

Java多线程案例之线程池


文章目录
1. 什么是线程池
线程池和和字符串常量池, 数据库连接池一样, 都是为了提高程序的运行效率, 减少开销; 随着并发程度的提高, 当我们去频繁的创建和销毁线程, 此时程序的开销还是挺大的, 为了进一步提高效率, 就引入了线程池, 程序中所创建的线程都会加载到一个 “池子” 中, 当程序需要使用线程的时候, 可以直接从池里面获取, 用完了就将线程还给池, 这样在多线程的环境中就不用去重复的创建和销毁线程, 从而使程序的运行效率提高, 线程池是管理线程的方式之一.
🎯那为什么从线程池中“拿”线程会比直接创建线程要更加高效呢?
这是因为创建线程和销毁线程, 是交由操作系统内核完成的, 而我们使用线程池调度线程是在用户态实现的(用户代码中就能实现的,不必交给内核操作);
如果将任务交给内核态, 就需要通过系统调用, 让内核来执行任务, 但此时你不清楚内核身上背负着多少任务(内核不是只给一个应用程序服务, 是要给所有的程序都提供服务), 当使用系统调用, 执行内核代码的时候, 无法确定内核都要做哪些工作, 整体过程"不可控"的;
相比于内核来说, 用户态, 程序执行的行为是可控的, 用户态只去完成你所指定的任务, 效率更高, 开销更小.
2. Java标准库提供的线程池
Java中提供了线程池相关的标准类ThreadPoolExecutor, 也被称作多线程执行器, 该类中的线程包括两类, 一类是核心线程, 另一类是非核心线程, 当核心线程都被占用还不能满足程序任务执行的需求时, 就会启用非核心线程, 直到任务量少了, 随之非核心线程也就会销毁.
jdk8中提供了4个构造方法, 这里主要介绍和理解参数最多的那一个构造方法, 其他构造方法只是基于这里的减少了参数而已.
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)为了便于理解这里参数之间的关系, 我们使用生活中的例子来类比理解, 假设这里有一家公司:
corePoolSize表示核心线程数, 公司的正式员工.
- 🎯那核心线程数最合适值是多少呢? 假设CPU有N核心, 最适核心线程数是N? 是2N? 是1.5N? 只要你能够说出一个具体的数, 那就错了, 最适的核心线程数要视情况和业务场景而定, 没有一个绝对的标准的值.
maximumPoolSize表示最大线程数,就是核心线程数与非核心线程数之和, 公司的正式员工和请来的零时工(非核心线程), 现有的工作正式工干不完时, 就会招来零时工帮忙干活.keepAliveTime非核心线程最长等待新任务的时间, 超过此时间, 该线程就会被销毁; 就是相当于零时工最长摸鱼时间, 公司里面是不养闲人的, 零时工长时间没有工作干就会被辞退了, 整体的策略, 正式员工保底, 临时工动态调节.unit上面参数的时间单位.workQueue线程池的任务队列(阻塞队列), 通过submit方法将任务注册到该队列中.threadFactory线程工厂, 线程创建的方案.handler拒绝策略, 描述了当线程池任务队列满了, 如果继续添加任务会以什么样的方式处理.
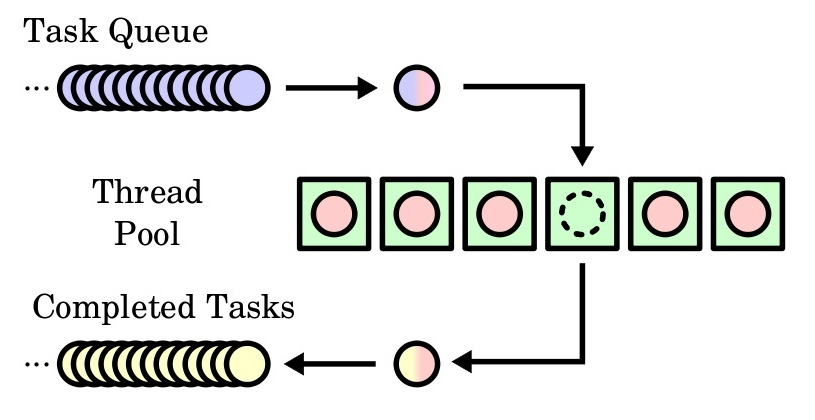
在Java标准库中提供了4个拒绝策略, 如下:
| Modifier and Type | Class and Description |
|---|---|
| static class | ThreadPoolExecutor.AbortPolicy 如果任务太多, 队列满了, 直接抛出异常RejectedExecutionException . |
| static class | ThreadPoolExecutor.CallerRunsPolicy 如果任务太多, 队列满了, 多出来的任务, 谁加的, 谁负责执行. |
| static class | ThreadPoolExecutor.DiscardOldestPolicy 如果任务太多, 队列满了, 丢弃最旧的未处理的任务. |
| static class | ThreadPoolExecutor.DiscardPolicy 如果任务太多, 队列满了, 丢弃多出来的任务. |
下面的是其他的几个构造方法:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler)使用线程池时, 往往使用的是ExecutorServerce,ExecutorServerce是ThreadPoolExecutor所实现的一个接口, 其中最重要的一个方法是submit方法, 这个方法能够将任务交给线程池去执行.
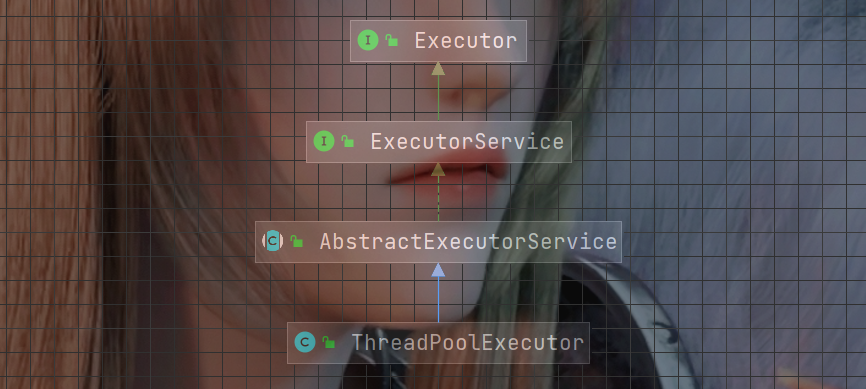
下面列出一些常见的创建线程池的方法:
import java.util.concurrent.*;public class TestDemo { public static void main(String[] args) { //创建一个固定数量的线程池 // 1. 创建一个操作无界队列且固定大小线程池 ExecutorService pool1 = Executors.newFixedThreadPool(10); //线程池中线程的数量是动态变化的 // 2. 用来处理大量短时间工作任务的线程池,如果池中没有可用的线程将创建新的线程,如果线程空闲60秒将收回并移出缓存 ExecutorService pool2 = Executors.newCachedThreadPool(); //线程池中只有一个线程 // 3. 创建一个操作无界队列且只有一个工作线程的线程池 ExecutorService pool3 = Executors.newSingleThreadExecutor(); //线程池中只有一个线程+定时器功能 // 4. 创建一个单线程执行器,可以在给定时间后执行或定期执行。 ExecutorService pool4 = Executors.newSingleThreadScheduledExecutor(Executors.defaultThreadFactory()); //创建一个固定数量的线程池+定时器功能 // 5. 创建一个指定大小的线程池,可以在给定时间后执行或定期执行。 ExecutorService pool5 = Executors.newScheduledThreadPool(3, Executors.defaultThreadFactory()); // 6. 创建一个指定大小(不传入参数,为当前机器CPU核心数)的线程池,并行地处理任务,不保证处理顺序 ExecutorService pool6 = Executors.newWorkStealingPool(); // 7. 自定义线程池 ExecutorService pool7 = new ThreadPoolExecutor(3, 10, 10000, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } }观察上面代码中前6种创建方式, 都是使用Executors(线程池的工具类)调用一个方法返回一个对象来创建线程池对象, 与第7种直接new对象的方式不同, 通过前6种方式创建出来的线程池, 本质上也是通过包装ThreadPoolExecutor来实现出来的.
这种使用普通方法(一般是静态的)代替构造方法创建对象的思想就是 “工厂模式”, 我们称这样的方法为 “工厂方法”, 相当于是把new操作隐藏在了方法里面, 提供这个工厂方法的类, 称为 “工厂类”, “工厂模式” 也是 “设计模式” 的一种.
使用示例:
下面的代码中要注意lambda表达式变量捕获的问题.
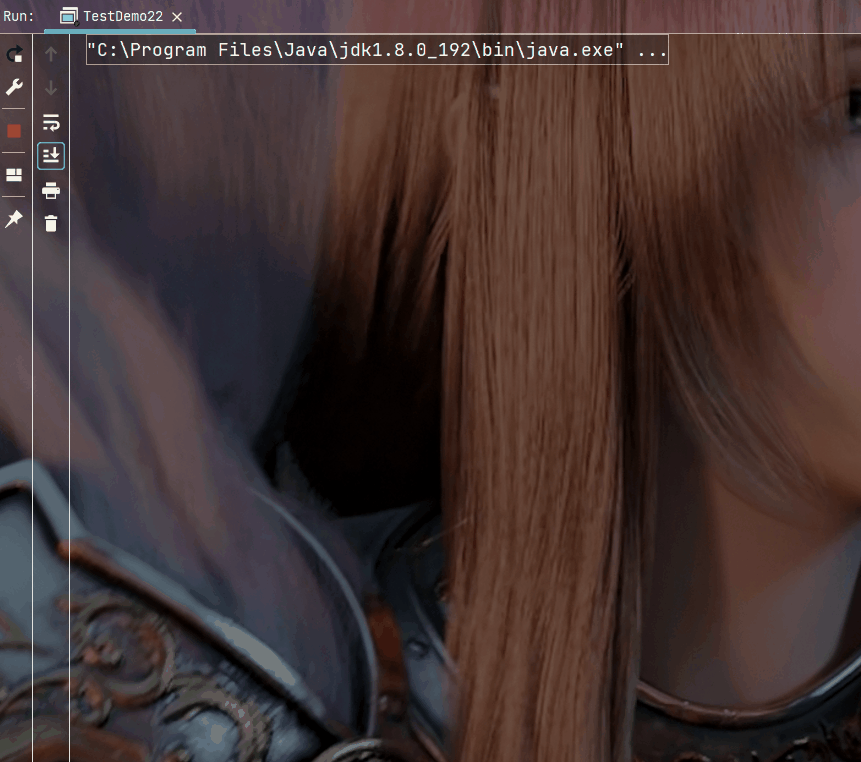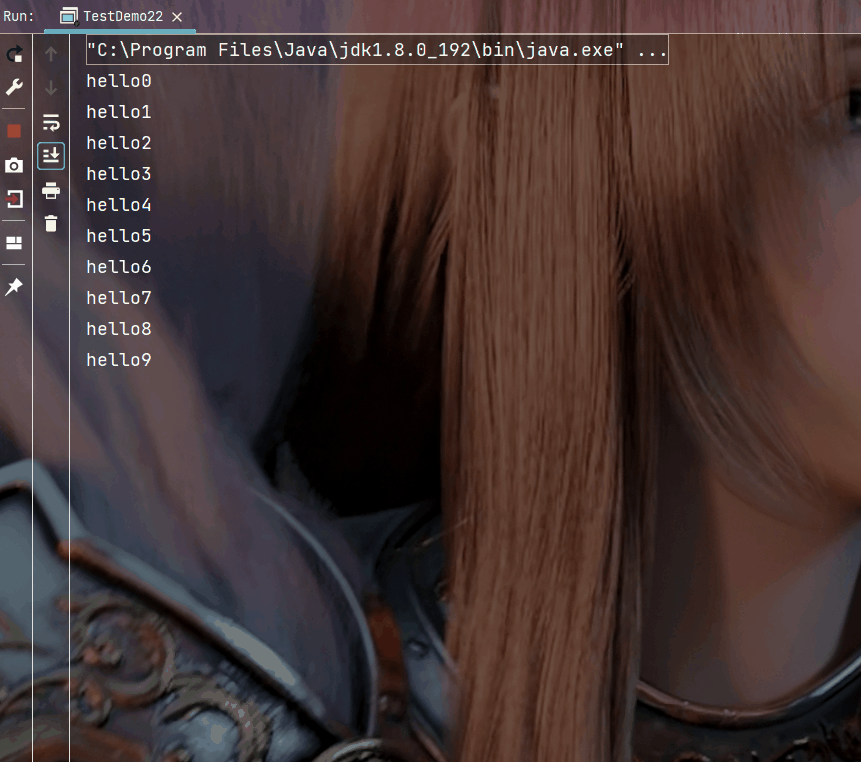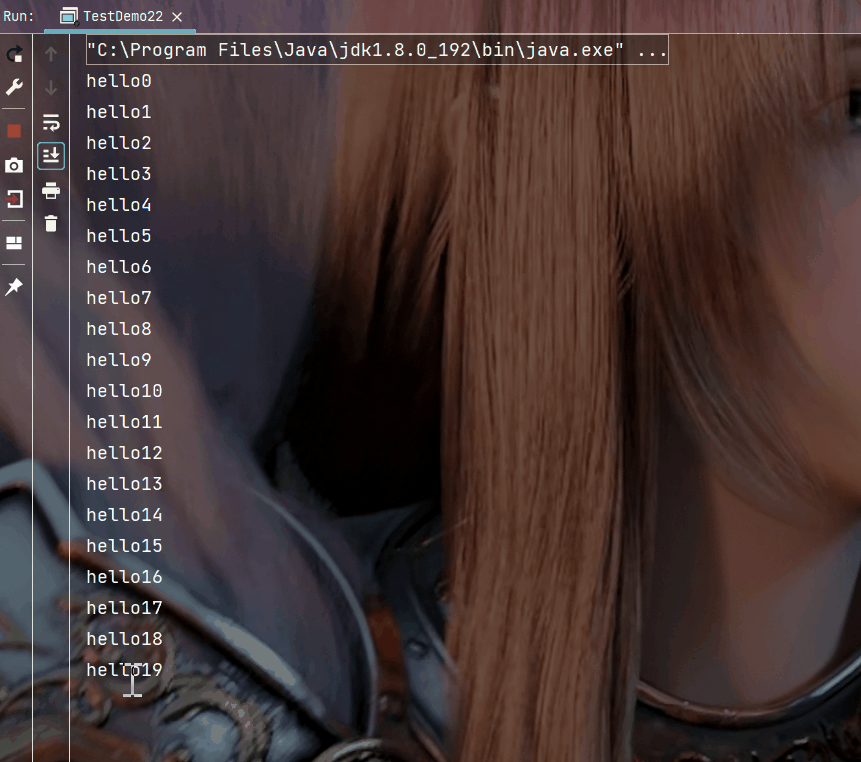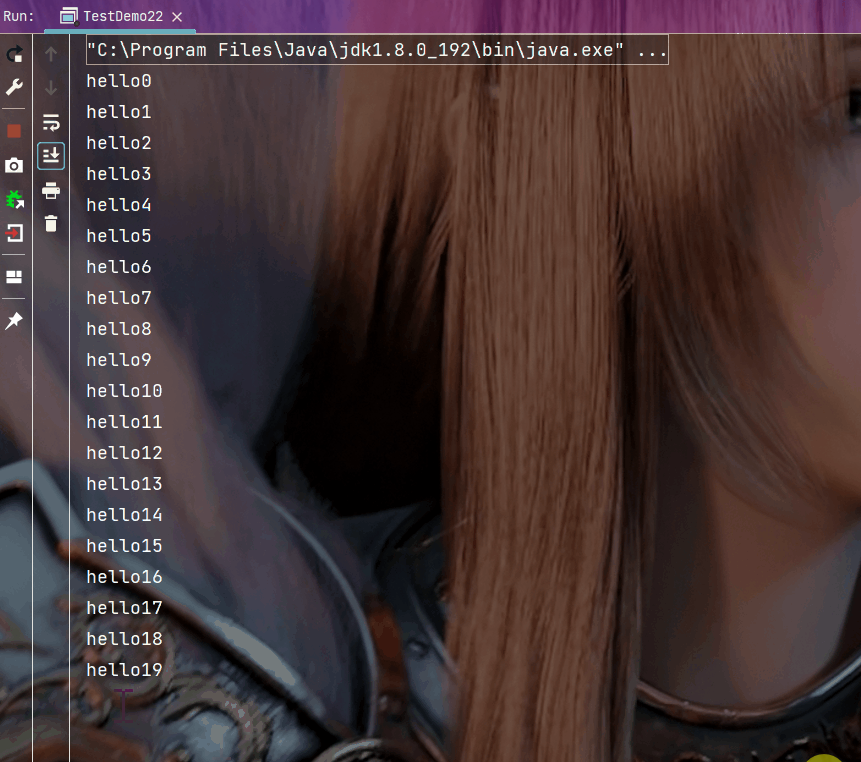
import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;public class TestDemo22 { public static void main(String[] args) { ExecutorService pool = Executors.newFixedThreadPool(10); for (int i = 0; i < 1000; i++) { int n = i;//注意变量捕获 pool.submit(new Runnable() { @Override public void run() { System.out.println("hello" + n); } }); Thread.sleep(200); } }}执行结果:
这里简单实现一个固定数量的线程池, 包含以下内容:
- 任务, 可以直接使用
Runnable实现. - 组织任务的数据结构, 使用阻塞队列
BlockingQueue即可. - 若干个工作线程, 工作线程要通过一个循环不断的从阻塞队列中获取任务.
- 注册任务的方法
submit, 将任务添加到阻塞队列当中.
代码实现:
import java.util.concurrent.BlockingQueue;import java.util.concurrent.LinkedBlockingQueue;class MyThreadPool { //使用阻塞队列来保存任务 private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(); //这里创建出若干个工作线程,n表示线程的数量 public MyThreadPool(int n) { for (int i = 0; i < n; i++) { Thread t = new Thread(() -> { while (!Thread.interrupted()) { try { Runnable runnable = queue.take(); runnable.run(); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); t.start(); } } //注册任务给线程池 public void submit(Runnable runnable) { try { queue.put(runnable); } catch (InterruptedException e) { throw new RuntimeException(e); } }}下面来测试一下这里实现的线程池:
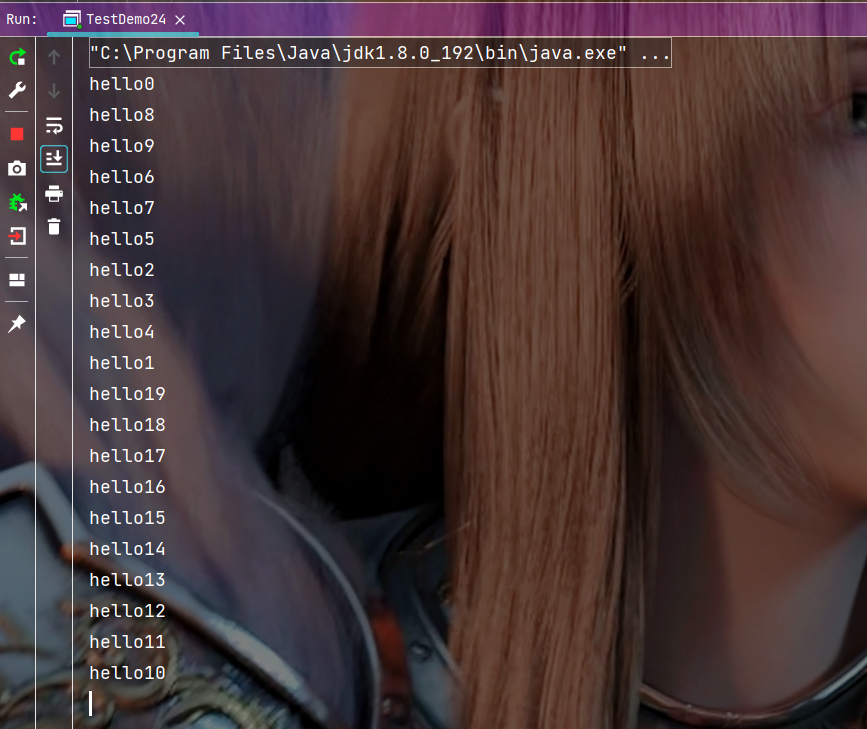
public class TestDemo24 { public static void main(String[] args) { //创建10个线程 MyThreadPool pool = new MyThreadPool(10); for (int i = 0; i < 20; i++) { int n = i;//注意变量捕获的问题 pool.submit(new Runnable() { @Override public void run() { System.out.println("hello" + n); } }); } }}执行结果:
由于操作系统的随机调度, 这里的执行顺序是不固定的.
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341













