

数据库之MySQL查询去重数据


最近遇到了一个问题,当时我的第一反应是导出来,用wps的Excel表格的删除重复项的功能,简单粗暴又直接,但是没有考虑到数据量太大的情况,会导致Excel打开缓慢。这个时候就考虑有没有更方便快捷的方法,网上也查询了很多方法,但是实践出真知,还是要实践之后才能得到真相。


开始实践:
先创建一个拥有重复数据的表。
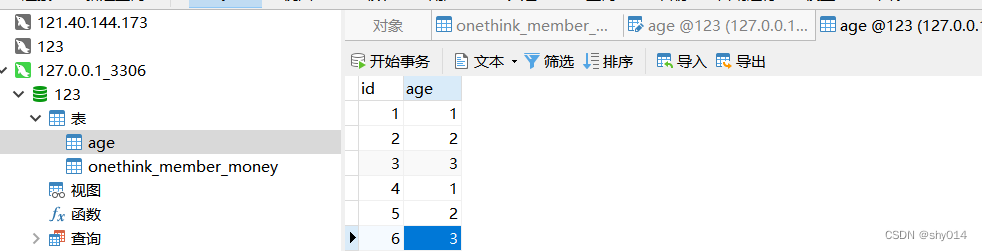
方法一:使用DISTINCT过滤重复数据
直接查询age字段,会输出所有数据,包含重复项。
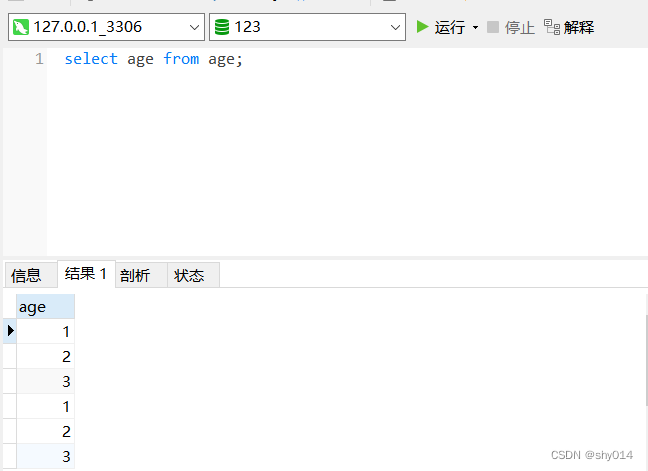
DISTINCT 关键字指示 MySQL 消除重复的记录值
SELECT DISTINCT <字段名> FROM <表名>;
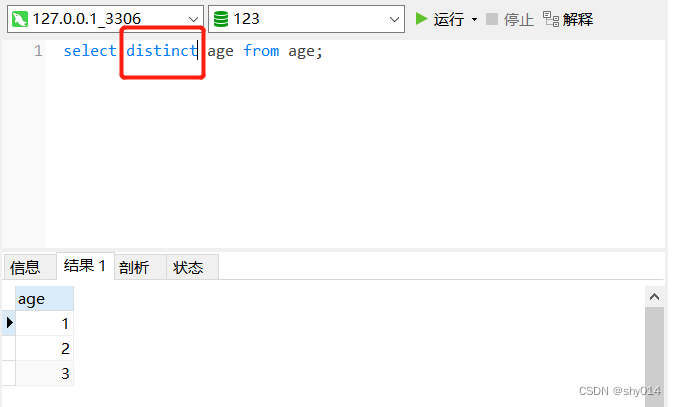
可以看到消除了重复项,使用distinct可行。
使用 DISTINCT 关键字时需要注意以下几点:
DISTINCT 关键字只能在 SELECT 语句中使用。
在对一个或多个字段去重时,DISTINCT 关键字必须在所有字段的最前面。
如果 DISTINCT 关键字后有多个字段,则会对多个字段进行组合去重,也就是说,只有多个字段组合起来完全是一样的情况下才会被去重。
方法二:group by
GROUP BY 语句根据一个或多个列对结果集进行分组。在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
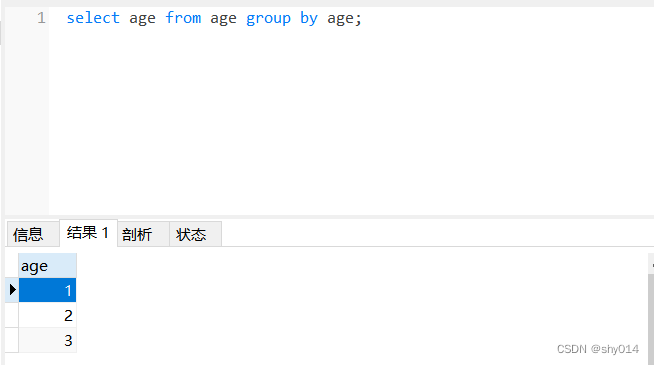
select 重复的字段名 from 表名 group by 重复的字段名;
group by 对age查询结果进行了分组,自动将重复的项归结为一组。
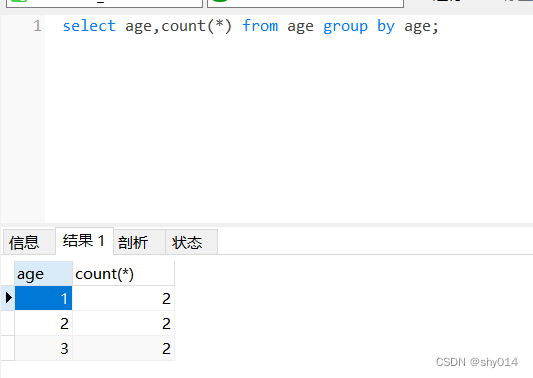
还可以使用count函数,统计重复的数据有多少个。
方法三: row_number窗口函数
oracle等数据库中可以方便的使用row_number函数,实现分组取组内特定数据的功能。但是MySQL中并没有引入类似的函数。为了实现这一功能,需要一些特别的处理。
row_number() over (partition by <用于分组的字段名> order by <用于组内排序的字段名>)select * from (select t.*,row_number() over(partition by t.children_id order by t.update_time DESC) rn
from mdm_data_authority_view_info t where t.DATA_CLASS_ID = '分类id' AND t.DATA_ROLE_ID
IN ( '角色id', '角色id' ))
where rn = 1;
来源地址:https://blog.csdn.net/qq_32393893/article/details/126850270
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341






![[mysql]mysql8修改root密码](https://static.528045.com/imgs/7.jpg?imageMogr2/format/webp/blur/1x0/quality/35)








