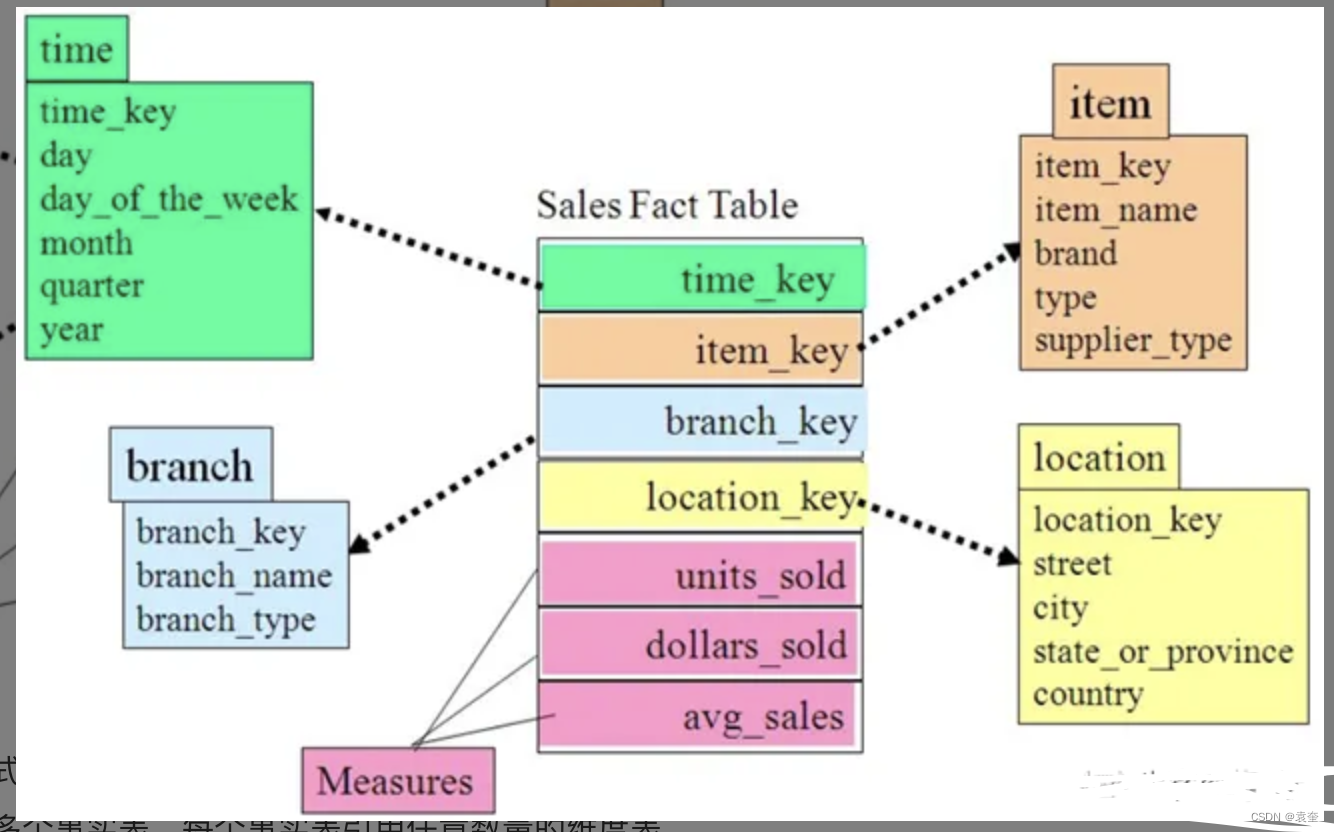
大数据Hadoop之——数据仓库Hive
目录一、概述二、Hive优点与使用场景1)优点2)使用场景三、Hive架构1)服务端组件1、Driver组件2、Metastore组件3、Thrift服务2)客户端组件1、CLI2、Thrift客户端3、WEBGUI3)Metastore详解四、Hive的工作
2024-12-23
Hive数据仓库如何使用
这篇文章将为大家详细讲解有关Hive数据仓库如何使用,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,
2024-12-23
hive数据仓库新增字段方法
目录新增字段1、方法1cascade知识2、方法2 (适用于外部表)3、方法3(下下策)修改字段删除列新增字段1、方法1alter taTyVzTble 表名 add columns (列名 string COMMENT '新添加的列'
2024-12-23
hadoop数据库怎么读取大量数据
Hadoop是一个开源的分布式存储和计算框架,可以帮助处理大量数据。要读取Hadoop数据库中的大量数据,可以使用Hadoop的MapReduce框架或Spark框架。在使用MapReduce框架时,可以编写一个MapReduce程序来读
2024-12-23
大数据Hadoop之——计算引擎Spark
目录一、概述1)Spark特点2)Spark适用场景二、Spark核心组件三、Spark专业术语详解1)Application:Spark应用程序2)Driver:驱动程序3)Cluster Manager:资源管理器4)Executor:执行器5)Worke
2024-12-23
大数据环境下互联网行业数据仓库/数据平台的架构之漫谈
导读:整体架构数据采集数据存储与分析数据共享数据应用实时计算任务调度与监控元数据管理总结一直想整理一下这块内容,既然是漫谈,就想起什么说什么吧。我一直是在互联网行业,就以互联网行业来说。先大概列一下互联网行业数据仓库、数据平台的用途:整合公
2024-12-23
数据挖掘和数据仓库之间的区别介绍
数据挖掘和数据仓库是两个不同的概念,分别用于不同的数据处理和分析目的。下面是它们之间的区别介绍:1. 定义:- 数据挖掘是指从大量的数据中发现隐藏的模式、关联、趋势和其他有价值的信息,并将其应用于实际问题的过程。数据挖掘主要关注的是发现新的
2024-12-23
数据仓库总结
1.为什么要做数仓建模 数据仓库建模的目标是通过建模的方法更好的组织、存储数据,以便在性能、成本、效率和数据质量之间找到最佳平衡点。 当有了适合业务和基础数据存储环境的模型(良好的数据模型),那么大数据就能获得以下好处: 当有了适合业务和基
2024-12-23
Hive实战之Youtube数据集
Hive是一个基于Hadoop的数据仓库基础设施,可以用于处理大规模的结构化数据。在Hive中,使用类似SQL的查询语言来处理数据,使得用户可以方便地进行数据分析和查询。在本实战中,我们将使用Hive来处理Youtube数据集。Youtub
2024-12-23