

数据库面试题总结


一、索引相关
(1)什么是索引?
索引是一种数据结构,可以帮助我们快速的进行数据的查找。
(2)索引是个什么样的数据结构呢?
索引的数据结构和具体存储引擎的实现有关,在 MySQL 中使用较多的索引有 Hash 索引,B+ 树索引等
(3)为什么使用索引?
可以大大加快数据的检索速度
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
将随机IO变为顺序IO。
可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
(4)主键和索引的区别?
主键、外键及约束的作用:保证数据的完整性
索引的作用:索引是一个数据结构,用来快速访问数据库表格或者视图里的数据,加快数据库的搜索引擎对数据的检索效率;
(5)说一说索引的底层实现?
Hash索引
基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。
(6)索引有哪些优缺点?
索引的优点
可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
索引的缺点
时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率;
空间方面:索引需要占物理空间。
(7)联合索引是什么?
MySQL 可以使用多个字段同时建立一个索引,叫做联合索引
(8)MySQL索引种类
普通索引
唯一索引(主键索引、唯一索引)
联合索引
全文索引
空间索引
(9)索引的基本原理
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。
索引的原理很简单,就是把无序的数据变成有序的查询
把创建了索引的列的内容进行排序
二、事务相关
(1)什么是事务?
事务(Transaction)指的是一个操作序列,该操作序列中的多个操作要么都做,要么都不做,是一个不可分割的工作单位,是数据库环境中的逻辑工作单位
(2)ACID是什么?可以详细说一下吗?
https://blog.csdn.net/YZL40514131/article/details/120952001
(3)MySQL中为什么要有事务回滚机制?
恢复机制是通过回滚日志实现的,所有事务进行的修改都会先记录到这个回滚日志中,然后在对数据库中的对应行进行写入。当事务已经被提交之后,就无法再次回滚了。
在整个系统发生崩溃、数据库进程直接被杀死后,当用户再次启动数据库进程时,还能够立刻通过查询回滚日志将之前未完成的事务进行回滚,这也就需要回滚日志必须先于数据持久化到磁盘上,是我们需要先写日志后写数据库的主要原因。
(4)数据库并发事务会带来哪些问题?
https://blog.csdn.net/YZL40514131/article/details/120955265
(5)不可重复读和幻读区别是什么?可以举个例子吗?
https://blog.csdn.net/YZL40514131/article/details/120955265
三、锁相关
(1)对 MySQL 的锁了解吗?
当数据库有并发事务的时候,可能会产生数据的不一致,这时候需要一些机制来保证访问的次序,锁机制就是这样的一个机制
就像酒店的房间,如果大家随意进出,就会出现多人抢夺同一个房间的情况,而在房间上装上锁,申请到钥匙的人才可以入住并且将房间锁起来,其他人只有等他使用完毕才可以再次使用.
(2)MySQL 锁的分类
按照 锁的粒度 划分可以分成:
行锁
表锁
页锁
按照 使用的方式 划分可以分为:
共享锁
排它锁
按照 思想 的划分:
乐观锁
悲观锁
(3)行级锁、表级锁、页级锁的描述与特点
行级锁:
描述:行级锁是mysql中锁定粒度最细的一种锁。表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突,其加锁粒度最小,但加锁的开销也最大。
特点:开销大,加锁慢,会出现死锁。发生锁冲突的概率最低,并发度也最高。
表级锁:
描述:表级锁是mysql中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分mysql引擎支持。
特点: 开销小,加锁快,不会出现死锁。发生锁冲突的概率最高,并发度也最低。
页级锁:
描述:页级锁是 MySQL 中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。
特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
(4)什么是死锁?
是指二个或者二个以上的进程在执行时候,因为争夺资源造成相互等待的现象,进程一直处于等待中,无法得到释放,这种状态就叫做死锁。
(5)死锁出现的案列?
批量入库,存在则更新,不存在则插入
(6)如何处理死锁?
发起死锁检测,发现死锁之后,主动回滚死锁中的事务,不需要其他事务继续
设置超时时间,一直等待直到超时
四、存储引擎相关
(1)说一下MySQL是如何执行一条SQL的?具体步骤有哪些?(*)
客户端请求->
2.连接器(验证用户身份,给予权限) ->
3.查询缓存(存在缓存则直接返回,不存在则执行后续操作)->
4.分析器(对SQL进行词法分析和语法分析操作) ->
5.优化器(主要对执行的sql优化选择最优的执行方案方法) ->
6.执行器(执行时会先看用户是否有执行权限,有才去使用这个引擎提供的接口)->
7.去引擎层获取数据返回(如果开启查询缓存则会缓存查询结果)
简单概括:
连接器:管理连接、权限验证;
查询缓存:命中缓存则直接返回结果;
分析器:对SQL进行词法分析、语法分析;(判断查询的SQL字段是否存在也是在这步)
优化器:执行计划生成、选择索引;
执行器:操作引擎、返回结果;
存储引擎:存储数据、提供读写接口。
(2)SQL 的执行顺序?
select distinct
from
left join
on
where
group by
having
ording by
desc
limit
(3)简述触发器、函数、视图、存储过程?
触发器:使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,触发器无法由用户直接调用,而知由于对表的【增/删/改】操作被动引发的
函数:是MySQL数据库提供的内部函数(当然也可以自定义函数)。这些内部函数可以帮助用户更加方便-的处理表中的数据
视图:视图是虚拟表或逻辑表,它被定义为具有连接的SQL SELECT查询语句。
存储过程:存储过程是存储在数据库目录中的一坨的声明性SQL语句,数据库中的一个重要对象,有效提高了程序的性能
(4)听说过视图吗?那游标呢?
视图是一种虚拟的表,通常是有一个表或者多个表的行或列的子集,具有和物理表相同的功能 游标是对查询出来的结果集作为一个单元来有效的处理。
视图本质上就是:一个查询语句,是一个虚拟的表,不存在的表,你查看视图,其实就是查看视图对应的sql语句
一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
(5)视图的作用是什么?可以更改吗?
https://blog.csdn.net/YZL40514131/article/details/120956605
简化用户操作:视图可以使用户将注意力集中在所关心地数据上,而不需要关心数据表的结构、与其他表的关联条件以及查询条件等。
视图主要用于简化检索,保护数据,并不用于更新,而且大部分视图都不可以更新。
五、表结构相关
(1)为什么要尽量设定一个主键?
1、提高数据的检索速度;
2、保证数据的唯一性;
3、保证实体的完整性;
(2)字段为什么要求定义为not null?
https://blog.csdn.net/QiuHaoqian/article/details/115624288
(3)如果要存储用户的密码散列,应该使用什么字段进行存储?
密码散列,盐,用户身份证号等固定长度的字符串应该使用 char 而不是 varchar 来存储,这样可以节省空间且提高检索效率。
(4)说一说Drop、Delete与Truncate的共同点和区别?
Drop直接删掉表;
Truncate删除表中数据,再插入时自增长id又从1开始 ;
Delete删除表中数据,可以加where字句
(5)数据库中的主键、超键、候选键、外键是什么?
主键为候选键的子集,候选键为超键的子集,而外键的确定是相对于主键的。
(6)什么是主键?
指一个列或者是多个列的组合,它的值能唯一地标识表中的每一行。
主键是一种特殊的索引,并且是唯一性索引的一种,定义为:PRIMARY KEY
在两个表的关系中,主键用来在一个表中引用来自于另一个表中的特定记录。
主键有那些特点
1、一个表中只能有一个主键;
2、主键可以是一个字段,也可以是多个字段组成主键;
3、设置为主键的字段不能重复;
4、设置为主键的字段不能为空;
主键的优势
1、提高数据的检索速度;
2、保证数据的唯一性;
3、保证实体的完整性;
(7)什么是外键?
主键、外键、索引的区别
定义:
主键:唯一标识一条记录,不能有重复的,不允许为空
外键:表的外键是另一表的主键, 外键可以有重复的, 可以是空值
索引:该字段没有重复值,但可以有一个空值
作用:
主键:用来保证数据完整性
外键:用来和其他表建立联系用的
索引:是提高查询排序的速度
个数:
主键:主键只能有一个
外键:一个表可以有多个外键
索引:一个表可以有多个唯一索引
六、其他问题
(1)MySQL 中的 varchar 和 char 有什么区别?
1、最大长度:
char最大长度是255个字符,varchar最大长度是65535个字符。
2、char是定长的,不足的部分会用隐藏空格填充,varchar是不定长的。
当向char中插入数据时,如果该数据小于定义的长度,那么就会用空格填充不足的部分;
当向varchar中插入数据时,如果数据小于定义的长度,那么按数据的实际长度存储,即插入多长就存多长;当要存储的数据的实际长度大于定义的长度时,会对该数据进行自动截取。
3、空间使用:
char会浪费空间,varchar会更加节省空间。
4、查找效率:
char查找效率会很高,varchar查找效率会更低。
因为char的长度固定,故char的存取速度还是要比varchar快得多,存储与查找会更加方便;但是char也为此付出了空间的代价,因为其长度固定,所以会占据多余的空间,可谓是以空间换取时间效率。varchar则刚好相反,是以时间换空间,存储与查找相比于char效率更低一些。
5、尾部空格:
char插入时可省略,varchar插入时不会省略,但查找时省略。
(2)varchar(10) 和 int(10) 代表什么含义?
首先int(10)的10表示显示的数据的长度,不是存储数据的大小;
varchar(10)的10表示存储数据的大小,即表示存储多少个字符。
(3)left join、right join以及inner join的区别?
left join:左关联,主表在左边,右边为从表。如果左侧的主表中没有关联字段,会用null 填满
right join:右关联 主表在右边和letf join相反
inner join: 内关联只会显示主表和从表相关联的字段,不会出现null
(4)什么是数据库约束,常见的约束有哪几种?
数据库约束用于保证数据库、表数据的完整性(正确性和一致性)。
可以通过定义约束\索引\触发器来保证数据的完整性。总体来讲,约束可以分为:
主键约束:primary key;
外键约束:foreign key;
唯一约束:unique;
检查约束:check;
空值约束:not null;
默认值约束:default;
(5)MySQL数据库cpu飙升的话,要怎么处理呢?
排查过程:
使用top 命令观察,确定是mysqld导致还是其他原因。
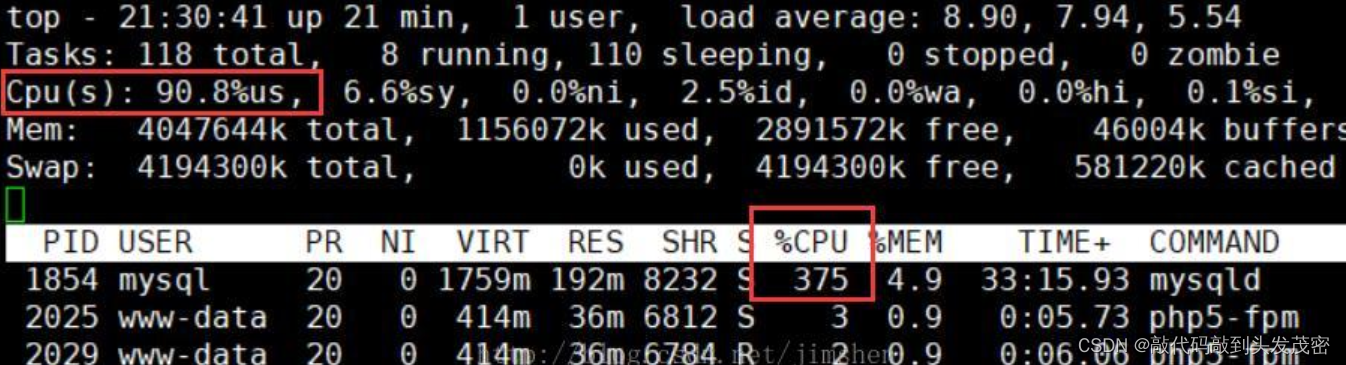
在服务器上执行mysql -u root -p之后,输入show full processlist; 可以看到正在执行的语句。
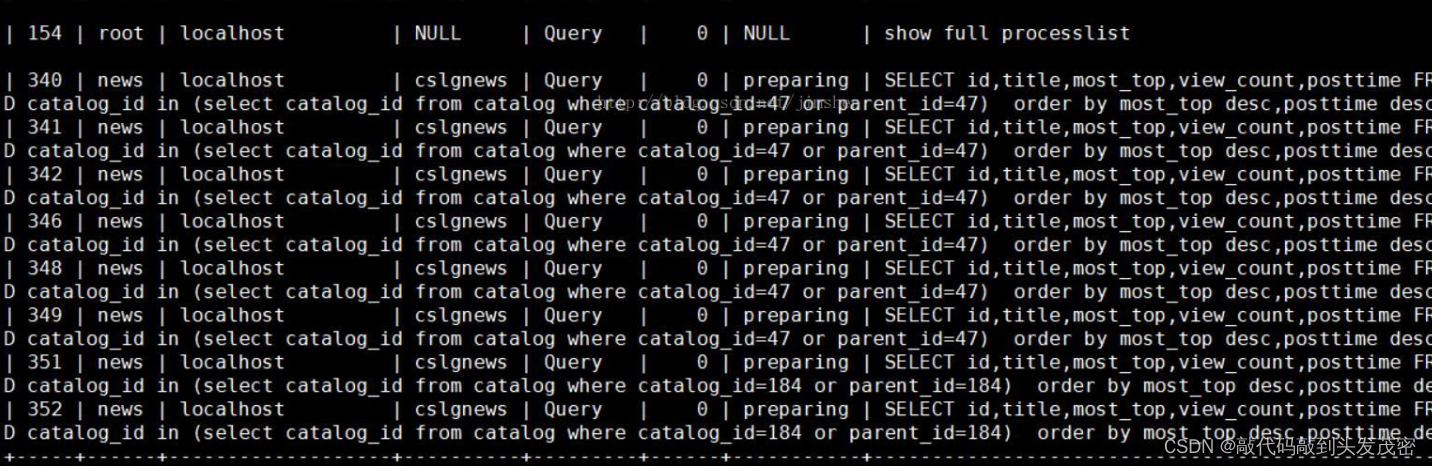
找出消耗高的 sql,看看执行计划是否准确, 索引是否缺失,数据量是否太大。
处理:
kill 掉这些线程(同时观察 cpu 使用率是否下降),
进行相应的调整(比如说加索引、改 sql(首先是缩减查询范围)、改内存参数)
重新跑这些 SQL。
(6)count(1)、count(*)与count(列名)的执行区别
count(*) :统计所有的行数,包括为null的行(COUNT(*)不单会进行全表扫描,也会对表的每个字段进行扫描。
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL。
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空。
(7)sql中null与空值的区别
占用空间区别:空值(’’)的长度是0,是不占用空间的;而的NULL长度是NULL,是占用空间的
2.插入/查询方式区别:NULL值查询使用is null/is not null查询,而空值(’’)可以使用=或者!=、<、>等算术运算符。
3.COUNT 和 IFNULL函数:使用 COUNT(字段) 统计会过滤掉 NULL 值,但是不会过滤掉空值。
(8)关系型和非关系型数据库的区别?
1.数据存储方式:非关系型数据库的存储方式是KEY-VALUE的形式、文档等形式,而关系型数据库只支持单一的存储方式。
2.查询效率:关系型数据库存储于磁盘,非关系型数据库存储于缓存,效率比关系型数据库更高。
3.事务:关系型数据库支持事务处理,可进行事务回滚。
4.成本:非关系型数据库基本是开源的,不需要像oracle花费大量的成本购买
(9)如何防范SQL注入式攻击?
https://blog.csdn.net/YZL40514131/article/details/127169680
七、优化相关
(1)表结构优化
数字类型:
(1)非万不得已不要使用DOUBLE,不仅仅只是存储长度的问题,同时还会存在精确性的问题。
2、字符类型:
(1)非万不得已不要使用 TEXT 数据类型,其处理方式决定了他的性能要低于char或者是varchar类型的处理。
(2)对于定长字段,建议使用 CHAR 类型,不定长字段尽量使用 VARCHAR,且设定适当的最大长度,而不是非常随意的给一个很大的最大长度限定,因为不同的长度范围,MySQL也会有不一样的存储处理。
char(n) 不管该字段是否存储数据,都占n个字符的存储空间;varchar 不存的时候不占空间,存多长数据就占多少空间,可以节省存储空间。
(2)查询优化
1、任何查询也不要出现select *
2、对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
3、2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null-- 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=
4、应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。
5、in 和 not in 也要慎用,否则会导致全表扫描,如:select id from t where num in(1,2,3)-- 对于连续的数值,能用 between 就不要用 in 了:select id from t where num between 1 and 3
6、尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
7、避免频繁创建和删除临时表,以减少系统表资源的消耗。
8、减少跨库查询或多表连接操作
9、将常用的查询放入到缓冲
(3)索引优化
对作为查询条件和 order by的字段建立索引
避免建立过多的索引,多使用组合索引
(4)慢查询优化
在业务系统中,除了使用主键进行的查询,其他的我都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。慢查询的优化首先要搞明白慢的原因是什么?是查询条件没有命中索引?是load了不需要的数据列?还是数据量太大?所以优化也是针对这三个方向来的,
(1)首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
(2)分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
(3)如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
(5)优化长难的查询语句
(1)一个复杂查询还是多个简单查询
(2)MySQL内部每秒能扫描内存中上百万行数据,相比之下,响应数据给客户端就要慢得多
(3)使用尽可能小的查询是好的,但是有时将一个大的查询分解为多个小的查询是很有必要的。
(6)一次性删除1000万的数据要比一次删除1万,暂停一会的方案更加损耗服务器开销。
(8)执行单个查询可以减少锁的竞争。
(10)查询效率会有大幅提升。
(11)较少冗余记录的查询。
(6)优化查询过程中的数据访问
(1)访问数据太多导致查询性能下降
(2)确定应用程序是否在检索大量超过需要的数据,可能是太多行或列
(3)确认MySQL服务器是否在分析大量不必要的数据行
(4)避免犯如下SQL语句错误
(5)查询不需要的数据。解决办法:使用limit解决
(6)多表关联返回全部列。解决办法:指定列名
(7)重写SQL语句,让优化器可以以更优的方式执行查询。
(8)重复查询相同的数据。解决办法:可以缓存数据,下次直接读取缓存
(9)是否在扫描额外的记录。
(10)使用索引覆盖扫描,把所有的列都放到索引中,
(11)改变数据库和表的结构,修改数据表范式
(7)SQL的生命周期?
(1)应用服务器与数据库服务器建立一个连接
(2)数据库进程拿到请求sql
(3)解析并生成执行计划,执行
(4)读取数据到内存并进行逻辑处理
(5)将读取到的数据封装到一个响应,发送结果到服务端
(6)服务端将响应返回到客户端
(7)关掉连接,释放资源
(8)什么是内存泄漏?
由于内存是有限的,当计算机内存中存在大量的相互(循环)引用计数时,会占用大部分的内存;当新的变量进来时,但是内存不够用了,所以不会去开辟新的内存

来源地址:https://blog.csdn.net/YZL40514131/article/details/128529226
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341













