

多元线性回归LinearRegression


目录
1.3 linear_model.LinearRegression
1.1多元线性回归的基本原理
线性回归是机器学习中最简单的回归算法,多元线性回归指的就是一个样本有多个特征的线性回归问题。对于一个有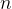 个特征的样本
个特征的样本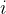 而言,它的回归结果如下方程:
而言,它的回归结果如下方程: ![]()
在这个表达式中,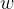 被统称为模型的参数,其中
被统称为模型的参数,其中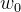 被称为截距(intercept),~
被称为截距(intercept),~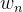 被称为回归系数(regression coefficient),有时也用
被称为回归系数(regression coefficient),有时也用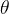 表示。其中
表示。其中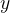 是目标变量,
是目标变量,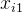 ~
~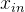 是样本上的不同特征。
是样本上的不同特征。
如果考虑有m个样本,是包含了m个全部样本的回归结果列向量,我们可以使用矩阵来表示这个方程,其中可以被看做是一个结构为(1,n)的列矩阵,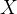 是一个结构为(m,n)的特征矩阵,则有:
是一个结构为(m,n)的特征矩阵,则有:

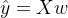
和标签值的线性关系,而构造预测模型的核心就是找出模型的参数向量。在多元线性回归中,我们将损失函数定义为: 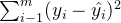
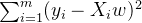 其中
其中 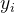 是样本 对应的真实标签,
是样本 对应的真实标签, 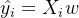 是样本 在一组参数 下的预测标签。首先,这个损失函数代表了 和
是样本 在一组参数 下的预测标签。首先,这个损失函数代表了 和 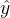 分别是真实标签和预测值,也就是说,这个损失函数是在计算真实标签和预测值之间的距离。因此,我们认为这个损失函数衡量了我们构造的模型的预测结果和真实标签的差异,我们也固然希望预测结果和真实值差异越小越好,所以我们的求解目标就可以转化成:
分别是真实标签和预测值,也就是说,这个损失函数是在计算真实标签和预测值之间的距离。因此,我们认为这个损失函数衡量了我们构造的模型的预测结果和真实标签的差异,我们也固然希望预测结果和真实值差异越小越好,所以我们的求解目标就可以转化成: 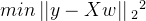 其中右下角的2表示向量
其中右下角的2表示向量 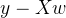 的L2范式,即损失函数所代表的的含义。在L2范式上开平方,就是损失函数,这个式子,也正是在sklearn当中,用在类Linear_model.LinearRegression背后的损失函数。这个式子通常被称作SSE(Sum of Squared Error,误差平方和)或者RSS(Residual Sum of Squares,残差平方和)。
的L2范式,即损失函数所代表的的含义。在L2范式上开平方,就是损失函数,这个式子,也正是在sklearn当中,用在类Linear_model.LinearRegression背后的损失函数。这个式子通常被称作SSE(Sum of Squared Error,误差平方和)或者RSS(Residual Sum of Squares,残差平方和)。 1.2 最小二乘法求解多元线性回归的参数
为了求解让RSS最小化的参数向量,通过最小化真实值和预测值之间的RSS来求解参数的方法叫做最小二乘法。最终得到参数最优解为。
1.3 linear_model.LinearRegression
class sklearn.linear_model.LinearRegression (fifit_intercept=True, normalize=False, copy_X=True, n_jobs=None)
| 参数 | 含义 |
|---|---|
| fit_intercept | 布尔值,可不填,默认为True 是否计算截距,如果设置为False,则不会计算截距。 |
| normalize | 布尔值,可不填,默认为False 当fit_intercept设置为False时,将忽略此参数,如果为True,则特征矩阵X在进入回归之前将会被减去均值(中心化)并除以L2范式(缩放)。 如果要进行标准化,则需在fit数据之前使用preprocessing模块中的标准化专用类StandarScaler |
| copy_X | 布尔值,可不填,默认为True 若为真,则将在X.copy()上进行操作,否则原本的特征矩阵X可能被线性回归影响并覆盖。 |
| n_jobs | 整数或None,可不填,默认为None 用于计算的作业数。只有在多标签的回归和数据量足够大的时候才生效。除非None在joblib.parallel_backend上下文中,否则None统一表示为1。如果输入-1,则表示使用全部的cpu来进行计算。 |
1.4 案例
from sklearn.linear_model import LinearRegression as LRfrom sklearn.model_selection import train_test_splitfrom sklearn.model_selection import cross_val_scorefrom sklearn.datasets import fetch_california_housing as fchimport pandas as pdhousevalue=fch()x=pd.DataFrame(housevalue.data)y=housevalue.targetx.columns=housevalue.feature_namesxtrain,xtest,ytrain,ytest=train_test_split(x,y,test_size=0.3,random_state=420)# 恢复索引for i in [xtrain,xtest]: i.index=range(i.shape[0])# 建模reg=LR().fit(xtrain,ytrain)yhat=reg.predict(xtest)#预测yhatreg.coef_ #w,系数向量array([ 4.37358931e-01, 1.02112683e-02, -1.07807216e-01, 6.26433828e-01, 5.21612535e-07, -3.34850965e-03, -4.13095938e-01, -4.26210954e-01])reg.intercept_ #截距-36.256893229203946[*zip(xtrain.columns,reg.coef_)][('MedInc', 0.43735893059684), ('HouseAge', 0.010211268294493828), ('AveRooms', -0.10780721617317682), ('AveBedrms', 0.6264338275363777), ('Population', 5.21612535346952e-07), ('AveOccup', -0.003348509646333501), ('Latitude', -0.41309593789477195), ('Longitude', -0.4262109536208474)]| 属性 | 含义 |
|---|---|
| coef_ | 数组,形状为(n_features),或者(n_taargets,n_features) 线性回归方程中估计出的系数。如果在fit中传递多个标签(当y为二维或以上的时候),则返回的系数形状为(n_targets,n_features)的二维数组,而如果仅传递一个标签,则返回的系数是长度为n_features的数组 |
| intercept_ | 数组,线性回归中的截距项 |
1.5 多元线性回归的模型评估指标
1.5.1 MSE均方误差&MAE绝对均值误差
RSS残差平方和,它的本质是我们的预测值与真实值之间的差异,所以RSS既是我们的损失函数,也是我们回归类模型的模型评估指标之一。但是,RSS有着致命的缺点:它是一个无界的和,可以无限地大。我们只知道,我们想要求解最小的RSS,从RSS的公式来看,它不能为负,所以RSS越接近0越好,但我们没有一个概念,究竟多小才算好,多接近0才算好?为了应对这种状况,sklearn中使用RSS的变体,均方误差MSE(mean squared error)来衡量我们的预测值和真实值的差异:
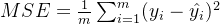
from sklearn.metrics import mean_squared_error as MSEMSE(yhat,ytest)0.5309012639324575虽然均方误差永远为正,但是 sklearn 中的参数 scoring 下,均方误差作为评判标准时,却是计算” 负均方误差 “ ( neg_mean_squared_error )。这是因为 sklearn 在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn 划分为模型的一种损失 (loss) 。在 sklearn 当中,所有的损失都使用负数表示,因此均方误差也被显示为负数了。真正的均方误差MSE 的数值,其实就是 neg_mean_squared_error去掉负号的数字。(2) 调用交叉验证的类cross_val_score 并使用里面的 scoring 参数
cross_val_score(reg,x,y,cv=10,scoring="neg_mean_squared_error").mean()-0.5509524296956613ytest.mean()2.0819292877906976测试集平均值为2.08,而均方误差却达到0.5,可见误差较大
除了MSE,我们还有与MSE类似的MAE(Mean absolute error,绝对均值误差):
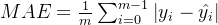
1.5.2 ![R^{2}]()
对于回归类算法而言,只探索数据预测是否准确是不足够的。除了数据本身的数值大小之外,我们还希望我们的模型能够捕捉到数据的”规律“,比如数据的分布规律,单调性等等,而是否捕获了这些信息并无法使用MSE来衡量。
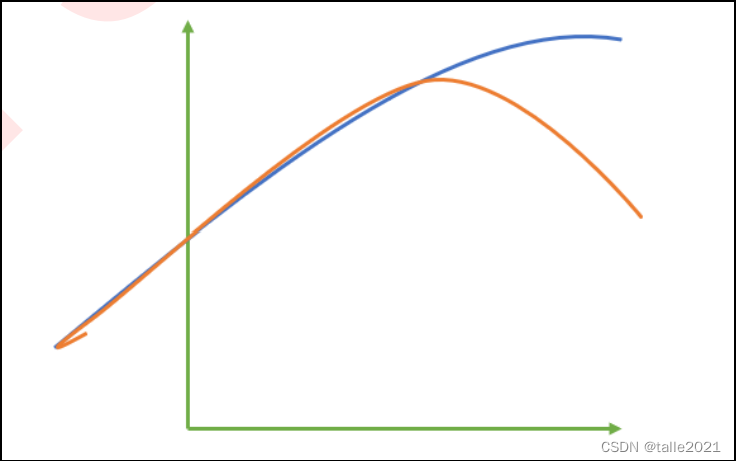
这张图中,其中红色线是我们的真实标签,而蓝色线是我们的拟合模型。这是一种比较极端,但的确可能发生的情况。这张图像上,前半部分的拟合非常成功,看上去我们的真实标签和我们的预测结果几乎重合,但后半部分的拟合却非常糟糕,模型向着与真实标签完全相反的方向去了。对于这样的一个拟合模型,如果我们使用MSE来对它进行判断,它的MSE会很小,因为大部分样本其实都被完美拟合了,少数样本的真实值和预测值的巨大差异在被均分到每个样本上之后,MSE就会很小。但这样的拟合结果必然不是一个好结果,因为一旦我的新样本是处于拟合曲线的后半段的,我的预测结果必然会有巨大的偏差,而这不是我们希望看到的。所以,我们希望找到新的指标,除 了判断预测的数值是否正确之外,还能够判断我们的模型是否拟合了足够多的,数值之外的信息。
为了衡量模型对数据上的信息量的捕捉,我们定义了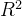 和可解释性方差分数(explained_variance_score,EVS):
和可解释性方差分数(explained_variance_score,EVS):
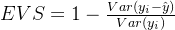
是我们的真实标签,是我们的预测结果,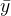 是我们的均值, Var 表示方差。方差的本质是任意一个值和样本均值的差异,差异越大,这些值所带的信息越多。在 和EVS 中,分子是真实值和预测值之差的差值,也就是我们的模型没有捕获到的信息总量,分母是真实标签所带的信息量,所以两者都衡量 1 - 我们的模型没有捕获到的信息 量占真实标签中所带的信息量的比例 ,所以,两者都是越接近 1 越好。 也可以使用三种方式来调用,一种是直接从metrics中导入 r2_score ,输入预测值和真实值后打分。第二种是直接从线性回归LinearRegression的接口 score 来进行调用。第三种是在交叉验证中,输入 "r2" 来调用。 EVS 有两种调用方法,可以从metrics 中导入,也可以在交叉验证中输入 ”explained_variance“ 来调用。 (1)直接从metrics中导入 r2_score
是我们的均值, Var 表示方差。方差的本质是任意一个值和样本均值的差异,差异越大,这些值所带的信息越多。在 和EVS 中,分子是真实值和预测值之差的差值,也就是我们的模型没有捕获到的信息总量,分母是真实标签所带的信息量,所以两者都衡量 1 - 我们的模型没有捕获到的信息 量占真实标签中所带的信息量的比例 ,所以,两者都是越接近 1 越好。 也可以使用三种方式来调用,一种是直接从metrics中导入 r2_score ,输入预测值和真实值后打分。第二种是直接从线性回归LinearRegression的接口 score 来进行调用。第三种是在交叉验证中,输入 "r2" 来调用。 EVS 有两种调用方法,可以从metrics 中导入,也可以在交叉验证中输入 ”explained_variance“ 来调用。 (1)直接从metrics中导入 r2_score # 调用R2from sklearn.metrics import r2_scorer2_score(ytest,yhat) # 或:r2_score(y_true=ytest,y_pred=yhat)0.6043668160178813(2)从线性回归LinearRegression的接口score来进行调用
r2=reg.score(xtest,ytest)r20.6043668160178813(3)EVS调用方法,可以从metrics中导入,也可以在交叉验证中输入”explained_variance“来调用。
from sklearn.metrics import explained_variance_score as EVSEVS(Ytest,Yhat)0.6046102673854398cross_val_score(reg,x,y,cv=10,scoring="explained_variance").mean()0.5384986901370823import matplotlib.pyplot as pltplt.plot(range(len(ytest)),sorted(ytest),c="black",label="data")plt.plot(range(len(yhat)),sorted(yhat),c="red",label="data")plt.legend()plt.show()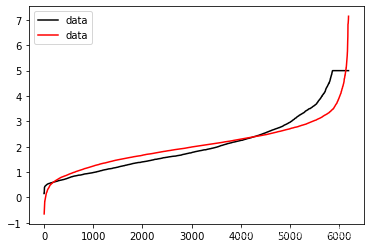
PS:EVS和是异曲同工的,两者都是衡量 1 - 没有捕获到的信息占总信息的比例,EVS和难道不应该相等吗?但从我们的结果来看,两者虽然相似,但却并不完全相等,这中间的差值究竟是什么呢?和EVS有什么不同?
首先看一组有趣的情况:
import numpy as nprng=np.random.RandomState(42)x=rng.randn(100,80)y=rng.randn(100)cross_val_score(LR(),x,y,cv=5,scoring='r2')array([-178.71468148, -5.64707178, -15.13900541, -77.74877079, -60.3727755 ])以上说明了也可以为负!!!
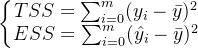 又:
又: 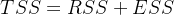 如果将 带入TSS和ESS,那么就有: 怎么可能为负呢? 因为公式TSS=RSS+ESS不是永远成立的! 因为公式TSS=RSS+ESS不是永远成立的! 因为公式TSS=RSS+ESS不是永远成立的!
如果将 带入TSS和ESS,那么就有: 怎么可能为负呢? 因为公式TSS=RSS+ESS不是永远成立的! 因为公式TSS=RSS+ESS不是永远成立的! 因为公式TSS=RSS+ESS不是永远成立的!  许多教材和博客中让
许多教材和博客中让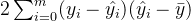 这个式子为0,公式TSS=RSS+ESS自然就成立了,但要让这个式子成立是有条件的。现在有了这个式子的存在, 就可以是一个负数了。只要我们的
这个式子为0,公式TSS=RSS+ESS自然就成立了,但要让这个式子成立是有条件的。现在有了这个式子的存在, 就可以是一个负数了。只要我们的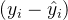 衡量的是真实值到预测值的距离,而
衡量的是真实值到预测值的距离,而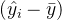 衡量的是预测值到均值的距离,只要当这两个部分的符号不同的时候,而 就有机会是一个负数。 当 显示为负的时候,这证明我们的模型对我们的数据的拟合非常糟糕,模型完全不能使用。 所以,一个负的 是合理的。当然了,现实应用中,如果你发现你的线性回归模型出现了负的 ,不代表你就要接受他了,首先检查你的建模过程和数据处理过程是否正确,也许你已经伤害了数据本身,也许你的建模过程是存在bug 的。如果你检查了所有的代码,也确定了你的预处理没有问题,但你的 也还是负的,那这就证明,线性回归模型不适合你的数据。
衡量的是预测值到均值的距离,只要当这两个部分的符号不同的时候,而 就有机会是一个负数。 当 显示为负的时候,这证明我们的模型对我们的数据的拟合非常糟糕,模型完全不能使用。 所以,一个负的 是合理的。当然了,现实应用中,如果你发现你的线性回归模型出现了负的 ,不代表你就要接受他了,首先检查你的建模过程和数据处理过程是否正确,也许你已经伤害了数据本身,也许你的建模过程是存在bug 的。如果你检查了所有的代码,也确定了你的预处理没有问题,但你的 也还是负的,那这就证明,线性回归模型不适合你的数据。 来源地址:https://blog.csdn.net/weixin_60200880/article/details/127909423
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341














