

Kotlin的Collection与Sequence操作异同点是什么

本文小编为大家详细介绍“Kotlin的Collection与Sequence操作异同点是什么”,内容详细,步骤清晰,细节处理妥当,希望这篇“Kotlin的Collection与Sequence操作异同点是什么”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
Collection 的常见操作
Collection 集合,Kotlin的集合类型和Java不一样,Kotlin的集合分为可变(读写)和不可变(只读)类型(lists, sets, maps, etc),可变类型是在不可变类型前面加Mutable,以我们常用的三种集合类型为例:
List<out E> - MutableList<E>Set<out E> - MutableSet<E>Map<K, out V> - MutableMap<K, V>其实他们的区别就是List实现了Collection接口,而MutableList实现的是List和MutableCollection接口。而 MutableCollection 接口实现了Collection 接口,并且在里面添加了add和remove等操作方法。
可变不可变只是为了区分只读和读写的操作,他们的操作符方式都是相同的。
集合的操作符说起来可就太多了
累计
//对所有元素求和list.sum()//将集合中的每一个元素代入lambda表达式,然后对lambda表达式的返回值求和list.sumBy { it % 2}//在一个初始值的基础上,从第一项到最后一项通过一个函数累计所有的元素list.fold(100) { accumulator, element -> accumulator + element / 2}//同fold,只是迭代的方向相反list.foldRight(100) { accumulator, element -> accumulator + element / 2}//同fold,只是accumulator的初始值就是集合的第一个元素,element从第二个元素开始list.reduce { accumulator, element -> accumulator + element / 2}//同reduce但方向相反:accumulator的初始值就是集合的最后一个元素,element从倒数第二个元素开始往前迭代list.reduceRight { accumulator, element -> accumulator + element / 2}val list = listOf(1, 2, 3, 4, 5, 6)//只要集合中的任何一个元素满足条件(使得lambda表达式返回true),any函数就返回truelist.any { it >= 0}//集合中的全部元素都满足条件(使得lambda表达式返回true),all函数才返回truelist.all { it >= 0}//若集合中没有元素满足条件(使lambda表达式返回true),则none函数返回truelist.none { it < 0}//count函数的返回值为:集合中满足条件的元素的总数list.count { it >= 0}遍历
//遍历所有元素list.forEach { print(it)}//同forEach,只是可以同时拿到元素的索引list.forEachIndexed { index, value -> println("position $index contains a $value")}showFields.forEach { (key, value) ->最大最小
//返回集合中最大的元素,集合为空(empty)则返回nulllist.max()//返回集合中使得lambda表达式返回值最大的元素,集合为空(empty)则返回nulllist.maxBy { it }//返回集合中最小的元素,集合为空(empty)则返回nulllist.min()//返回集合中使得lambda表达式返回值最小的元素,集合为空(empty)则返回nulllist.minBy { it }过滤(去除)
//返回一个新List,去除集合的前n个元素list.drop(2)//返回一个新List,去除集合的后n个元素list.dropLast(2)//返回一个新List,去除集合中满足条件(lambda返回true)的第一个元素list.dropWhile { it > 3}//返回一个新List,去除集合中满足条件(lambda返回true)的最后一个元素list.dropLastWhile { it > 3}//返回一个新List,包含前面的n个元素list.take(2)//返回一个新List,包含最后的n个元素list.takeLast(2)//返回一个新List,仅保留集合中满足条件(lambda返回true)的第一个元素list.takeWhile { it>3}//返回一个新List,仅保留集合中满足条件(lambda返回true)的最后一个元素list.takeLastWhile { it>3}//返回一个新List,仅保留集合中满足条件(lambda返回true)的元素,其他的都去掉list.filter { it > 3}//返回一个新List,仅保留集合中不满足条件的元素,其他的都去掉list.filterNot { it > 3}//返回一个新List,仅保留集合中的非空元素list.filterNotNull()//返回一个新List,仅保留指定索引处的元素list.slice(listOf(0, 1, 2))映射
//将集合中的每一个元素代入lambda表达式,lambda表达式必须返回一个元素//map的返回值是所有lambda表达式的返回值所组成的新List//例如下面的代码和listOf(2,4,6,8,10,12)将产生相同的Listlist.map { it * 2}//将集合中的每一个元素代入lambda表达式,lambda表达式必须返回一个集合//而flatMap的返回值是所有lambda表达式返回的集合中的元素所组成的新List//例如下面的代码和listOf(1,2,2,3,3,4,4,5,5,6,6,7)将产生相同的Listlist.flatMap { listOf(it, it + 1)}//和map一样,只是lambda表达式的参数多了一个indexlist.mapIndexed { index, it -> index * it}//和map一样,只不过只有lambda表达式的非空返回值才会被包含在新List中list.mapNotNull { it * 2}//根据lambda表达式对集合元素进行分组,返回一个Map//lambda表达式的返回值就是map中元素的key//例如下面的代码和mapOf("even" to listOf(2,4,6),"odd" to listOf(1,3,5))将产生相同的maplist.groupBy { if (it % 2 == 0) "even" else "odd"}元素
list.contains(2)list.elementAt(0)//返回指定索引处的元素,若索引越界,则返回nulllist.elementAtOrNull(10)//返回指定索引处的元素,若索引越界,则返回lambda表达式的返回值list.elementAtOrElse(10) { index -> index * 2}//返回list的第一个元素list.first()//返回list中满足条件的第一个元素list.first { it > 1}//返回list的第一个元素,list为empty则返回nulllist.firstOrNull()//返回list中满足条件的第一个元素,没有满足条件的则返回nulllist.firstOrNull { it > 1}list.last()list.last { it > 1 }list.lastOrNull()list.lastOrNull { it > 1 }//返回元素2第一次出现在list中的索引,若不存在则返回-1list.indexOf(2)//返回元素2最后一次出现在list中的索引,若不存在则返回-1list.lastIndexOf(2)//返回满足条件的第一个元素的索引list.indexOfFirst { it > 2}//返回满足条件的最后一个元素的索引list.indexOfLast { it > 2}//返回满足条件的唯一元素,如果没有满足条件的元素或满足条件的元素多于一个,则抛出异常list.single { it == 5}//返回满足条件的唯一元素,如果没有满足条件的元素或满足条件的元素多于一个,则返回nulllist.singleOrNull { it == 5}排序&逆序
val list = listOf(1, 2, 3, 4, 5, 6)//返回一个颠倒元素顺序的新集合list.reversed()list.sorted()//将每个元素代入lambda表达式,根据lambda表达式返回值的大小来对集合进行排序list.sortedBy { it*2}list.sortedDescending()list.sortedByDescending { it*2}personList.sortWith(compareBy({ it.age }, { it.name })) val c1: Comparator<Person> = Comparator { o1, o2 -> if (o2.age == o1.age) { o1.name.compareTo(o2.name) } else { o2.age - o1.age } }personList.sortWith(c1) //上面的自定义方式可以通过JavaBean实现Comparable 接口实现自定义的排序 data class Person(var name: String, var age: Int) : Comparable<Person> { override fun compareTo(other: Person): Int { if (this.age == other.age) { return this.name.compareTo(other.name) } else { return other.age - this.age } } } //sorted 方法返回排序好的list(已有有排序规则的用sorted,不要用sortedby了) val sorted = personList.sorted()Sequence 的常见操作
Sequence 是 Kotlin 中一个新的概念,用来表示一个延迟计算的集合。Sequence 只存储操作过程,并不处理任何元素,直到遇到终端操作符才开始处理元素,我们也可以通过 asSequence 扩展函数,将现有的集合转换为 Sequence ,代码如下所示
val list = mutableListOf<Person>() for (i in 1..10000) { list.add(Person("name$i", (0..100).random())) } list.asSequence()当我们拿到结果之后我们还能通过toList再转换为集合。
list.asSequence().toList()Sequence的操作符绝大部分都是和 Collection 类似的。常用的一些操作符是可以直接平替使用的。
val list2 = list.asSequence() .filter { it.age > 50 }.map { it.name }.take(3).toList()居然他们的操作符都长的一样,效果也都一样,导致 Sequence 与 Collection 就很类似,那么既生瑜何生亮!为什么需要这么个东西?既然 Collection 能实现效果为什么还需要 Sequence 呢?他们的区别又是什么呢?
区别与对比
Collection 是立即执行的,每一次中间操作都会立即执行,并且把执行的结果存储到一个容器中,没多一个中间操作符就多一个容器存储结果。
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> { return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)}public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> { return filterTo(ArrayList<T>(), predicate)}比如常用的 map 和 filter 都是会新建一个 ArrayList 去存储结果,
Sequence 是延迟执行的,它有两种类型,中间操作和末端操作 ,主要的区别是中间操作不会立即执行,它们只是被存储起来,中间操作符会返回另一个Sequence,仅当末端操作被调用时,才会按照顺序在每个元素上执行中间操作,然后执行末端操作。
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> { return TransformingSequence(this, transform)}public fun <T> Sequence<T>.filter(predicate: (T) -> Boolean): Sequence<T> { return FilteringSequence(this, true, predicate)}比如常用的 map 和 filter 都是直接返回 Sequence 的this 对象。
public inline fun <T> Sequence<T>.first(predicate: (T) -> Boolean): T { for (element in this) if (predicate(element)) return element throw NoSuchElementException("Sequence contains no element matching the predicate.")}然后在末端操作中,会对 Sequence 中的元素进行遍历,直到预置条件匹配为止。
这里我们举一个示例来演示一下:
我们使用同样的筛选与转换,来看看效果
val list = mutableListOf<Person>() for (i in 1..10000) { list.add(Person("name$i", (0..100).random())) } val time = measureTimeMillis { val list1 = list.filter { it.age > 50 }.map { it.name }.take(3) YYLogUtils.w("list1$list1") } YYLogUtils.w("耗费的时间$time") val time2 = measureTimeMillis { val list2 = list.asSequence() .filter { it.age > 50 }.map { it.name }.take(3).toList() YYLogUtils.w("list2$list2") } YYLogUtils.w("耗费的时间2$time2")运行结果:
当集合数量为10000的时候,执行时间能优秀百分之50左右:
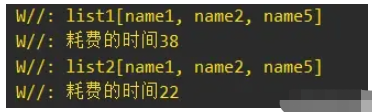
当集合数量为5000的时候,执行时间相差比较接近:
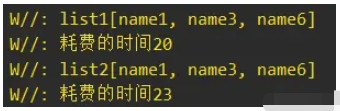
当集合数量为3000的时候,此时的结果就反过来了,Sequence延时执行的优化效果就不如List转换Sequence再转换List了:
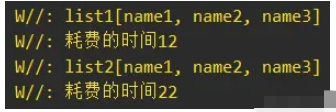
读到这里,这篇“Kotlin的Collection与Sequence操作异同点是什么”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注编程网行业资讯频道。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341














