

java 中Buffer源码的分析


java 中Buffer源码的分析
Buffer
Buffer的类图如下:
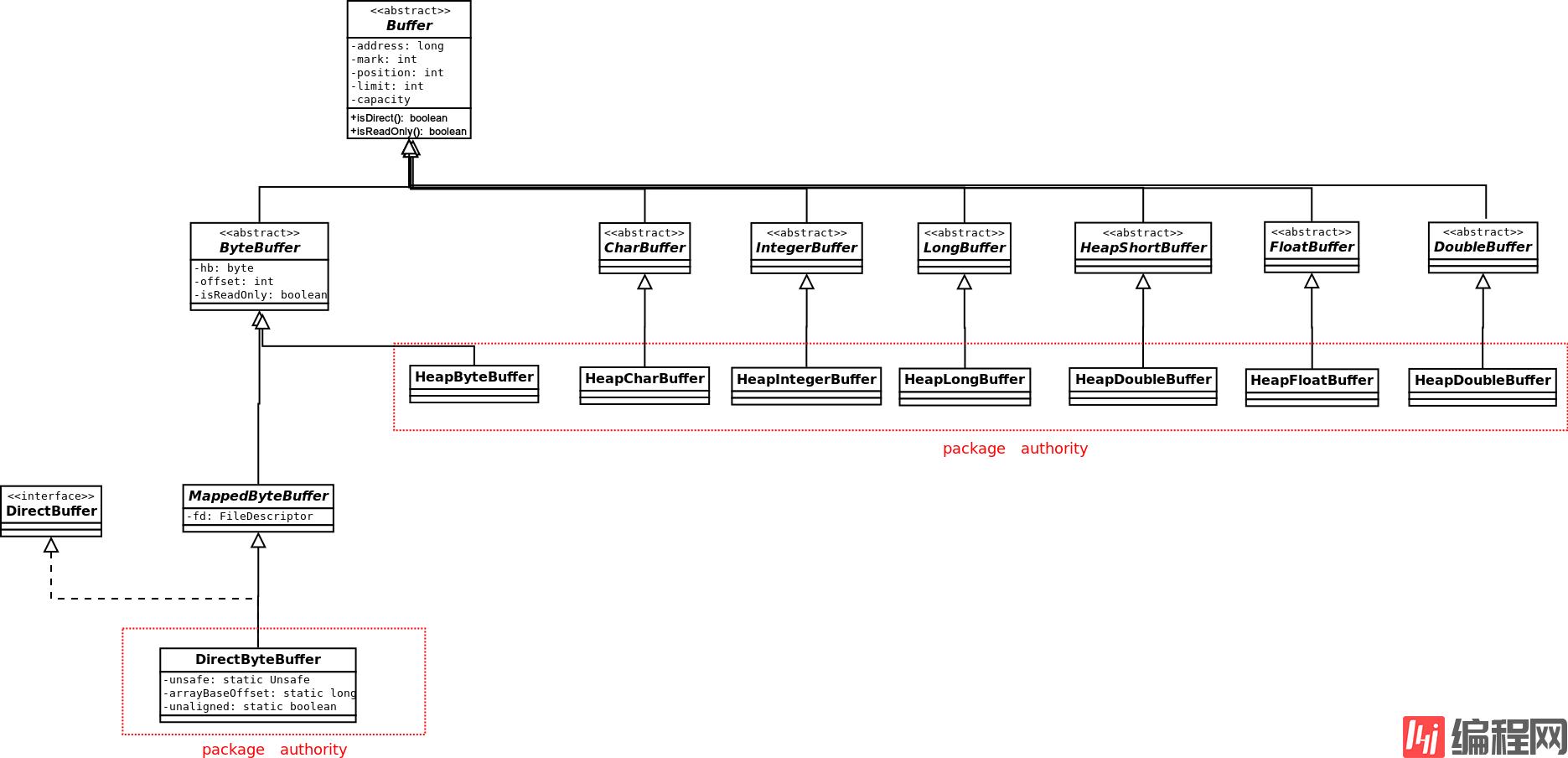
除了Boolean,其他基本数据类型都有对应的Buffer,但是只有ByteBuffer才能和Channel交互。只有ByteBuffer才能产生Direct的buffer,其他数据类型的Buffer只能产生Heap类型的Buffer。ByteBuffer可以产生其他数据类型的视图Buffer,如果ByteBuffer本身是Direct的,则产生的各视图Buffer也是Direct的。
Direct和Heap类型Buffer的本质
首选说说JVM是怎么进行IO操作的。
JVM在需要通过操作系统调用完成IO操作,比如可以通过read系统调用完成文件的读取。read的原型是:ssize_t read(int fd,void *buf,size_t nbytes),和其他的IO系统调用类似,一般需要缓冲区作为其中一个参数,该缓冲区要求是连续的。
Buffer分为Direct和Heap两类,下面分别说明这两类buffer。
Heap
Heap类型的Buffer存在于JVM的堆上,这部分内存的回收与整理和普通的对象一样。Heap类型的Buffer对象都包含一个对应基本数据类型的数组属性(比如:final **[] hb),数组才是Heap类型Buffer的底层缓冲区。
但是Heap类型的Buffer不能作为缓冲区参数直接进行系统调用,主要因为下面两个原因。
- JVM在GC时可能会移动缓冲区(复制-整理),缓冲区的地址不固定。
- 系统调用时,缓冲区需要是连续的,但是数组可能不是连续的(JVM的实现没要求连续)。
所以使用Heap类型的Buffer进行IO时,JVM需要产生一个临时Direct类型的Buffer,然后进行数据复制,再使用临时Direct的
Buffer作为参数进行操作系统调用。这造成很低的效率,主要是因为两个原因:
- 需要把数据从Heap类型的Buffer里面复制到临时创建的Direct的Buffer里面。
- 可能产生大量的Buffer对象,从而提高GC的频率。所以在IO操作时,可以通过重复利用Buffer进行优化。
Direct
Direct类型的buffer,不存在于堆上,而是JVM通过malloc直接分配的一段连续的内存,这部分内存成为直接内存,JVM进行IO系统调用时使用的是直接内存作为缓冲区。
-XX:MaxDirectMemorySize,通过这个配置可以设置允许分配的最大直接内存的大小(MappedByteBuffer分配的内存不受此配置影响)。
直接内存的回收和堆内存的回收不同,如果直接内存使用不当,很容易造成OutOfMemoryError。Java没有提供显示的方法去主动释放直接内存,sun.misc.Unsafe类可以进行直接的底层内存操作,通过该类可以主动释放和管理直接内存。同理,也应该重复利用直接内存以提高效率。
MappedByteBuffer和DirectByteBuffer之间的关系
This is a little bit backwards: By rights MappedByteBuffer should be a subclass of DirectByteBuffer, but to keep the spec clear and simple, and for optimization purposes, it's easier to do it the other way around.This works because DirectByteBuffer is a package-private class.(本段话摘自MappedByteBuffer的源码)
实际上,MappedByteBuffer属于映射buffer(自己看看虚拟内存),但是DirectByteBuffer只是说明该部分内存是JVM在直接内存区分配的连续缓冲区,并不一是映射的。也就是说MappedByteBuffer应该是DirectByteBuffer的子类,但是为了方便和优化,把MappedByteBuffer作为了DirectByteBuffer的父类。另外,虽然MappedByteBuffer在逻辑上应该是DirectByteBuffer的子类,而且MappedByteBuffer的内存的GC和直接内存的GC类似(和堆GC不同),但是分配的MappedByteBuffer的大小不受-XX:MaxDirectMemorySize参数影响。
MappedByteBuffer封装的是内存映射文件操作,也就是只能进行文件IO操作。MappedByteBuffer是根据mmap产生的映射缓冲区,这部分缓冲区被映射到对应的文件页上,属于直接内存在用户态,通过MappedByteBuffer可以直接操作映射缓冲区,而这部分缓冲区又被映射到文件页上,操作系统通过对应内存页的调入和调出完成文件的写入和写出。
MappedByteBuffer
通过FileChannel.map(MapMode mode,long position, long size)得到MappedByteBuffer,下面结合源码说明MappedByteBuffer的产生过程。
FileChannel.map的源码:
public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException { ensureOpen(); if (position < 0L) throw new IllegalArgumentException("Negative position"); if (size < 0L) throw new IllegalArgumentException("Negative size"); if (position + size < 0) throw new IllegalArgumentException("Position + size overflow"); //最大2G if (size > Integer.MAX_VALUE) throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE"); int imode = -1; if (mode == MapMode.READ_ONLY) imode = MAP_RO; else if (mode == MapMode.READ_WRITE) imode = MAP_RW; else if (mode == MapMode.PRIVATE) imode = MAP_PV; assert (imode >= 0); if ((mode != MapMode.READ_ONLY) && !writable) throw new NonWritableChannelException(); if (!readable) throw new NonReadableChannelException(); long addr = -1; int ti = -1; try { begin(); ti = threads.add(); if (!isOpen()) return null; //size()返回实际的文件大小 //如果实际文件大小不符合,则增大文件的大小,文件的大小被改变,文件增大的部分默认设置为0。 if (size() < position + size) { // Extend file size if (!writable) { throw new IOException("Channel not open for writing " + "- cannot extend file to required size"); } int rv; do { //增大文件的大小 rv = nd.truncate(fd, position + size); } while ((rv == IOStatus.INTERRUPTED) && isOpen()); } //如果要求映射的文件大小为0,则不调用操作系统的mmap调用,只是生成一个空间容量为0的DirectByteBuffer //并返回 if (size == 0) { addr = 0; // a valid file descriptor is not required FileDescriptor dummy = new FileDescriptor(); if ((!writable) || (imode == MAP_RO)) return Util.newMappedByteBufferR(0, 0, dummy, null); else return Util.newMappedByteBuffer(0, 0, dummy, null); } //allocationGranularity的大小在我的系统上是4K //页对齐,pagePosition为第多少页 int pagePosition = (int)(position % allocationGranularity); //从页的最开始映射 long mapPosition = position - pagePosition; //因为从页的最开始映射,增大映射空间 long mapSize = size + pagePosition; try { // If no exception was thrown from map0, the address is valid //native方法,源代码在openjdk/jdk/class="lazy" data-src/solaris/native/sun/nio/ch/FileChannelImpl.c, //参见下面的说明 addr = map0(imode, mapPosition, mapSize); } catch (OutOfMemoryError x) { // An OutOfMemoryError may indicate that we've exhausted memory // so force gc and re-attempt map System.gc(); try { Thread.sleep(100); } catch (InterruptedException y) { Thread.currentThread().interrupt(); } try { addr = map0(imode, mapPosition, mapSize); } catch (OutOfMemoryError y) { // After a second OOME, fail throw new IOException("Map failed", y); } } // On Windows, and potentially other platforms, we need an open // file descriptor for some mapping operations. FileDescriptor mfd; try { mfd = nd.duplicateForMapping(fd); } catch (IOException ioe) { unmap0(addr, mapSize); throw ioe; } assert (IOStatus.checkAll(addr)); assert (addr % allocationGranularity == 0); int isize = (int)size; Unmapper um = new Unmapper(addr, mapSize, isize, mfd); if ((!writable) || (imode == MAP_RO)) { return Util.newMappedByteBufferR(isize, addr + pagePosition, mfd, um); } else { return Util.newMappedByteBuffer(isize, addr + pagePosition, mfd, um); } } finally { threads.remove(ti); end(IOStatus.checkAll(addr)); } }免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
java 中Buffer源码的分析
下载Word文档到电脑,方便收藏和打印~











