python3.7---爬取网页图片
#!/usr/bin/pythonimport reimport urllibimport urllib.request #python3中urlopen、urlritrieve都在request库里面了,所以要导入此库def html
2024-11-16
Python 爬取网页中JavaScri
当我们进行网页爬虫时,我们会利用一定的规则从返回的 HTML 数据中提取出有效的信息。但是如果网页中含有 JavaScript 代码,我们必须经过渲染处理才能获得原始数据。此时,如果我们仍采用常规方法从中抓取数据,那么我们将一无所获。那么,
2024-11-16
C++迭代器失效问题及解决
这篇文章主要介绍了C++迭代器失效问题及解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教
2024-11-16
c++迭代器失效的情况有哪些
在C++中,迭代器可以在以下情况下失效:添加和删除元素:如果在迭代器指向的容器中添加或删除元素,迭代器通常会失效。这是因为添加或删除元素可能导致容器重新分配内存或改变其内部数据结构,从而使迭代器无效。修改元素:如果通过迭代器修改容器中的元素
2024-11-16
map迭代器遍历失效怎么解决
如果在使用 map 迭代器遍历时失效,可能是因为在迭代器遍历的过程中修改了 map 的结构,导致迭代器失效。为了解决这个问题,可以采取以下几种方式:使用 for 循环遍历:不直接使用 map 迭代器,而是使用 for 循环遍历 map 中
2024-11-16
python如何爬取网页图片
要使用Python爬取网页图片,可以使用requests库来发送HTTP请求,然后使用beautifulsoup库或者正则表达式来解析网页内容,最后使用urllib库来下载图片。下面是一个简单的示例代码,可以爬取指定网页的所有图片并保存到本
2024-11-16
nodejs怎么爬取动态网页
要爬取动态网页,可以使用Node.js的一些库和工具,如Puppeteer、Cheerio和Axios。下面是一个使用这些工具的示例:1. 首先,使用npm安装所需的库和工具:```bashnpm install puppeteer che
2024-11-16
python动态网页批量爬取
四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页。我使用的是学信网,好了,网站截图如下:网站的代码
2024-11-16
使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 HTML 解析库, 可以编写出用于采集网络
2024-11-16
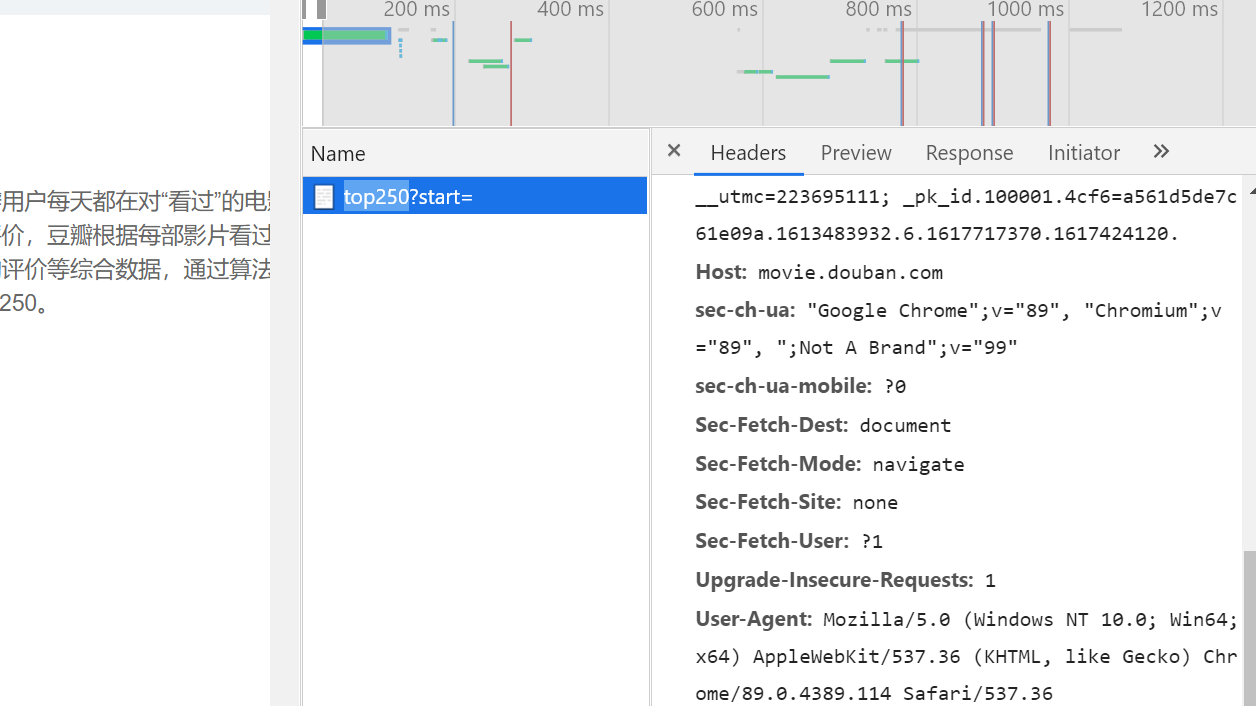
python怎么爬取豆瓣网页
这篇文章主要介绍了python怎么爬取豆瓣网页,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。python 语法简要介绍python 的基础语法大体与c语言相差不大,由于省去了
2024-11-16
如何用python爬取网页数据
要用Python爬取网页数据,可以使用Python的一些库和模块,例如requests、BeautifulSoup和Scrapy等。下面是一个简单的示例,使用requests和BeautifulSoup库来爬取网页数据:```pythoni
2024-11-16



![[C++] STL_vector 迭代器失效问题](https://file.lsjlt.com/upload/f/202309/07/1yaaukkzab1.gif)




















![[mysql]mysql8修改root密码](https://static.528045.com/imgs/16.jpg?imageMogr2/format/webp/blur/1x0/quality/35)




