

2022数模国赛C题思路解析(可供训练用 源码可供参考)

")
博主和两位队友参加了此次比赛,仅以此篇博客聊表纪念,并且最后也获得了不错的成绩
希望对大家有所帮助
持续更新~~
关于数据集和完整代码可以关注点赞收藏后评论区留下QQ邮箱或者私信博主要
有疑问可以评论区留言
摘要
古代玻璃制品是中西方文化交流中重要的贸易品之一,因环境影响容易风化导致化学成分比例发生变化。本文通过建立数学模型对古代玻璃的化学成分及类别进行研究分析,对古代玻璃的鉴别、早期发展、技术起源等问题具有一定的意义。
针对问题1,本文首先对颜色、缺失数据进行填充并剔除无效数据,紧接着通过EXCEL对表单1的信息进行可视化,可观察到风化可能会使玻璃出现新纹饰类型B;黑色的更可能为风化后的玻璃,而深蓝更可能是风化前的玻璃;铅钡玻璃相较于高钾玻璃更容易被风化。对表单2中的数据进行描述性统计分析,得到各化学成分的样本均值、方差,得到:高钾玻璃风化后SiO2增加了约27%、K20、CaO也发生了一定的变化,而其余变化不大;铅钡风化后SiO2减少了约20%,PbO增加了约14%,其余成分变化不大。进一步地,利用各指标风化前后的均值按比例关系对各风化点风化前的化学成分含量进行初步预测(结果见附录),再通过建立BP神经网络对预测模型的合理性进行检验,发现高钾类、铅钡类神经网络的迭代次数分别超过20、15次时其错误率均低于5%,反映了该模型的准确性;同时提取出样本中49号与50号(同时拥有风化前后数据)的原始数据将预测值进行对比,进一步检验了数据的正确性与合理性。
针对问题2,建立在问题1所得未风化数据的基础上,将其进行可视化得到高钾、铅钡玻璃各化学成分均值折线图、样本散点图进行比对,得到结论:若玻璃制品中K20的含量位于8%以上,而PbO、BaO的含量几乎没有时可初步判断该玻璃为高钾玻璃;若玻璃制品中PbO、BaO的含量分别位于10%、5%以上,而K20的含量为0时可初步判断该玻璃为铅钡玻璃。针对亚分类,首先采用主成分分析法进行降维,分别求出了高钾玻璃的3个主成成分和铅钡玻璃的2个主成成分作为新的指标,通过建立聚类分析模型对其指标数据进行聚类,利用SPSS对结果进行分析得到谱系图及指标散点图,并得出结论:高钾类可进一步分类为高锡-高钾玻璃、低锡-高钾玻璃;铅钡类可进一步分为低铜-低钙-铅钡玻璃、中铜-中钙-铅钡玻璃、高铜-高钙-铅钡玻璃(划分结果见附录)。合理性。对于亚分类结果的敏感性分析,采用利用二元Logistics回归以及Python的机器灵敏度分析算法进行灵敏度分析,可知得到较高的灵敏度模型。
针对问题3,对于未知类别玻璃的鉴别,通过SPSS利用二元Logistics回归模型进行预测,得到分类结果(见附录),采用与问题二同样的方法对分类结果进行敏感性性分析,得知表面风化指标、SiO2、K2O、PbO以及BaO指标对于该模型的分类结果灵敏度较高。
针对问题4,为了探究不同类别玻璃文物化学成分的关联联系,本文首先利用SPSS分别得到高钾、铅钡玻璃各个指标数据的矩阵散点图,再求得各个指标间得相关系数及其显著性,并根据不同类别的玻璃指标两两相关系数表,分析其差异性,得知不同类别的玻璃各指标间的相关系数差异较大。
关键词:玻璃 化学成分 神经网络 主成成分分析 聚类分析 二元Logistics回归
前面内容摘要太多不在赘叙
- 符号说明
| 符号 | 说明 |
| Fi | 高钾类玻璃的第i个主成成分 |
| H | 铅钡类玻璃的第j个主成成分 |
| K | 聚类数目 |
问题一:
问题1模型的建立与求解
首先对玻璃文物表面风化与各个指标的相关性分析,可以利用制作各个指标对应的频率分布饼状图,直观的看出表面有无风化的占比,并对其关系进行分析。
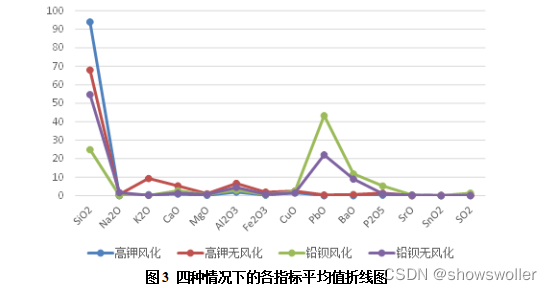
接着结合玻璃类型以及表面有无分化(共记4种情况)分析每种情况的化学成分含量的统计规律,可以利用Excel软件较为快速的进行描述性统计,接着利用4中情况的平均值折线图进行对比分析,得出在不同情况下统计规律的差异。
最后针对风化样本点风化前数据的预测问题,分别根据高钾玻璃与铅钡玻璃风化前与风化后的各指标平均值比例关系对所需预测的数据进行初步预测,再拟采用神经网络模型,分别对高钾玻璃和铅钡玻璃的样本点数据对神经网络进行训练,再根据迭代次数确定该网络的准确性,之后进一步确定预测数据的正确性。
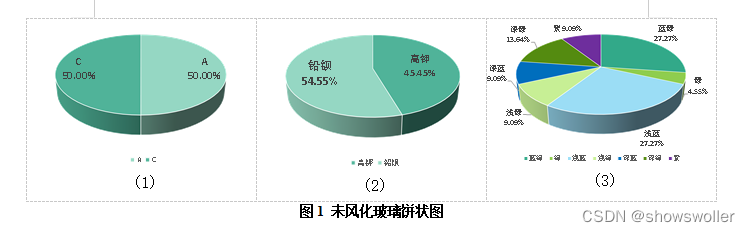
图1 未风化玻璃饼状图
- 表面分化与各指标的关系分析
(1)颜色指标数据处理
观察表单1可发现,各个指标数据中,文物编号为19,40,48以及58的样本的颜色指标数据为空白,拟通过表单2中这4个样本点的各个指标数据,分析出该样本的所属颜色。
通过查找相关文献,发现古代一般是通过添加过渡金属元素对玻璃制品进行着色,如Fe、Mn、Cu、Co等,主要以离子的形式存在,并且由其离子的价态决定玻璃的着色,且同一种着色离子的显色与酸碱度有关,亦可通过PbO与SiO2的相对含量进行判断。[2]根据附件数据,可发现19号与58号玻璃文物的Cu离子含量均大于3%,且PbO含量大于SiO2的含量,因此将其颜色记为深绿色;由于40号玻璃文物的Cu离子几乎为0,此时Fe离子在颜色决定的指标权重较大,因此记其颜色为黑色;由于48号玻璃文物Fe离子成分占比超过1%,远大于Cu离子的成分占比,因此同样记为黑色。
(2)表面分化与三指标关系分析
将表单1中的数据分为风化数据和未风化的数据,分别得到三个指标即玻璃类型、纹饰以及颜色中各个小类别的分布并对其进行可视化分析。例如:无风化类型的数据中, A类纹饰的玻璃共有11个,C类纹饰玻璃同样有11个,共计22个,两种纹饰类型分别占了50%,可用饼状图直观表示其分布,如图1(1)所示。同理,可用饼状图表示其余指标的数据分布特征:
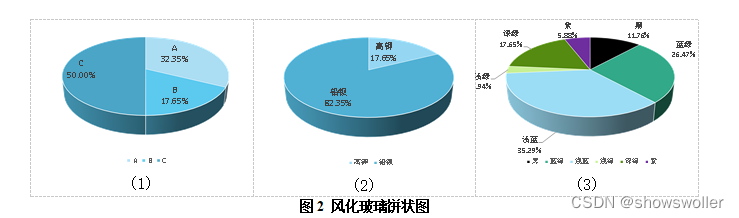
由图1.(1)与图2.(1)对比可知未风化玻璃的纹饰可能为A类和C类,且这两类的平均占比大小相近。而风化玻璃中出现的玻璃纹饰共有3类,分别为A,B,C类,这说明玻璃的风化会出现新的纹饰类型,且在风化玻璃中C类纹饰出现的频率最大,约占了总数目的一半,B类纹饰出现的频率最小,约为17.6%。
由图1.(2)与图2.(2)对比可知,铅钡玻璃相较于高钾玻璃更加容易被风化。
由图1.(3)与图2.(3)对比可知,相较于未风化玻璃,风化玻璃的颜色组成成分中增加了黑色类别,而减少了深蓝色类别,可知若一块玻璃的颜色呈现黑色,那么我们有极大的概率判断它属于风化后的玻璃;同理,若一块玻璃呈现出深蓝色,那么我们有极大的概率判断它属于未风化的玻璃。
部分统计表格如下
表1 高钾无风化描述性统计
| SiO2 | Na2O | K2O | CaO | MgO | Al2O3 | Fe2O3 | |
| 平均 | 67.98 | 0.70 | 9.33 | 5.33 | 1.08 | 6.62 | 1.93 |
| 方差 | 76.65 | 1.66 | 15.37 | 9.56 | 0.46 | 6.21 | 2.78 |
| CuO | PbO | BaO | P2O5 | SrO | SnO2 | SO2 | |
| 平均 | 2.45 | 0.41 | 0.60 | 1.40 | 0.04 | 0.20 | 0.10 |
| 方差 | 2.76 | 0.35 | 0.96 | 2.06 | 0.00 | 0.46 | 0.03 |
表3 铅钡无风化描述性统计
| SiO2 | Na2O | K2O | CaO | MgO | Al2O3 | Fe2O3 | |
| 平均 | 53.44 | 0.77 | 0.26 | 1.23 | 0.49 | 3.19 | 0.93 |
| 方差 | 212.79 | 2.37 | 0.16 | 2.12 | 0.30 | 1.92 | 2.09 |
| CuO | PbO | BaO | P2O5 | SrO | SnO2 | SO2 | |
| 平均 | 1.56 | 23.59 | 10.50 | 0.90 | 0.30 | 0.06 | 0.28 |
| 方差 | 6.20 | 82.71 | 48.30 | 2.47 | 0.10 | 0.02 | 1.03 |
神经网络训练错误率随训练次数的变化图如下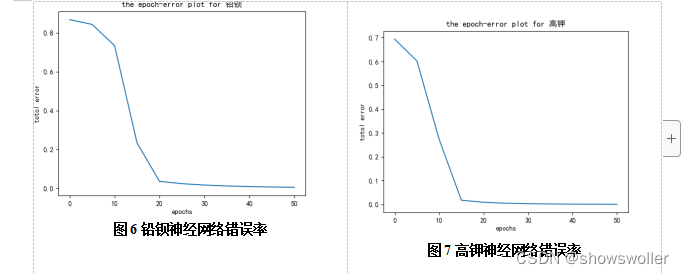
BP神经网络部分预测代码如下
from matplotlib import pyplot as pltfrom sklearn.neural_network import MLPRegressorfrom sklearn.preprocessing import StandardScalerimport matplotlib; matplotlib.use('TkAgg')import numpy as npimport pandas as pdfile_path = r"预测风化前数据.csv"df = pd.read_csv(file_path)data=r"C:风化后原始数据.csv"np.set_printoptions(suppress=True) # 取消科学计数法输出df1=df[df['类型']=='高钾']Y = df1.iloc[:,2:16]X = df1.values[:,2:16]print(Y)print("--------")print(X)# 标准化转换scaler=StandardScaler()X = scaler.fit_transform(X)print("拟合后的均值为:", scaler.mean_)print("拟合后的方差:", scaler.var_)clf = MLPRegressor(solver='lbfgs', activation='relu', learning_rate_init=0.001,alpha=0.001,max_iter=1000000, hidden_layer_sizes=(40,40))clf.fit(X,Y)# 测试数据pred = clf.predict(scaler.transform([[79.59994856 ,1.6181, 1.720573863 ,1.146336361, 1.162635452 ,8.597097058, 2.343302059, 0.163572022 ,24.18351941, 0.0 ,0.709717127 ,0.12180227, 0.0, 0.0], [44.18806406, 1.5073, 0.1529, 0.725033254 ,0.0 ,2.010490411, 0.01489, 6.549172098, 14.62330459 ,23.80934929, 0.713693133 ,0.237193894, 0.0, 0.300519976], [73.69796781, 1.3267, 0.344114773, 1.719504541, 0.699551839, 4.035984483, 0.01544 ,3.10157718 ,12.94580556 ,11.13847561 ,1.86474696, 0.237193894 ,0.0, 0.0],[65.0314905 ,1.1924 ,0.1629, 1.435369888 ,0.581317726 ,5.356306544, 1.675586957, 2.208222292, 21.83298126 ,4.078771012, 1.755406787, 0.12180227, 0.0 ,0.0],[43.42014834, 1.0651 ,0.1853, 0.705437761, 0.0 ,1.050256185 ,0.01826, 6.649831804, 15.05670099, 24.58698414, 0.622244988, 0.28847906 ,0.0, 0.228301998],[78.50292611 ,1.3264 ,0.409660444 ,0.38211212, 0.0 ,2.430592885 ,0.592124714, 0.949975972, 23.73482666, 7.623871051 ,0.067592107, 0.141034207, 0.0 ,0.0], [86.81835624, 17.28116974 ,0.229409848, 0.181258313, 0.0 ,2.400585566, 0.403148741,0.427803749, 21.21602873 ,8.256652348 ,0.013916022 ,0.141034207, 0.0 ,0.0], [72.24989818 ,10.74234875, 0.114 ,0.333123387 ,0.0, 3.855940565 ,0.365353547, 0.459259907 ,25.14209028, 7.463769759 ,0.095424151, 0.262836477, 0.0, 0.0], [57.59367832 ,1.1603, 0.1561, 0.54377494, 0.0 ,0.750182989 ,0.01447, 0.553628381, 31.11786189 ,5.504434899 ,0.230608366, 0.391049393, 0.0, 0.0], [36.66249009, 1.0227 ,0.1799, 0.916089314 ,0.0 ,0.67516469 ,0.239369565 ,0.0, 35.79854307, 5.100369733, 0.351876559, 0.435923913 ,0.0 ,0.0], [40.50206864 ,1.9456 ,0.721002381 ,2.429841175,2.689826087 ,4.996218709, 2.255113272 ,0.1195334 ,22.49582282 ,7.440898146,1.483050354 ,0.301300352, 0.0 ,0.0], [37.41943557, 1.42015, 0.1528 ,2.851144282, 0.906461538, 4.24603572, 1.354327803,2.15789244 ,26.66662587, 4.021591979 ,1.275304025 ,0.355790841, 0.0 ,0.0], [117.0084139, 6.227448553, 0.524365368 ,.381482281 ,1.517337793 ,20.47999561, 1.297635011 ,0.0 ,8.010185324 ,5.573049738 ,0.218680347, 0.160266145, 0.890185638, 0.0], [54.61, 0.0, 0.3 ,2.08, 1.2, 6.5, 1.27 ,0.45, 23.02, 4.19, 4.32 ,0.3 ,0.0 ,0.0], [45.02 ,0.0 ,0.0 ,3.12 ,0.54 ,4.16, 0.0, 0.7 ,30.61, 6.22, 6.34 ,0.23 ,0.0 ,0.0], ]))print('回归预测结果:', pred)ypred = clf.predict(X)print(ypred)print("-----------")index=0#plt.plot(Y,pred)plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文plt.title(f'sklearn神经网络---拟合度 for 铅钡:{score}\n')plt.legend(loc="best")plt.show()错误率随训练次数的变化图像代码如下
import numpy as npimport matplotlib.pyplot as pltfrom pylab import mpl# 设置显示中文字体import matplotlib; matplotlib.use('TkAgg')mpl.rcParams["font.sans-serif"] = ["SimHei"]matplotlib.rcParams['font.family'] = 'SimHei'matplotlib.rcParams['font.size'] = 10matplotlib.rcParams['axes.unicode_minus']=Falsedef sigmoid(x): return 1/(1+np.exp(-x))#前向计算def forward_NN(x,w,b): h1=sigmoid(w[0]*x[0]+w[1]*x[1]+b[0]) h2=sigmoid(w[2]*x[0]+w[3]*x[1]+b[0]) h3=sigmoid(w[4]*x[0]+w[5]*x[1]+b[0]) print(h1,h2,h3) o1=sigmoid(w[6]*h1+w[8]*h2+w[10]*h3+b[1]) o2=sigmoid(w[7]*h1+w[9]*h2+w[11]*h3+b[1]) return h1,h2,h3,o1,o2#反向传递 调整参数def fit(o1,o2,y,x,w,lrate,epochs): for i in range(epochs): #循环迭代 调整参数 p1=lrate*(o1-y[0])*o1*(1-o1) p2 = lrate * (o2 - y[1]) * o2 * (1 - o2) w[0]=w[0]-(p1*w[6]+p2*w[7]*h1*(1-h1)*x[0]) w[1] = w[1] - (p1 * w[6] + p2 * w[7] * h1 * (1 - h1) * x[1]) w[2] = w[2] - (p1 * w[8] + p2 * w[9] * h2 * (1 - h2) * x[0]) return wprint("步骤一 初始化参数")x=[3,6]y=[0,1]w=[0.6,0.61,0.62,0.63,0.64,0.65,0.66,0.67,0.68,0.69,0.70,0.71,0.72,0.73]b=[0.3,0.6]lrate=0.4print("步骤二 fit")print("步骤三 预测")print("真值为",y)sumDs=[]for epochs in range(0,101,5): h1,h2,h3,o1,o2=forward_NN(x,w,b)print("画图")plt.plot(range(0,101,5),sumDs)plt.title("the epoch-error plot for 铅钡")plt.xlabel("epochs")plt.ylabel("totol error")plt.show()由图6、图7可发现,当迭代次数超过20时,铅钡神经网络的错误率低于5%;对于高钾类的神经网络,当迭代次数超过15时,其错误率低于5%,放映了该模型的准确性。
观察发现表单2中49号风化文物以及50号风化文物样本既有风化前的数据,又有风化后的数据,故可将其风化前的数据作为真实值,风化后的数据代入神经网络模型,预测出其风化前的数据,并与真实值作比较,发现预测结果与真实值相差不大。进一步预测数据的正确性及合理性。
我们将预测的结果放在附录里面。
且我们将预测出来的未风化的数据与原本未风化玻璃文物的数据一同存放在一个数据表中,记为未风化数据集。
问题二
问题2模型的建立与求解
关于分析高钾玻璃以及铅钡玻璃分类规律的探寻,建立在问题1所得未风化数据的基础上,首先将数据进行可视化得到各成分均值折线图,从中选取几个较为重要的分类指标,再做出样本散点图将高钾玻璃、铅钡玻璃进行比对,探寻未风化玻璃的分类规律。
分别对高钾玻璃以及铅钡玻璃进行亚类分析时,可以利用主成成分析法对指标数量进行降维处理,分别求出高钾玻璃以及铅钡玻璃的几个主成成分,再利用系统聚类分析法,根据聚类系数折线图确定亚分类数目,对各个样本点进行亚分类,并将亚分类结果放在附录中。
对于亚分类结果的敏感性分析,拟采用二元回归Logistics模型,确定各个分类的概率的概率函数,在利用Python的机器灵敏度分析算法,求出各个主成成分对于模型分类结果的一阶灵敏度,进而进行灵敏度分析。
分类成分指标的选取与分类规律分析
(1)指标选取
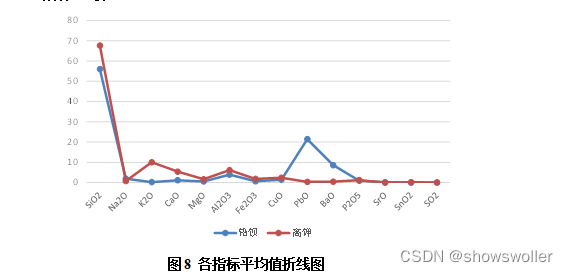
利用未风化数据集,分别求出高钾玻璃以及铅钡玻璃的各指标平均值折线图,将其汇总到同一图表中进行比较分析,发现两类在K2O,PbO以及BaO指标均值含量上差异较大,其余成分指标均值相差较小。因此,我们主要对K2O,PbO以及BaO这三个指标来分析高钾玻璃以及铅钡玻璃的分类规律。
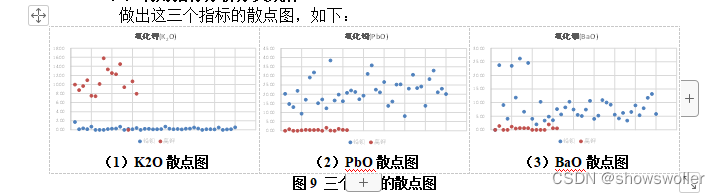
-
-
- 基于主成成分分析法的聚类分析模型
-
(1)两种玻璃的主成成分选取
由于玻璃的指标数量过多(14个),不利于进行亚类分析,拟采用主成成分分析法进行降维,选取的每个主成分均是原始指标的线性组合,且彼此之间互不相关。每个主成成分对应的贡献率反映了其能代表原始数据信息的多少,最终选取累计贡献率超过80%的主成成分个数,其能反映出原始数据的大部分信息。
通过模型求解,选取贡献率超过80%的对应的第一、第二、…、第个主成分。第个主成分为:
表5 高钾类主成成分分析结果表
| SiO2 | Na2O | K2O | CaO | MgO | Al2O3 | Fe2O3 | 特征值 | |
| a1 | 0.434 | -0.399 | -0.235 | -0.459 | 0.165 | -0.178 | -0.007 | 3.496 |
| a2 | -0.228 | -0.157 | -0.237 | 0.121 | 0.170 | 0.346 | 0.489 | 2.959 |
| a3 | -0.144 | -0.249 | 0.278 | -0.057 | 0.142 | -0.183 | 0.142 | 2.256 |
| a4 | -0.189 | 0.178 | 0.307 | -0.004 | 0.334 | 0.404 | 0.009 | 1.816 |
| … | … | … | … | … | … | … | … | … |
| CuO | PbO | BaO | P2O5 | SrO | SnO2 | SO2 | ||
| a1 | -0.078 | -0.049 | 0.290 | 0.203 | 0.297 | 0.309 | -0.101 | |
| a2 | 0.320 | -0.025 | 0.255 | 0.417 | 0.138 | -0.319 | 0.048 | |
| a3 | 0.082 | -0.577 | -0.374 | 0.031 | 0.155 | 0.102 | 0.498 | |
| a4 | -0.471 | 0.039 | -0.146 | 0.149 | 0.434 | 0.201 | -0.259 | |
| … | … | … | … | … | … | … | … |
表6 铅钡类主成成分分析结果表
| SiO2 | Na2O | K2O | CaO | MgO | Al2O3 | Fe2O3 | 特征值 | |
| a1 | -0.300 | -0.068 | -0.276 | -0.225 | -0.359 | -0.419 | -0.301 | 3.633 |
| a2 | -0.482 | -0.341 | 0.089 | 0.470 | 0.235 | -0.103 | 0.222 | 2.421 |
| a3 | -0.035 | -0.233 | 0.182 | 0.012 | 0.080 | 0.292 | 0.129 | 1.941 |
| a4 | 0.025 | -0.254 | -0.017 | -0.035 | -0.121 | -0.213 | 0.167 | 1.374 |
| … | … | … | … | … | … | … | … | … |
| CuO | PbO | BaO | P2O5 | SrO | SnO2 | SO2 | ||
| a1 | 0.336 | 0.076 | 0.351 | -0.035 | 0.135 | -0.332 | 0.110 | |
| a2 | 0.016 | 0.369 | -0.044 | 0.278 | 0.280 | -0.095 | -0.065 | |
| a3 | 0.477 | -0.477 | 0.427 | 0.307 | -0.010 | 0.197 | 0.180 | |
| a4 | -0.165 | -0.198 | -0.223 | 0.428 | -0.615 | -0.399 | 0.090 | |
| … | … | … | … | … | … | … | … |
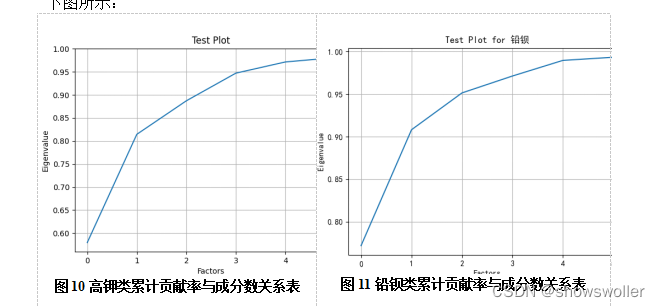
并分别生成高钾类以及铅钡类的累计贡献率与主成成分个数关系折线图如下图所示:
主成分分析部分代码如下
from sklearn.decomposition import PCAimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport matplotlib; matplotlib.use('TkAgg')from sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScalerfrom numpy.linalg import eigmatplotlib.rcParams['font.family'] = 'SimHei'matplotlib.rcParams['font.size'] = 10matplotlib.rcParams['axes.unicode_minus']=False#a=np.genfromtxt(r"未风化数据集.csv",usecols=range(2,16),encoding='utf-8',delimiter=",")#print(a)pd.set_option('display.max_rows', None) # 展示所有行pd.set_option('display.max_columns', None) # 展示所有列t=pd.read_csv(r"C:\Users\Admin\Desktop\未风化数据集.csv")#print(t)a=t[t['类型']=='铅钡']#print(a)print(a.values)X = np.array([[79.6 ,1.62 ,1.72 ,1.15 ,1.16 ,8.6 ,2.34 ,0.16 ,24.18 ,0.0 ,0.71 ,0.12 ,0.0 ,0.0], [ 44.19 ,1.51 ,0.15 ,0.73, 0.0 ,2.01 ,0.01 ,6.55, 14.62 ,23.81 ,0.71 ,0.24 ,0.0 ,0.3], [73.7 ,1.33 ,0.34 ,1.72 ,0.7 ,4.04 ,0.02 ,3.1 ,12.95 ,11.14 ,1.86, 0.24 ,0.0 ,0.0] ,[65.03 ,1.19 ,0.16, 1.44 ,0.58 ,5.36 ,1.68 ,2.21 ,21.83 ,4.08 ,1.76 ,0.12 ,0.0 ,0.0], [37.36 ,0.0 ,0.71 ,0.0 ,0.0 ,5.45 ,1.51 ,4.78 ,9.3 ,23.55 ,5.75 ,0.0 ,0.0 ,0.0], [31.94 ,0.0, 0.0 ,0.47 ,0.0 ,1.59 ,0.0 ,8.46 ,29.14 ,26.23 ,0.14 ,0.91 ,0.0 ,0.0], [ 43.42 ,1.07 ,0.19 ,0.71 ,0.0 ,1.05 ,0.02 ,6.65 ,15.06 ,24.59 ,0.62 ,0.29 ,0.0 ,0.23], [35.635 ,0.0, 0.705 ,4.365 ,0.745 ,4.105 ,2.43 ,0.0 ,38.48, 10.32 ,0.705 ,0.415 ,0.42 ,0.0], [65.91 ,0.0 ,0.0 ,1.6 ,0.89 ,3.11 ,4.59 ,0.44 ,16.55, 3.42 ,1.62 ,0.3 ,0.0 ,0.0], [ 69.71, 0.0, 0.21 ,0.46 ,0.0 ,2.36 ,1.0 ,0.11 ,19.76 ,4.88 ,0.17 ,0.0, 0.0 ,0.0], [75.51, 0.0 ,0.15 ,0.64 ,1.0 ,2.35 ,0.0 ,0.47 ,16.16 ,3.55 ,0.13 ,0.0 ,0.0 ,0.0], [78.5, 1.33 ,0.41 ,0.38, 0.0 ,2.43 ,0.59 ,0.95 ,23.73 ,7.62 ,0.07 ,0.14 ,0.0 ,0.0], [65.91 ,0.0, 0.0 ,0.38 ,0.0 ,1.44 ,0.17 ,0.16 ,22.05 ,5.68 ,0.42 ,0.0 ,0.0 ,0.0], [86.82 ,17.28 ,0.23 ,0.18 ,0.0 ,2.4 ,0.4 ,0.43 ,21.22 ,8.26 ,0.01 ,0.14 ,0.0 ,0.0], [60.12 ,0.0 ,0.23 ,0.89 ,0.0 ,2.72 ,0.0 ,3.01 ,17.24 ,10.34 ,1.46 ,0.31 ,0.0 ,3.66], [72.25 ,10.74 ,0.11 ,0.33 ,0.0 ,3.86 ,0.37 ,0.46 ,25.14 ,7.46 ,0.1 ,0.26 ,0.0 ,0.0], [57.59, 1.16 ,0.16 ,0.54 ,0.0, 0.75 ,0.01 ,0.55 ,31.12 ,5.5 ,0.23 ,0.39 ,0.0 ,0.0], [36.66 ,1.02, 0.18 ,0.92 ,0.0 ,0.68 ,0.24, 0.0 ,35.8 ,5.1 ,0.35 ,0.44 ,0.0 ,0.0], [40.5 ,1.95 ,0.72 ,2.43 ,2.69 ,5.0 ,2.26 ,0.12 ,22.5 ,7.44 ,1.48 ,0.3 ,0.0 ,0.0], [37.42 ,1.42 ,0.15 ,2.85 ,0.91 ,4.25 ,1.35 ,2.16, 26.67 ,4.02 ,1.28 ,0.36 ,0.0 ,0.0], [61.28 ,2.66 ,0.11, 0.84 ,0.74, 5.0, 0.0 ,0.53 ,15.99 ,10.96, 0.0 ,0.23, 0.0 ,0.0], [55.21, 0.0 ,0.25, 0.0 ,1.67 ,4.79, 0.0, 0.77 ,25.25 ,10.06, 0.2 ,0.43 ,0.0 ,0.0], [ 51.54 ,4.66 ,0.29 ,0.87 ,0.61 ,3.06 ,0.0 ,0.65 ,25.4, 9.23, 0.1 ,0.85 ,0.0 ,0.0], [117.01, 6.23 ,0.52 ,1.38, 1.52 ,20.48, 1.3, 0.0 ,8.01 ,5.57 ,0.22 ,0.16 ,0.89 ,0.0], [54.61 ,0.0 ,0.3 ,2.08 ,1.2 ,6.5 ,1.27 ,0.45 ,23.02 ,4.19 ,4.32 ,0.3 ,0.0 ,0.0], ])data=pd.read_csv(r"\数据2.csv")pd.set_option('display.max_rows', None) # 展示所有行sio2=data['二氧化硅(SiO2)']gaojia=data[data['类型']=='铅钡']gj=data[(data['类型']=='铅钡')&(data['二氧化硅(SiO2)'])]gj1=gj['二氧化硅(SiO2)']gj2=gj['氧化钠(Na2O)']gj3=gj['氧化钾(K2O)']gj4=gj['氧化钙(CaO)']gj5=gj['氧化镁(MgO)']gj6=gj['氧化铝(Al2O3)']gj7=gj['氧化铁(Fe2O3)']gj8=gj['氧化铜(CuO)']gj9=gj['氧化铅(PbO)']gj10=gj['五氧化二磷(P2O5)']gj11=gj['氧化锶(SrO)']gj12=gj['氧化锡(SnO2)']gj13=gj['二氧化硫(SO2)']gj14=gj['氧化铅(PbO)']#print(gj4)#print(gj3.shape)'''print(gj1)print(gj2)print(gj3)print(gj4)''''''na2o=data['氧化钠(Na2O)']k2o=data['氧化钾(K2O)']cao=data['氧化钙(CaO)']mgo=data['氧化镁(MgO)']alo=data['氧化铝(Al2O3)']feo=data['氧化铁(Fe2O3)']cuo=data['氧化铜(CuO)']pbo=data['氧化铅(PbO)']bao=data['氧化钡(BaO)']po=data['五氧化二磷(P2O5)']sro=data['氧化锶(SrO)']sno=data['氧化锡(SnO2)']so=data['二氧化硫(SO2)']''''''print(gaojia)print(sio2)print(na2o)print(k2o)print(cao)print(mgo)print(alo)print(feo)print(cuo)print(pbo)print(bao)print(po)print(sro)print(sno)print(so)'''#Y = np.array([22, 300, 4.25, 1.86, 210, 18, 3, 2])# n_components指定降维后的维数StandardScaler()pca = PCA(n_components=6)print("pca---------")print(pca)# 应用于训练集数据进行PCA降维pca.fit(X)# 用X来训练PCA模型,同时返回降维后的数据newX = pca.fit_transform(X)print("newx---------")print(newX)# 将降维后的数据转换成原始数据,pca_new = pca.transform(X)print("shape-----------")print(pca_new.shape)# 输出具有最大方差的成分print("最大方差---------")print(pca.components_)# 输出所保留的n个成分各自的方差百分比print("保留n个成分方差百分比----------")print(pca.explained_variance_ratio_)# 输出特征值print("特征值")print(pca.explained_variance_)print("输出形状")print(pca.components_.shape)# 输出未处理的特征维数print("未经处理-----------")print(pca.n_features_)# 输出训练集的样本数量print("训练集样本数量---------")print(pca.n_samples_)# 输出协方差矩阵print("协方差矩阵-------------")print(pca.noise_variance_)# 每个特征的奇异值# 用生成模型计算数据精度矩阵print("数据精度矩阵-----------")print(pca.get_precision())# 计算生成特征系数矩阵covX = np.around(np.corrcoef(X.T), decimals=6)# 输出特征系数矩阵print("特征系数矩阵------------")print(covX)#cov=pd.DataFrame(covX)eigenvalue,eigenvectors=eig(covX)print("特征向量-----")print(eigenvectors)# 求解协方差矩阵的特征值和特征向量featValue, featVec = np.linalg.eig(covX)# 将特征进行降序排序featValue = sorted(featValue)[::-1]# 图像绘制# 同样的数据绘制散点图和折线图np.cumsum(pca.explained_variance_ratio_)plt.plot(np.cumsum(pca.explained_variance_ratio_))#plt.scatter(range(1, X.shape[1] + 1), featValue)#plt.plot(range(1, X.shape[1] + 1), featValue)# 显示图的标题plt.title("Test Plot for 铅钡")# xy轴的名字plt.xlabel("因子")plt.ylabel("累计贡献率")# 显示网格plt.grid()# 显示图形plt.show()对于某个主成分而言,指标前面的系数越大,代表该指标对于主成分的影响越大。
从F1的表达式中可以看出,高钾类型的第一主成成分在SiO2以及SnO2上具有较大的正载荷,在其余变量上有负载荷或较小的正载荷,则第一主成成分可称为锡类主成分。第二主成成分在Fe2O3和P2O5上具有较大的正载荷,在其余变量上有负载荷或较小的正载荷,则第二主成成分定义为铁-铅类主成分。第三主成成分在SO2上具有较大的主成成分,而在其余变量上的载荷较小或未负载荷,因此第三主成成分可称为硫类主成分。
同理,从图6可知,对于铅钡类,当选取的主成成分个数为2时,这两个个主成成分的累计贡献率约为95%,足以反映原始数据的绝大部分信息。
- 基于聚类分析的亚分类模型
本文拟采用聚类分析模型进行亚分类,分别根据高钾玻璃与铅钡玻璃的各个主成成分的指标数据进行聚类,求出最合适的聚类数量,以此完成亚分类。

Step2: 利用肘部法则确定K值
分别使用SPSS软件对高钾类以及铅钡类的主成成分数据进行系统聚类,再利用Excel软件做出聚类系数与聚类中心数目K值关系的散点图,如下:
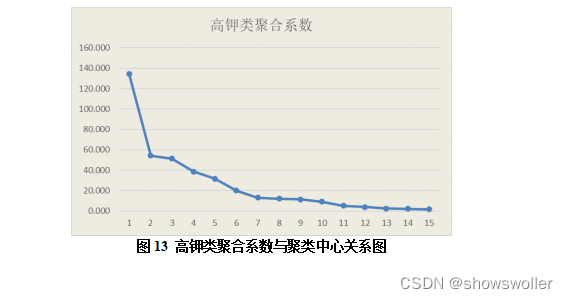
根据高钾类的聚合系数折线图可知,当类别数K值从1到2,折线图形畸变程度变化最大。超过2以后,畸变程度变化显著降低,因此肘部就是K=2,故可将类别数设定为2。
对于铅钡的分析类似 有需要请点赞关注后私信博主
Step3:聚类结果分析
分别对高钾玻璃和铅钡玻璃进行系统聚类分析,得到其分别谱系图如下图所示:

通过上述肘部法则得到的K=3,我们可以利用以上聚类分析在SPSS中得到的谱系图,将高钾类的16个样本分成3类,将铅钡类的33个样本同样分成3类,即可得到系统聚类分析的结果:
表7 高钾类亚分类表
| 文物编号 | 1 | 3 | 4 | 5 | 6 | 7 | 9 | 10 |
| 分类 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 文物编号 | 12 | 13 | 14 | 16 | 18 | 21 | 22 | 27 |
| 分类 | 1 | 1 | 1 | 1 | 2 | 2 | 1 | 1 |
表8 铅钡类亚分类表
| 文物编号 | 2 | 8 | 11 | 19 | 20 | 23 | 24 | 25 | 26 | 28 |
| 分类 | 1 | 2 | 1 | 1 | 2 | 2 | 3 | 2 | 2 | 1 |
| 文物编号 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 |
| 分类 | 1 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 1 |
| 文物编号 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 |
| 分类 | 2 | 3 | 2 | 2 | 2 | 1 | 1 | 2 | 2 | 1 |
| 文物编号 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 |
| 分类 | 2 | 2 | 2 | 2 | 1 | 2 | 2 | 1 | 2 | 1 |
分类结果的合理性及敏感性分析
- 合理性分析
本问分别利用高钾类以及铅钡类的主成成分数据进行聚类分析。对于高钾类玻璃的亚分类,利用相关系数的折线图以及肘部法则可得到其分为2类,其中,文物编号为18,21的样本为第二类,其余为第一类,观察18号和21号的三个主成成分数据可知,其与其它样本数据的欧式距离较大,因此这两个样本点可额外合为一类,分析结果与系统聚类的结果一致,即该聚类模型的分类结果较为合理
- 敏感性分析
首先对高钾类玻璃进行敏感性分析,根据上述聚类分析结果,可知高钾类玻璃可亚分为两类,利用二元Logistics回归原理:求出该模型的分类概率函数为:
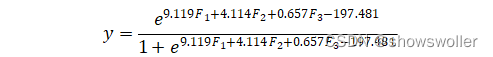
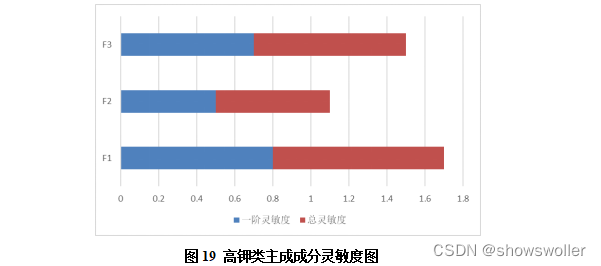
利用Python敏感性分析代码对该函数进行分析,最终得到该分类概率函数的敏感性如图所示:
敏感性分析部分代码如下
from SALib.sample import saltellifrom SALib.analyze import sobolfrom pylab import *import matplotlib.pyplot as pltimport pandas as pdimport matplotlib.ticker as mtickerimport matplotlib; matplotlib.use('TkAgg')mpl.rcParams['font.sans-serif'] = ['SimHei'] # 修复中文乱码plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号np.seterr(divide='ignore', invalid='ignore') # 消除被除数为0的警告problem = { 'num_vars': 4, # 模型变量的数量 'names': ['变量三', '误差因子', '变量二', '变量1'], # 模型的变量 'bounds': [[2000, 10000], [0, 0.2], [0.1, 0.5], [1, 30], ] # 指定变量的范围,一一对应}def evaluate(xx): # 进行灵敏度分析的模型 return np.array([x[0] * np.power(1 - (1 - np.power(1 - x[1], 1.4263 * np.power(x[1], -0.426))) * x[2], ''' 注意返回的是np.array([function for x in X]) function是函数表达式 比如function(T,PT,Pr,i)=T+PT+Pr+i 那么function就写成x[0]+x[1]+x[2]+x[3] 很显然,一一对应定义模型中的变量,注意列表下标从0开始'''samples = 128param_values = saltelli.sample(problem, samples)print('模型运行次数', len(param_values))Y = evaluate(param_values)print('ST:', Si['ST']) # 总灵敏度print('S1:', Si['S1']) # 一阶灵敏度print("S2 Parameter:", Si['S2'][0, 1]) # 二阶灵敏度# 一阶灵敏度与总灵敏度图片df_sensitivity = pd.DataFrame({ "Parameter": problem["names"], "一阶灵敏度": Si["S1"], "总灵敏度": Si["ST"]}).set_index("Parameter")fig, axes = plt.subplots(figsize=(10, 6))df_sensitivity.plot(kind="bar", ax=axes, rot=45, fontsize=16)# 二阶灵敏度图片second_order = np.array(Si['S2'])pd.DataFrame(second_order, index=problem["names"], columns=problem["names"])figs, axes = plt.subplots(figsize=(8, 10))ax_image = axes.matshow(second_order, vmin=-1.0, vmax=1.0, cmap="RdYlBu")cbar = figs.colorbar(ax_image)ax_image.axes.set_xticks(range(len(problem["names"])))ax_image.axes.set_xticklabels(problem["names"], rotation=45, fontsize=24)#r = ax_image.axes.set_yticklabels([""] + problem["names"], fontsize=24)plt.show()关于数据集和完整代码可以关注点赞收藏后私信博主要
有问题在评论区留言
来源地址:https://blog.csdn.net/jiebaoshayebuhui/article/details/126929465
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341












