kafka 是什么?
ApacheKafka是一个分布式流处理平台,用于处理大量实时数据。它基于发布-订阅模型,具有高吞吐量、低延迟、可扩展性、容错性和流式处理能力。广泛应用于金融、零售、物联网、社交媒体等领域,例如事件驱动架构、实时数据处理、日志聚合、物联网和社交媒体数据处理。与其他平台相比,Kafka以高吞吐量、低延迟、分布式和可扩展性、容错性和流式处理优势著称。
Mac上使用Docker搭建kafka集群方式
在Mac上使用Docker搭建Kafka集群遵循此指南,逐步在Mac上使用Docker搭建Kafka集群。从安装Docker和Homebrew开始,然后拉取Kafka镜像、创建ZooKeeper和Kafka代理容器、创建Kafka主题、生产和消费消息。最后,了解高级配置和清理技巧。请注意端口映射和容器状态,并利用Kafka管理工具进行简化管理。
Kafka 负载均衡在 vivo 的落地实践
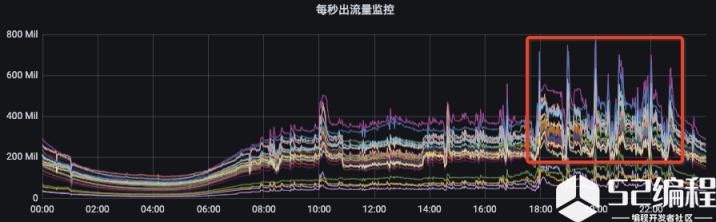
副本迁移是Kafka最高频的操作,对于一个拥有几十万个副本的集群,通过人工去完成副本迁移是一件很困难的事情。cruise control就是针对Kafka集群运维困难问题而诞生的,它能够很好的解决kafka运维困难的问题。
关于Kafka大数据环境中的应用解析
欢迎各位阅读本篇,Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。本篇文章讲述了关于Kafka大数据环境中的应用解析,课课家教育平台提醒各位:本篇文章纯干货~因此大家一定要认真阅读本篇文章哦!