

python数据处理—None/NULL/NaN的理解及实际应用情况


文章目录
一、python中None、null和NaN
注意:python中没有null,只有和其意义相近的None。
1、None
1)数据类型
None表示空值,一个特殊Python对象,None的类型是NoneType。
None是NoneType数据类型的唯一值,我们不能创建其它NoneType类型的变量,但是可以将None赋值给任何变量。
type(None) #该值是一个空对象,空值是python里面一个特殊的值,用None表示。None不能理解为0,因为0是有意义,而None是一个特殊的空值。type('')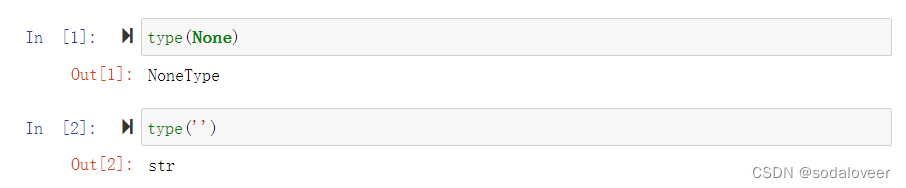
2)特征:
- None不支持任何运算
- None和任何其他数据类型比较永远返回False
- None有自己的数据类型NoneType,不能创建其他NoneType对象。(它只有一个值None)
- None与0、空列表、空字符串不一样。
- None赋值给任何变量,也可以给None值变量赋值
- None没有像len、size等属性,要判断一个变量是否为None,直接使用。
None==0 None==‘’None==Falsedir(None) #返回参数属性、方法列表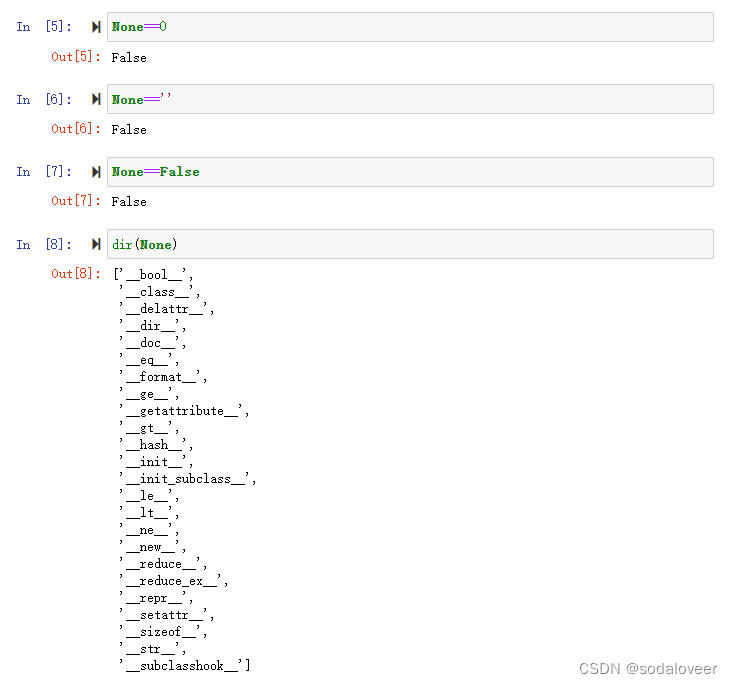
3)作为没有return关键函数的返回值
对于所有没有return语句的函数定义,python都会在末尾加上return None,使用不带值的return语句(也就是只有return关键字本身),那么就返回None。
def fun1():print('test')result=fun()print(result)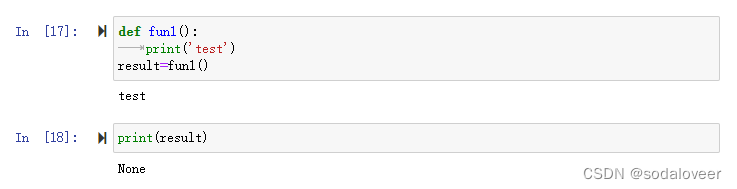
2、NaN
1)当使用Numpy或者Pandas处理数据的时候,会自动将条目中没有数据转换为NaN。
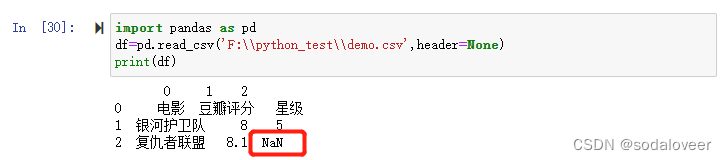
import pandas as pddf=pd.read_csv('F:\\python_test\\demo.csv',header=None)print(df)原数据为下图:

2)特征
- NaN是没有办法和任何数据进行比较
- 它和任何值都不相等,包括他自己。
- 它的数类型是float,但是和任何值做计算的结果都是NaN
frame= pd.DataFrame([[1, 2, 3], [2, 3, 4], [3, 4, np.nan]], index=list('abc'), columns=list('ABC'))num=frame.iloc[2,2]result=num+2result
二、实际应用
1、使用read_sql读取null数据显示NaN
使用hive进行数据清洗、特征处理后,用python读取hive数据库下的整理好的表。一般使用pyhive连续数据库,pandas读取数据。
pandas读取hive数据库下面的数据表
如果数据表字段为string格式,pandas读取后在python中该字段数据格式为object,如果该字段中含有 NULL 值,读取会直接转换成字符串** ‘NULL’ **,如果该字段中含有’'(空值),读取直接转换成字符串 ** ‘’ **。
2、如果数据表字段为int格式,pandas读取后在python中该字段数据格式为float64,如果该字段中含有 NULL 值或者 ‘’(空值),读取直接转换成字符串 NaN。
如果数据库表的字段为string,字段中含NULL,多数意义就是默认为空值或者异常数值,使用pd.DataFrame或者read_sql()读取,默认为字符串‘NULL’。因此对此进行数值处理会导致很多报错(比如ValueError: could not convert string to float: ‘NULL’),比如想要在python转换数据类型的时候,或者想要对null进行缺失值填充等等。因此想要将“NULL”转换成“NaN”,后续更加方便。
from pyhive import hiveimport pandas as pdimport numpy as np#缺失值统计def na_count(data): data_count=data.count() na_count=len(data)-data_count na_rate=na_count/len(data) na_result=pd.concat([data_count,na_count,na_rate],axis=1) return na_resultsql='''select is_vice_card,online_days,age,payment_type,star_level_int,cert_cnt,channel_nbr,payment_method_variable,package_price_group,white_flag from database.v1_6_501_train_test''' con=hive.connect(host='b1m6.hdp.dc',port=10000,auth='KERBEROS',kerberos_service_name="hive") cursor=con.cursor()cursor.execute(sql) #执行sqlresult=cursor.fetchall()data_pos_1=pd.DataFrame(result,columns=['is_vice_card','online_days','calling_cnt','age','payment_type','star_level_int','cert_cnt','channel_nbr','payment_method_variable','package_price_group'])print("未将‘NULL’替换成np.nan,查看train_data的缺失值:\n",na_count(data_pos_1))#将str字段中的null转换成空值data_pos_1.loc[data_pos_1['is_vice_card']=='NULL','is_vice_card'] = np.nandata_pos_1.loc[data_pos_1['online_days']=='NULL','online_days'] = np.nandata_pos_1.loc[data_pos_1['age']=='NULL','age'] = np.nandata_pos_1.loc[data_pos_1['payment_type']=='NULL','payment_type'] = np.nandata_pos_1.loc[data_pos_1['star_level_int']=='NULL','star_level_int'] = np.nandata_pos_1.loc[data_pos_1['cert_cnt']=='NULL','cert_cnt'] = np.nandata_pos_1.loc[data_pos_1['channel_nbr']=='NULL','channel_nbr'] = np.nandata_pos_1.loc[data_pos_1['payment_method_variable']=='NULL','payment_method_variable'] = np.nandata_pos_1.loc[data_pos_1['package_price_group']=='NULL','package_price_group'] = np.nanprint("将‘NULL’替换成np.nan,查看train_data的缺失值:\n",na_count(data_pos_1))运行代码,结果显示:
查看未将“NULL”替换成np.nan,data_pos_1的缺失值: 0 1 2is_vice_card 8289 0 0.0online_days 8289 0 0.0calling_cnt 8289 0 0.0age 8289 0 0.0payment_type 8289 0 0.0star_level_int 8289 0 0.0cert_cnt 8289 0 0.0channel_nbr 8289 0 0.0payment_method_variable 8289 0 0.0package_price_group 8289 0 0.0查看将“NULL”替换成np.nan,data_pos_1的缺失值:; 0 1 2is_vice_card 7854 435 0.052479online_days 7854 435 0.052479calling_cnt 8289 0 0.000000age 7854 435 0.052479payment_type 7854 435 0.052479star_level_int 7830 459 0.055375cert_cnt 6134 2155 0.259983channel_nbr 7847 442 0.053324payment_method_variable 7890 399 0.048136package_price_group 8289 0 0.000000也可以在数据库表建立将字段设置为int。
2、使用read_csv读取null数据显示为字符串null
一般默认为NaN
import pandas as pddata_pos=pd.read_csv(file_pos,encoding='utf-8')data_pos.head(10)
显示为字符串为null
import pandas as pddata_pos=pd.read_csv(file_pos,encoding='utf-8', na_filter=False)#或data_pos=pd.read_csv(file_pos,encoding='utf-8', keep_default_na=False)#查看data_pos数据格式data_pos[data_pos['online_days']=='NULL'].head(10)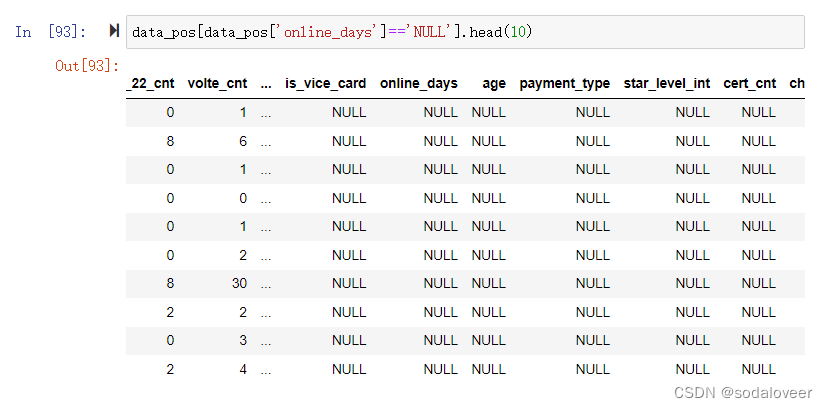
来源地址:https://blog.csdn.net/sodaloveer/article/details/129791858
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
















