframework.boot.autoconfigure.condition.ConditionalOnSingleCandidate;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.redis.connection.RedisConnectionFactory;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;import org.springframework.data.redis.serializer.RedisSerializer;@Configurationpublic class RedisConfig { @Bean public RedisTemplate redisTemplate(RedisConnectionFactory connectionFactory){ // 创建RedisTemplate对象 RedisTemplate template = new RedisTemplate<>(); // 连接工厂,这个工厂springboot会帮我们创建好 template.setConnectionFactory(connectionFactory); // 创建JSON序列化工具 GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer(); // 设置key的序列化方式 template.setKeySerializer(RedisSerializer.string()); template.setHashKeySerializer(RedisSerializer.string()); // 设置value的序列化方式 template.setValueSerializer(jsonRedisSerializer); template.setHashValueSerializer(jsonRedisSerializer); // 返回 return template; }} 其中RedisSerializer的string()方法就是使用了StringRedisSerializer的一个常量

因为使用了JSON序列化工具,所以还要引入JSON依赖
com.fasterxml.jackson.core jackson-databind 再次进行测试
package com.zl;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.redis.core.RedisTemplate;@SpringBootTestclass SpringDataRedisApplicationTests { // 注入RedisTemplate @Autowired private RedisTemplate redisTemplate; // 引用泛型 @Test void testString() { // 插入数据,参数不仅仅是字符串,Java对象也可以 redisTemplate.opsForValue().set("name","小红"); // 获取数据 Object name = redisTemplate.opsForValue().get("name"); System.out.println("name = " + name); }} 执行结果:

思考:如果使用Java对象呢?
给定一个User对象
package com.zl.pojo;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;// 使用以下注解需要引入lombok依赖@Data // setter and getter@NoArgsConstructor // 无参构造@AllArgsConstructor // 有参构造public class User { private String name; private Integer age; }进行测试
package com.zl;import com.zl.pojo.User;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.redis.core.RedisTemplate;@SpringBootTestclass SpringDataRedisApplicationTests { // 注入RedisTemplate @Autowired private RedisTemplate redisTemplate; // 引用泛型 @Test void testSaveUser() { // 插入数据 redisTemplate.opsForValue().set("user",new User("张三",18)); // 取出数据 User user = (User) redisTemplate.opsForValue().get("user"); System.out.println("user = " + user); }}执行结果:
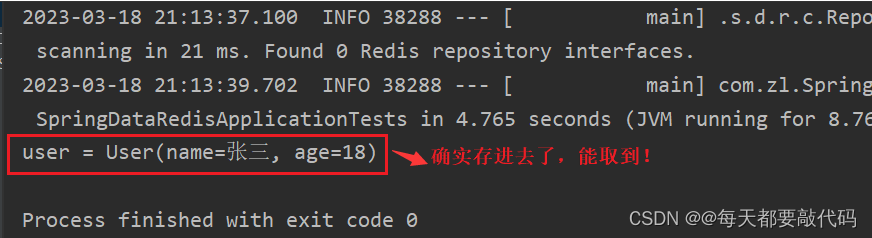
图形界面客户端:
自动的把Java对象转换为JSON写入,当获取结果的时候也能反序列化为User对象;实际上在写入JSON的同时,把User的字节码名称也写进去了com.zl.pojo.User,通过这个属性在反序列化的时候转换成User对象!
注:为了在反序列化时知道对象的类型,不仅仅写了User对象的属性,还把类的class类型写入了Json结果中,存入redis,会带来额外的内存开销。
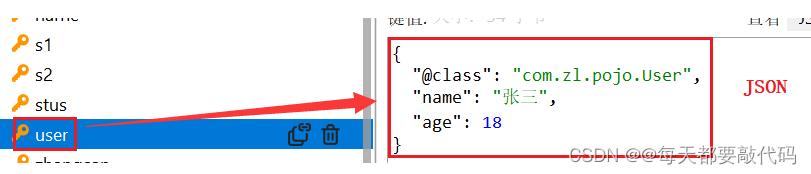
5. StringRedisTemplate
为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器 ,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化!

Spring默认提供了一个StringRedisTemplate类,它的key和value的序列化方式默认就是String方式。省去了我们自定义RedisTemplate的过程!
所以,现在最重要的就是处理Java对象,手动序列化和反序列
(1)使用JSON工具ObjectMapper(SpringMVC处理Json工具):调用ObjectMapper对象的writeValuesString()方法手动完成序列化,转换成json格式的字符串存入redis;调用ObjectMapper对象的readValue()方法手动完成反序列化,转换成Java对象!
(2)也可以使用fastjson是阿里巴巴的开源JSON解析库,需要引入fastjon依赖。然后调用JSON的toJSONString()方法,转换成json格式的字符串;调用JSON的parseObject()方法,转换成Java对象!
package com.zl;import com.alibaba.fastjson.JSON;import com.fasterxml.jackson.core.JsonProcessingException;import com.fasterxml.jackson.databind.ObjectMapper;import com.zl.pojo.User;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.redis.core.StringRedisTemplate;@SpringBootTestclass ApplicationTest { // 注入StringRedisTemplate @Autowired private StringRedisTemplate stringredisTemplate; // JSON工具 private static final ObjectMapper mapper = new ObjectMapper(); // ObjectMapper是SpringMVC处理Json的工具 // fastjson是阿里巴巴的开源JSON解析库 @Test void testString() { // 对于普通字符串步骤不变 stringredisTemplate.opsForValue().set("name","小红"); Object name = stringredisTemplate.opsForValue().get("name"); System.out.println("name = " + name); } @Test void testSaveUser() throws JsonProcessingException { // 对于Java对象加上手动转步骤 // 准备Java对象 User user = new User("虎哥", 18); // 手动序列化 // String json = mapper.writeValueAsString(user); // 把Java对象转换成Json格式的字符串 String json = JSON.toJSONString(user); // 写入redis stringredisTemplate.opsForValue().set("user",json); // 读取数据 String val = stringredisTemplate.opsForValue().get("user"); // 读出来的是Json格式的字符串 // 反序列化 // User user1 = mapper.readValue(val, User.class); User user1 = JSON.parseObject(val, User.class); System.out.println("user1 = " + user1); }}执行结果:
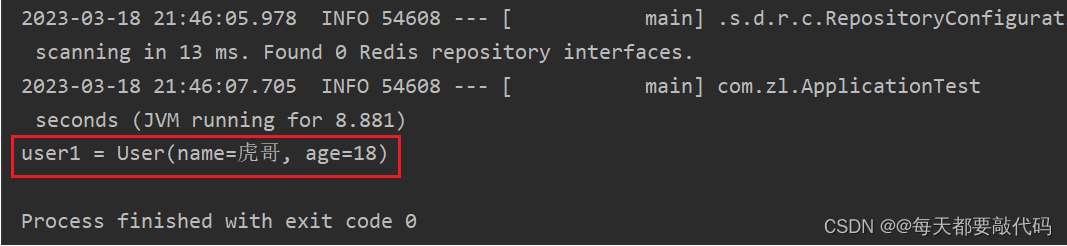
图形界面客户端:
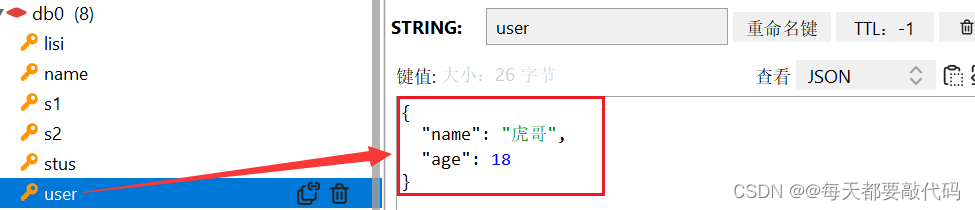
补充:对于其它类型结构可能就更偏向于JavaAPI的编写方式,例如:Hash结构
①对于存数据,不是使用hset()方法,在Spring中不是以命令名作为方法名,因为类似于Java中的HashMap结构,所以方法名与HashMap结构的保持一致,使用put()方法进行存取。
②对于取数据,不使用hget,使用的是get()方法取单个,如果取多个使用entrys()方法。
@Testvoid testHash() { // 插入数据 stringredisTemplate.opsForHash().put("user:100","name","张三"); stringredisTemplate.opsForHash().put("user:100","age","18"); // 取出数据 Object name = stringredisTemplate.opsForHash().get("user:100", "name"); // 取一个 Map entries = stringredisTemplate.opsForHash().entries("user:100"); System.out.println("entries = " + entries); // 取所有} 总结RedisTemplate的两种序列化实践方案:
方案一:
①自定义RedisTemplate
②修改RedisTemplate的序列化器为GenericJackson2JsonRedisSerializer
方案二:
①使用StringRedisTemplate
②写入Redis时,手动把对象序列化为JSON;读取Redis时,手动把读取到的JSON反序列化为对象
图书推荐
本期图书:《元宇宙Ⅱ:图解元技术区块链、元资产与Web3.0、元人与理想国(全三册)》、《产业链金融平台设计与实现》
参与方式:
本次送书 1 本(二选一哦)!
活动时间:截止到 2023-05-09 00:00:00。抽奖方式:利用程序进行抽奖。
参与方式:关注博主(只限粉丝福利哦)、点赞、收藏,评论区随机抽取,最多三条评论!
看半小时漫画,通元宇宙未来100年,300幅手绘插图轻松读懂虚实共生的未来世界。剖析元宇宙三大定律、大统一方程、熵增定律、Web3.0、万亿元资产、元人与区块链文明,构建元宇宙大楼。讲透元技术区块链、元宇宙基石Web3.0到穿越未来的技术大革命。厘清8大产业规律和11大投资方向,从元宇宙经济学到财富自由2.0,构建NO.1无限∞世界的数字空间,从元人到理想国。
这是一个全新的时代:Web3.0构建的经济体系,DID身份的跨平台操作,数字NFT的原子级镜像,以及DeFi的无摩擦元资产再分配......2022年,奇点出现:元人即将诞生;元资产即将分配;元宇宙正在成形。本套书通过元宇宙三大定律、大统一方程、熵增定律、Web3.0、万亿元资产、元人与区块链文明构建了元宇宙第一大楼。第1-80层:数字人展位、电子宠物、数字藏品、3D沉侵式旅游、DeFi。第81-160层:AI、VR、AR、MR、DAO、Web3.0、边缘计算。第161-214+层:多场景阅读、4K空间、跨链许可、维度转换、无限∞世界。

当当自营购买链接:http://product.dangdang.com/29513251.html
本书从产业链金融的起源讲起,结合实际案例讲解产业链金融平台的前台设计、技术中台设计、数据平台设计、风控设计及信息安全的核心要点,既体现了传统行业的业务创新、数字转型的探索过程,又介绍了当前主流银行的开放性建设成果。读者不但能全方位地了解产业链金融平台的建设过程,还能针对自己感兴趣的方面进行深入学习。
本书共6章,第1章介绍了产业链金融的发展、变革历程,以及对传统企业的核心价值;第2章介绍了系统核心功能的设计及在线签约、实名认证等技术的原理;第3章介绍了结合容器云技术、微服务技术与DevOps技术构建技术中台的过程,以及对接开放银行、央行征信的过程;第4章介绍了开源大数据平台的建设及数据仓库的设计思路;第5章基于Python的机器学习库介绍了智能风控的开发过程;第6章介绍了在产业链金融平台建设过程中如何规避信息安全的法律风险。
本书内容全面,且围绕开源技术展开介绍,实用性极强,特别适合建设产业链金融平台的传统企业架构师、开发人员及产品人员阅读,也适合对开源的技术中台、大数据平台及信用风控感兴趣的开发人员阅读。

京东自营购买链接:https://item.jd.com/13797946.html
来源地址:https://blog.csdn.net/m0_61933976/article/details/129635937
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
















