

知识图谱项目——红色文化之张学良人物知识图谱(Neo4j+vue+flask+mysql实现)

张学良人物简史知识图谱_说明文档
本项目为人工智能专业大三知识图谱课程期末作业。意在完成一个以张学良为背景的红色文化类知识图谱。文末放上本项目的代码地址。
文章目录
🚀前端
- Vue.js
- d3.js
- jQuery
- html/css/js
🚀后端
- Flask
🚀中间件
🅰️axios
🅱️neo4j-driver
🚀数据库
- MySQL
- Neo4j
🚀服务器
- 腾讯云轻量应用服务器
📖1、数据采集
互联网上搜集数据,本项目基于百度百科的数据,进行搜集并绘制初始的知识图谱,并搜集到了十种关系类别。并建立 second.csv。
| id | name |
|---|---|
| 1 | property |
| 2 | relatives |
| 3 | biography |
| 4 | ally |
| 5 | politicalViewPoint |
| 6 | Subordinate |
| 7 | Superior |
| 8 | Enemy |
| 9 | Everywhere he goes |
| 10 | Someone who knew him |
由于采集了100条真实数据,为了测试数据量大的情况。使用Faker库来进行张学良去过的地方以及认识张学良的人数据
from faker import Fakerimport pandas as pdfake = Faker(['zh_CN', 'en_US'])# 生成第一列数据country1_cities = {fake.city_name() + '市' for i in range(2000)}column1 = list(country1_cities) + [fake.state()]*2000print(len(column1))# 生成第二列数据names = {fake.name() for j in range(4000)}column2 = list(names)print(len(column2))# 计算每列数据的长度len1 = len(column1)len2 = len(column2)# 如果列的长度不一致,则新建一个DataFrame来保证列的长度一致if len1 != len2: max_len = max(len1, len2) dummy_df = pd.DataFrame() if len1 < max_len: dummy_df['国家或地区'] = ['']*(max_len - len1) column1.extend(dummy_df['国家或地区'].tolist()) elif len2 < max_len: dummy_df['人名'] = ['']*(max_len - len2) column2.extend(dummy_df['人名'].tolist())# 将数据转化为DataFramedf = pd.concat([pd.DataFrame(column1, columns=['国家或地区']), pd.DataFrame(column2, columns=['人名'])], axis=1)# 保存到csv文件中df.to_csv('地名与人名不重复.csv', index=False)使用实体识别技术将网络文本中的实体抽取
import jieba.posseg as psegimport textractimport csvfile_path = '数据.docx'text = textract.process(file_path).decode('utf-8')with open('实体数据结果.csv', 'w', newline='', encoding='utf-8') as csvfile: writer = csv.writer(csvfile) shiti = pseg.cut(text) # 找出所有组成的 'nt'(机构团体)和 'nz'(其他专有名词)类型的词汇 for word, flag in shiti: if flag in ['nt', 'nz']: writer.writerow([word, flag])🐇2、数据预处理
将所有类别采集到的数据放入 third.csv。
| id | name | describe |
|---|---|---|
| … | … | … |
| 49 | 联俄、联共、扶助农工,“三大政策” | 张学良提出的“三大政策”,即联俄、联共、扶助农工,是其治理东北时所推行的主要政策,也是他对于中国革命和现代化建设问题的一种思考。 |
|---|---|---|
| 50 | 中华民族统一和国家现代化 | 张学良认为,实现中华民族统一和国家现代化是中国现代化建设事业的最终目标。他反对分裂主义和帝国主义侵略,主张通过改革和现代化建设提升中国国家实力和综合竞争力。 |
| 51 | 民主、法制和教育改革 | 张学良提倡以民主、法制和教育改革为核心的中国现代化进程,认为这是推进社会进步和国家发展的重要保障。他主张发扬民主,建设法治,推进教育改革,促进中国社会的和谐发展。 |
| 52 | 统一战线和减轻民众负担 | 张学良主张建立广泛统一战线,积极团结各界人士,推进以减轻民众负担为核心的经济和社会改革。他认为,这是实现中华民族伟大复兴和国家现代化的必经之路。 |
| 53 | 杨虎城 | 曾任东北军第一军军长,是张学良手下最得力的将领之一。 |
| 54 | 万福麟 | 曾任东北军第二十七师师长,是张学良的心腹之一,后因支持抗日战争而遭到逮捕。 |
| 55 | 刘骥 | 曾任东北军副总司令、沈阳市等职,被认为是张学良的得力助手之一。 |
| 56 | 谭道源 | 曾任东北军第十三路军军长,是张学良的部属之一。 |
| 57 | 傅作义 | 曾任东北军第三军军长、华北政务委员会等职,与张学良关系密切,在1935年“九一八事变”后加入了中国党。 |
| 58 | 马步芳 | 曾任东北军第八师师长、奉天等职,是张学良手下的一位著名将领。 |
| 59 | 张作霖 | 是张学良的父亲,也是东北军的创始人之一。张学良在东北军的初期时期曾担任他的副手,后继任东北军总司令。 |
| 60 | 孙传芳 | 曾是张学良的上级长官,掌管了奉天和陆军第三师等职。 |
| 61 | 马步芳 | 曾是张学良的上级长官,任命他为东北军第八师师长。 |
| 62 | 蒋介石 | 是中国的创始人和领袖,曾与张学良有过密切合作关系。在国共合作时期,两人曾携手抵抗日本侵略,但在中国内战中,两人成为敌对方。 |
| 63 | 汪精卫 | 是中国国内党人以外最早提出“联共”口号的家之一。 |
建立关系表
| third_id | second_id | role |
|---|---|---|
| 1 | 1 | sex |
| 2 | 1 | alias |
| 3 | 1 | nationality |
| 4 | 1 | nation |
| 5 | 1 | birthdate |
🐰3、Neo4j数据库导入
建约束条件
在导入数据之前,需要先创建节点类型的约束条件,以确保不会出现重复的节点。
Neo4j 1.5版本
CREATE CONSTRAINT FOR (s:second) REQUIRE s.id IS UNIQUE;CREATE CONSTRAINT FOR (t:third ) REQUIRE t.id IS UNIQUE;Neo4j 1.4版本
CREATE CONSTRAINT ON (s:second) ASSERT s.id IS UNIQUE;CREATE CONSTRAINT ON (t:third ) ASSERT t.id IS UNIQUE;在准备好数据文件和创建约束条件之后,可以使用Cypher导入语句进行数据导入。
#Third.csv
LOAD CSV WITH HEADERS FROM 'file:///second.csv' AS lineCREATE (s:second{id: toInteger(line.id), name: line.name, year: toInteger(line.year)});LOAD CSV WITH HEADERS FROM "file:///third.csv" AS lineCREATE (t:third {id: toInteger(line.id), name: line.name, gender: line.gender});LOAD CSV WITH HEADERS FROM "file:///third_role.csv" AS lineMATCH (s:second{id: toInteger(line.second_id)})MATCH (t:third {id: toInteger(line.third_id)})CREATE (s)-[:role {name: line.role}]->(t);创建节点
//创建节点create (n:person{name:"张学良"})![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OIWpOjHs-1687009471889)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617211726846.png)]](https://file.lsjlt.com/upload/f/202309/10/txczyjefj1w.png)
建立节点之间的关系
//建立节点之间的关系match(n:person),(s:second) where n.name="张学良" and s.name="property" create(n)-[r:属性]- >(s);match(n:person),(s:second) where n.name="张学良" and s.name="biography" create(n)-[r:传记]- >(s);match(n:person),(s:second) where n.name="张学良" and s.name="relatives" create(n)-[r:亲属]- >(s);match(n:person),(s:second) where n.name="张学良" and s.name="politicalViewPoint" create(n)-[r:政治观点]- >(s);match(n:person),(s:second) where n.name="张学良" and s.name="ally" create(n)-[r:盟友]- >(s);match(n:person),(s:second) where n.name="张学良" and s.name="Subordinate" create(n)-[r:下属]- >(s);match(n:person),(s:second) where n.name="张学良" and s.name="Superior" create(n)-[r:上司]- >(s);match(n:person),(s:second) where n.name="张学良" and s.name="Enemy" create(n)-[r:敌人]- >(s);match(n:person),(s:second) where n.name="张学良" and s.name="Everywhere he goes" create(n)-[r:去过的地方]- >(s);match(n:person),(s:second) where n.name="张学良" and s.name="Someone who knew him" create(n)-[r:认识他的人]- >(s);敌人
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YpKcDJXu-1687009471893)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617211805402.png)]](https://file.lsjlt.com/upload/f/202309/10/b4uqmsvvarv.png)
上司
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cQNI6zTw-1687009471894)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617211840837.png)]](https://file.lsjlt.com/upload/f/202309/10/cjhv3dwlb0o.png)
认识他的人(显示达到上限)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qiI8RcGQ-1687009471895)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617211956800.png)]](https://file.lsjlt.com/upload/f/202309/10/tem50x0dtx2.png)
🐎4、前端展示
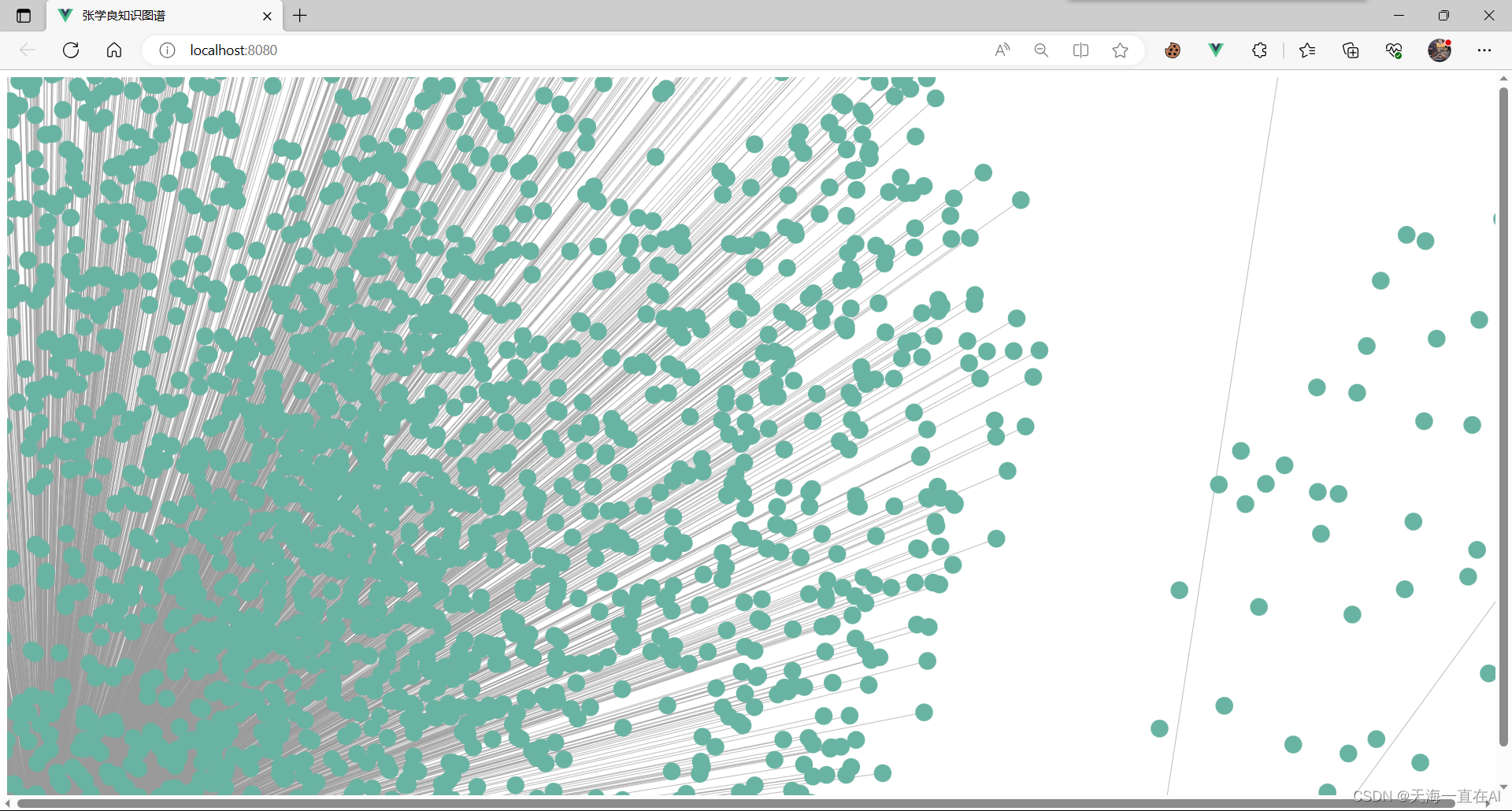
由于neo4j数据库中最多只能显示300个节点,我就是想看所有节点,想炫酷地一起展示几千个节点。
所以使用d3、neo4j-driver进行数据库连接、读取和前端展示
<!--APP.vue--><template><div id="graph-container"></div></template><script>import neo4j from "neo4j-driver";import * as d3 from 'd3';import * as d3Force from 'd3-force';let driver = neo4j.driver( "bolt://localhost:7687", neo4j.auth.basic("neo4j", "1234"));export default { name: "app", data() { return { graphData: [], nodes: [], relationships: [], }; }, props: {}, created() { this.fetchData(); }, methods: { setupNeo4j() { this.driver = neo4j.driver( 'bolt://localhost:7687', neo4j.auth.basic('neo4j', '1234'), { encrypted: false } ); this.session = this.driver.session(); }, async getData() { const result = await this.session.run( ` MATCH (n)-[r]->(p) RETURN n, r, p ` ); const nodes = []; const edges = []; result.records.forEach(record => { nodes.push({ id: record.get('n').identity.toNumber(), name: record.get('n').properties.name, label: record.get('n').labels[0], }); nodes.push({ id: record.get('p').identity.toNumber(), name: record.get('p').properties.name, label: record.get('p').labels[0], }); edges.push({ source: record.get('n').identity.toNumber(), target: record.get('p').identity.toNumber(), type: record.get('r').type, properties: record.get('r').properties, }); }); return { nodes, edges }; }, async drawGraph() { const data = await this.getData(); const svg = d3.select('#graph-container').append('svg'); const width = window.innerWidth; const height = window.innerHeight; svg.attr('width', width).attr('height', height); const simulation = d3Force .forceSimulation() .force( 'link', d3Force .forceLink() .id(d => d.id) .distance(100) ) .force( 'charge', d3Force.forceManyBody().strength(-500).distanceMax(500) ) .force('center', d3Force.forceCenter(width / 2, height / 2)); const link = svg .selectAll('line') .data(data.edges) .enter() .append('line') .attr('stroke', '#999') .attr('stroke-opacity', 0.6) .attr('stroke-width', d => Math.sqrt(d.properties.weight)); const node = svg .selectAll('circle') .data(data.nodes) .enter() .append('circle') .attr('r', 10) .attr('fill', '#69b3a2') .call( d3.drag().on('start', dragstarted).on('drag', dragged).on('end', dragended) ); node.append('title').text(d => d.name); simulation.nodes(data.nodes).on('tick', ticked); simulation.force('link').links(data.edges); function ticked() { link .attr('x1', d => d.source.x) .attr('y1', d => d.source.y) .attr('x2', d => d.target.x) .attr('y2', d => d.target.y); node.attr('cx', d => d.x).attr('cy', d => d.y); } function dragstarted(d) { if (!d3.event.active) simulation.alphaTarget(0.3).restart(); d.fx = d.x; d.fy = d.y; } function dragged(d) { d.fx = d3.event.x; d.fy = d3.event.y; } function dragended(d) { if (!d3.event.active) simulation.alphaTarget(0); d.fx = null; d.fy = null; } } }, mounted() { this.setupNeo4j(); this.drawGraph(); },};</script><style scoped>ul { list-style: none; padding: 0;}</style>结果如图:和neo4j拥有一样的浮动效果,就是没有实现拖拽哈哈。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n34VyRDZ-1687009471898)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617212827643.png)]](https://file.lsjlt.com/upload/f/202309/10/lwqpymtcpq3.png)
🐶5、项目总体展示
使用Flask框架连接mysql数据库实现了节点的动态存储
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ek4VePtb-1687009471898)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617213324015.png)]](https://file.lsjlt.com/upload/f/202309/10/j2eo14vpcvp.png)
由于需要操作数据库,所以实现了登录注册功能,来对能操作建立节点的用户设置权限。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xkgOH9AW-1687009471899)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617213442350.png)]](https://file.lsjlt.com/upload/f/202309/10/4j5buymiaki.png)
使用简单的get请求来传到url上,仅供学习。
点击建立节点页面
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fCoBriXh-1687009471899)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617213619129.png)]](https://file.lsjlt.com/upload/f/202309/10/qmctgxjjdqo.png)
我们可以输入主节点的名称、主节点的关系和指向节点的名称,注意节点名在数据库中只能存在一个。
此外还可以新增节点来建立多个节点之间的关系。比如我们要将右侧的案例复现。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A8zlPyYE-1687009471899)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617213917726.png)]](https://file.lsjlt.com/upload/f/202309/10/l1a23fu1a1t.png)
提交后结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ywX9cxRo-1687009471900)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230617213943061.png)]](https://file.lsjlt.com/upload/f/202309/10/yfjzd0utz1z.png)
Flask后端实现代码如下:
from kgview import kg_viewimport jsonfrom flask import Flask, render_template, request# 导入pymysql模块import pymysql# 连接databaseconn = pymysql.connect(host="localhost", user="root", password="1234", port=3306, database="test", charset="utf8", autocommit=True)# 得到一个可以执行SQL语句的光标对象cursor = conn.cursor()class saveData(): idData = Nonedata = saveData()app = Flask(__name__)# 装饰器 给函数新增功能@app.route('/') # 路由def index(): return render_template('Z.html')@app.route('/s')def search(): keyword = request.args.get('search') kg_view(keyword) links = kg_view(keyword) for i in range(len(links)): links[i] = links[i].replace("source", '"source"').replace("target", '"target"').replace("type", '"type"').replace("'", '"') links[i] = json.loads(links[i]) return render_template('index.html', result_json=links)@app.errorhandler(404)# 当发生404错误时,会被该路由匹配def handle_404_error(err_msg): """自定义的异常处理函数""" # 这个函数的返回值就是前端用户看到的最终结果 (404错误页面) return u"出现了404错误, 错误信息:%s" % err_msg@app.route('/dl')def dl(): return render_template('dl.html')@app.route('/dltj')def dltj(): """登录""" pwd = request.args.get('password') id = request.args.get('username') data.idData = id try: sql = """ SELECT pwd FROM users WHERE pwd=%s; """ # 执行SQL语句 # 判断是否查询到结果1为有0为无 judge = cursor.execute(sql, id) conn.commit() desc = cursor.description data_dict = [dict(zip([col[0] for col in desc], row)) for row in cursor.fetchall()] # 列表表达式把数据组装起来 print(data_dict) # 真实密码 zm = data_dict[0].get('pwd') print(zm) if judge == 0: return "没有这个用户!" else: if zm == pwd: return render_template('Z.html') else: return "密码错误" except: return "用户不存在" return render_template('Z.html')@app.route('/zc')def zc(): return render_template('zc.html')@app.route('/zctj')def zctj(): """注册""" zcpwd = request.args.get('zcpassword') zcid = request.args.get('zcid') try: sql = """ INSERT INTO users (id,pwd) VALUES (%s,%s); """ # 执行SQL语句 cursor.execute(sql, [zcid, zcpwd]) conn.commit() except: return "用户名重复" # 关闭光标对象 # cursor.close() return render_template('dl.html')@app.route('/myNode')def returnMyNode(): id = data.idData """取出我的节点""" try: sql = """ SELECT nodeData FROM users WHERE id=%s; """ # 执行SQL语句 # 判断是否查询到结果1为有0为无 cursor.execute(sql, id) conn.commit() desc = cursor.description data_dict = [dict(zip([col[0] for col in desc], row)) for row in cursor.fetchall()] # 列表表达式把数据组装起来 # 节点数据 nd = data_dict[0].get('nodeData') except: return "您还尚未登录" links = nd return render_template('index.html', result_json=links)@app.route('/createNode')def createMyNode(): return render_template('createNode.html')@app.route('/add')def addnode(): print(data.idData) id = data.idData i = request.args.get('nodeNum') i = int(i) insideDict={} links = [] links1 = [] for j in range(1, i + 1): node = request.args.get('mainnode' + str(j)) # 节点 target = request.args.get('point' + str(j)) # 指向 rela = request.args.get('rela' + str(j)) # 关系 insideDict = {'source': node,'target': target,'type':'resolved', 'rela': rela,} links.append(insideDict) links1.append(node) links1.append(target) links1.append(rela) link = str(links) """节点存入数据库""" print(insideDict.values()) sql = """ insert into node (node,relation,target,id) values (%s,%s,%s,%s) """ cursor.execute(sql, [links1[0],links1[1],links1[2],id]) conn.commit() return render_template('index.html',result_json=links)if __name__ == '__main__': # debug调试模式=true自动重启 app.run(debug=True)📄6、论文知识抽取
我们根据已有的内容总结出了论文——docx文档
随后,对论文进行了知识抽取功能
- 1、读取文档内容
- 2、去停用词、分词
- 3、实体识别
- 4、词性标注
- 5、依存句法分析
- 6、词频统计
- 7、词云展示
- 8、关系抽取
import jiebafrom collections import Counterfrom wordcloud import WordCloudimport textractimport pytesseractfrom PIL import Imageimport numpy as npimport cv2import csvimport textractimport jieba.posseg as psegimport nltkfrom nltk.parse import stanfordfrom nltk.corpus import stopwordsfrom stanfordcorenlp import StanfordCoreNLPimport spacynlp = spacy.load('en_core_web_sm')# 读取文档内容file_path = '知识图谱论文.docx'text = textract.process(file_path).decode('utf-8')# 去停用词、分词baidu_stopwords = [line.strip() for line in open('baidu_stopwords.txt', 'r', encoding='utf-8').readlines()]words = [word for word in jieba.cut(text) if word not in baidu_stopwords and len(word) > 1]print(words)# 实体识别shiti = pseg.cut(text)# 找出所有组成的 'nt'(机构团体)和 'nz'(其他专有名词)类型的词汇for word, flag in shiti: if flag in ['nt', 'nz']: print(word, flag)# 词性标注# 对每个列表元素进行词性标注for word, flag in pseg.cut(" ".join(words)): print(word, flag)with open("词性标注.txt", "w", encoding="utf-8") as f: for word, flag in pseg.cut(" ".join(words)): f.write(word + " " + flag + "\n")# 查看句子的依存关系doc = nlp(' '.join(words))for token in doc: print(token.text, token.dep_, token.head.text, token.head.pos_, [child for child in token.children])# 其中,token.dep_表示词性依存关系,例如nsubj表示主语,amod表示形容词修饰语,dobj表示直接宾语等等;token.head表示当前单词的父节点;token.children表示当前单词的子节点。with open("依存关系.txt", "w") as f: for token in doc: f.write(f"{token.text}\t{token.dep_}\t{token.head.text}\t{token.head.pos_}\t" f"{[child for child in token.children]}\n")# 词频统计word_count = Counter(words)# 词云展示wordcloud = WordCloud(font_path='simkai.ttf', background_color='white', width=1000, height=800).generate_from_frequencies(word_count)wordcloud.to_file('wordcloud.png')# 关系抽取img = cv2.imread('wordcloud.png')gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)ret, thresh = cv2.threshold(gray, 127, 255, 0)contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)for cnt in contours: x, y, w, h = cv2.boundingRect(cnt) if w > 30 and h > 30: crop_img = img[y:y + h, x:x + w] cv2.imwrite('crop_img.png', crop_img) breakimg = Image.open('crop_img.png')print('去停用词、分词后的结果为:', words)print('词频统计的结果为:', word_count)词性标注结果:
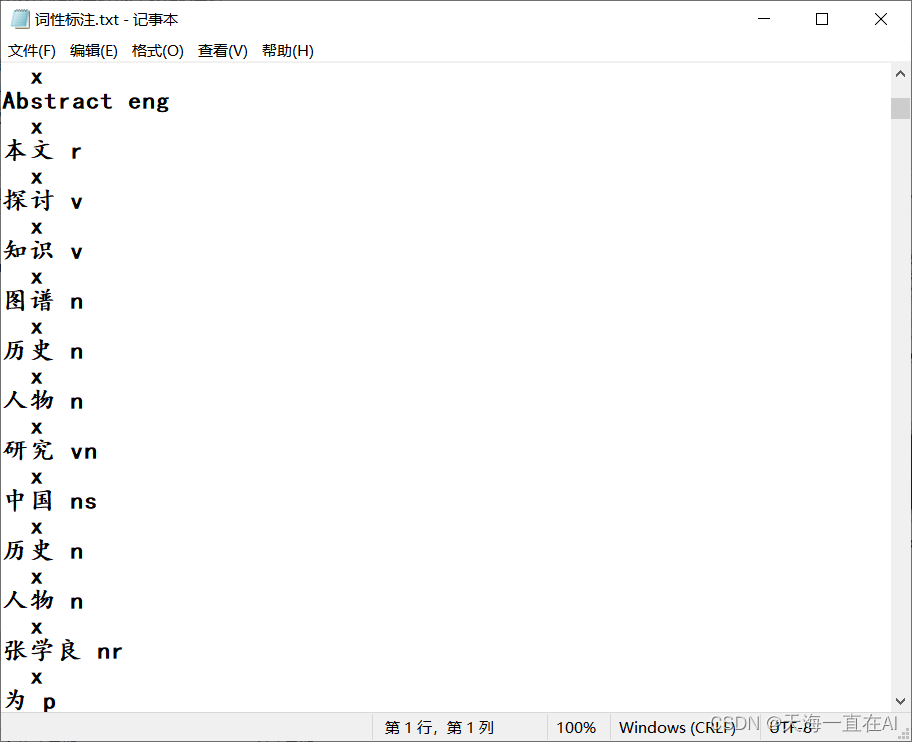
依存关系:

词云:

这就是本项目的全部分享了,代码已开源,地址见评论或私信
来源地址:https://blog.csdn.net/tianhai12/article/details/131265020
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341


![[mysql]mysql8修改root密码](https://static.528045.com/imgs/44.jpg?imageMogr2/format/webp/blur/1x0/quality/35)









