

怎么开发Webpack Loader


本篇内容主要讲解“怎么开发Webpack Loader”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么开发Webpack Loader”吧!
一、单一任务
loaders可以被链式调用,为每一步创建一个loader而非一个loader做所有事情。也就是说,在非必要的状况下没有必要将他们转换为js。
例如:通过查询字符串将一个字符串模板转化为html。
如果你写了个loader。做了所有事情那么你违背了loader的第一条要求。你应该为每一个task创建一个loader并且通过管道来使用它们
(1)ade-loader: 转换模板为一个module
(2) apply-loader: 创建一个module并通过查询参数来返回结果
(3)html-loade: 创建一个处理html并返回一个string的模块
二、创建moulde话的模块,即正常的模块
loader产出的module应该和遵循和普通的module一样的设计原则。
举个例子,下面这样设计是不好的,没有模块化,依赖全局状态。

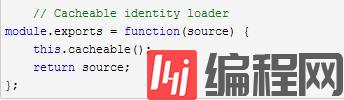
三、尽量表明该loader是否可以缓存
大部分loaders是cacheable,所以应该标明是否cacheable,只需要在loader里面调用即可。
四、不要在运行和模块之间保存状态
(1)一个loader相对于其他编译后的模块应该是独立的。 除非其可以自己处理这些状态
(2)一个loader相对于同一模块之前的编译过程应该是独立的。
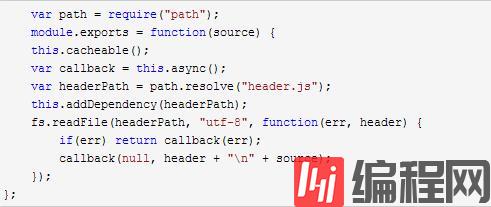
五、标明依赖
如果该loader引用了其他资源(例如文件系统), 必须声明它们。这些信息用来是缓存的loader失效并且重新编译它们。
六、解析依赖
很多语言都提供了一些规范来声明依赖,例如css中的 @import 和 url(...)。这些依赖应该被模块系统所解析。
下面是两种解决方式:
将它们转化成require
用this.resolve方法来解析路径
下面是两个示例:
css-loader: 将依赖转化成require,即用require来替换@import和 url(...),解析对其他样式文件的依赖
less-loader: 不能像css-loader那样做,因为所有的less文件需要一起编译来解析变量和mixins。因此其通过一个公共的路径逻辑来扩展less编译过程。这个公共的逻辑使用this.resolve来解析带有module系统配置项的文件。例如aliasing, custom module directories等。

如果语言仅仅接受相对urls(如css中url(file) 总是代表./file),使用~来说明成模块依赖.
七、抽离公共代码
extract common code 我感觉还是翻译成上面的比较好。其实所有语言都遵循该思想,即封装
不要写出来很多每个模块都在使用的代码,在loader中创建一个runtime文件,将公共代码放在其中
八、避免写入绝对路径
不要把绝对路径写入到模块代码中。它们将会破坏hash的过程当项目的根目录发生改变的时候。应该使用loader-utils的 stringifyRequest方法来绝对路径转化为相对路径。
例子:

九、使用peerDependencies来指明依赖的库
使用peerDependency允许应用开发者去在package.json里说明依赖的具体版本。这些依赖应该是相对开放的允许工具库升级而不需要重新发布loader版本。简而言之,对于peerDependency依赖的库应该是松耦合的,当工具库版本变化的时候不需要重新变更loader版本。
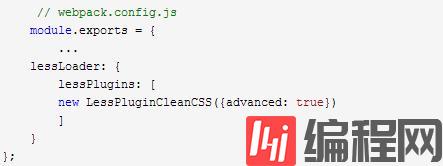
十、可编程对象作为查询项
有些情况下,loader需要某些可编程的对象但是不能作为序列化的query参数被方法解析。例如less-loader通过具体的less-plugin提供了这种可能。这种情况下,loader应该允许扩展webpack的options对象去获得具体的option。为了避免名字冲突,基于loader的命名空间来命名是很必要的。
到此,相信大家对“怎么开发Webpack Loader”有了更深的了解,不妨来实际操作一番吧!这里是编程网网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341













