python spark windows
1、下载如下放在D盘添加 SPARK_HOME = D:\spark-2.3.0-bin-hadoop2.7。 并将 %SPARK_HOME%/bin 添加至环境变量PATH。 然后进入命令行,输入pyspark命令。若成功执行。则成功设置
2024-12-23
理解Spark SQL(三)—— Spark SQL程序举例
上一篇说到,在Spark 2.x当中,实际上SQLContext和HiveContext是过时的,相反是采用SparkSession对象的sql函数来操作SQL语句的。使用这个函数执行SQL语句前需要先调用DataFrame的createOrReplaceTe
2024-12-23
Spark Operator浅析
本文作者: 林武康(花名:知瑕),阿里巴巴计算平台事业部技术专家,Apache HUE Contributor, 参与了多个开源项目的研发工作,对于分布式系统设计应用有较丰富的经验,目前主要专注于EMR数据开发相关的产品的研发工作。 本文介绍Spark Op
2024-12-23
Spark SQL(6) OptimizedPlan
Spark SQL(6) OptimizedPlan在这一步spark sql主要应用一些规则,优化生成的Resolved Plan,这一步涉及到的有Optimizer。之前介绍在sparksession实例化的是会实例化sessionState,进而确定Qu
2024-12-23
spark-sql-04-on_hive
设置metastore机器: ke01、ke02、ke03、ke04ke03 为元数据库ke01、ke02、ke04 连接到元数据库 、hive-metastore搭建ke03: hive.metastore.warehouse.dir
2024-12-23
Spark内存管理
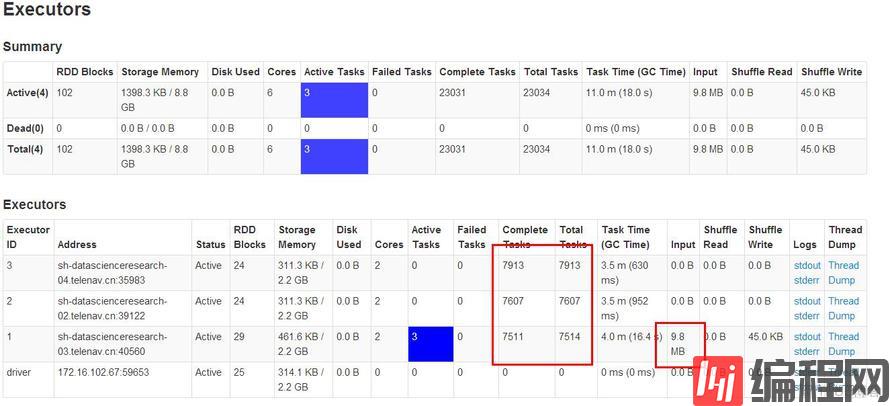
1、spark的一大特性就是基于内存计算,Driver只保存任务的宏观性的元数据,数据量较小,且在执行过程中基本不变,不做重点分析,而真正的计算任务Task分布在各个Executor中,其中的内存数据量大,且会随着计算的进行会发生实时变化,所以Executor
2024-12-23
Spark SQL怎么用
这篇文章主要介绍“Spark SQL怎么用”,在日常操作中,相信很多人在Spark SQL怎么用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Spark SQL怎么用”的疑惑有所帮助!接下来,请跟着小编一起来
2024-12-23
Spark怎么写HBASE
这篇文章将为大家详细讲解有关Spark怎么写HBASE,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。package com.iesol.high_frequencyimport java.io.Buffe
2024-12-23
Spark基础和RDD
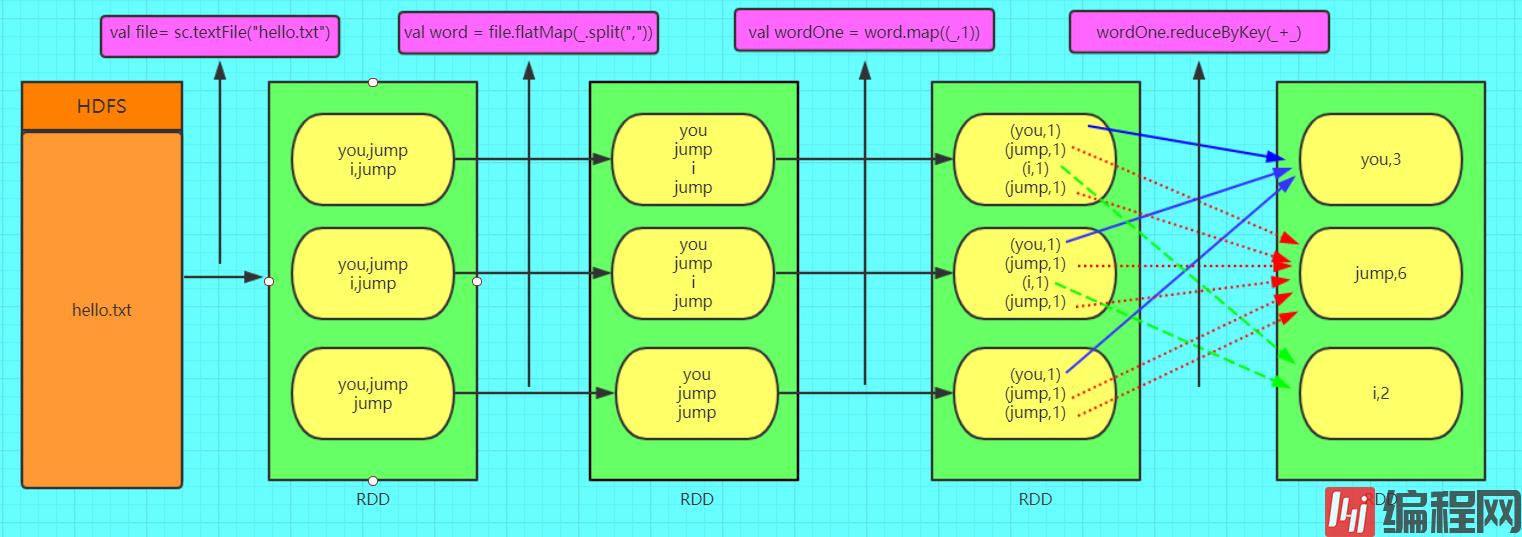
spark1. Spark的四大特性速度快spark比mapreduce快的两个原因基于内存1. mapreduce任务后期在计算的是时候,每一个job的输出结果都会落地到磁盘,后续有其他的job要依赖于前面job的输出结果,这个时候就需要进行大量的磁盘io操
2024-12-23
Spark调优指南
Spark相关问题Spark比MR快的原因?1) Spark的计算结果可以放入内存,支持基于内存的迭代,MR不支持。2) Spark有DAG有向无环图,可以实现pipeline的计算模式。3) 资源调度模式:Spark粗粒度资源调度,MR是细粒度资源调度。资源
2024-12-23
Spark中Broadcast的理解
广播变量应用场景:在提交作业后,task在执行的过程中,有一个或多个值需要在计算的过程中多次从Driver端拿取时,此时会必然会发生大量的网络IO,这时,最好用广播变量的方式,将Driver端的变量的值事先广播到每一个Worker端,以后再计算过程中只需要从本
2024-12-23
Spark RDD怎么创建
这篇文章主要介绍“ Spark RDD怎么创建”,在日常操作中,相信很多人在 Spark RDD怎么创建问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答” Spark RDD怎么创建”的疑惑有所帮助!接下来,请跟
2024-12-23
spark入门框架+python
目录:简介pysparkIPython Notebook安装配置spark编写框架:首先开启hdfs以及yarn1 sparkconf2 sparkcontext3 RDD(核心)4 transformation(核心)
2024-12-23























![[mysql]mysql8修改root密码](https://static.528045.com/imgs/47.jpg?imageMogr2/format/webp/blur/1x0/quality/35)





