



单变量:表达式、方程式、函数或者一元多项式等
数据:http://www.presidency.ucsb.edu/data/sourequests.php美国总统历年在国情咨文中对国会提起的诉求数量
本次使用到的数据量并不多,不过还是按照常规思路,通过爬虫获取。
1 import urllib.request
2 import re
3
4
5 def crawler(url):
6 headers = {
7 "User-Agent": "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
8 }
9 req = urllib.request.Request(url, headers=headers)
10 response = urllib.request.urlopen(req)
11
12 html = response.read().decode('utf-8')
13 print(type(html))
14
15 pat = r'<tr align="center">(.*?)</tr>'
16 re_html = re.compile(pat, re.S) # re.S可以使匹配换行
17 trslist = re_html.findall(html) # 匹配出每条信息的数据
18
19 x = []
20 y = []
21 for tr in trslist:
22 re_i = re.compile(r'<div align="center">(.*?)</div>', re.S)
23 i = re_i.findall(tr)
24 x.append(int(i[1].strip())) # 从每条数据中取出所需要的两个数据年份和诉求数量
25 y.append(int(i[2].strip()) if i[2] != '' else 0) # 当匹配到空字符串时就是数据缺失部分,用0代替
26 print(x,y) # 查看结果发现第一组和第四组数据有误,看源码发现他们两个的分类名不是使用的center标签,为了简便,手动添加这两个数据
27 x[0] = 1946
28 y[0] = 41
29 x[3] = 1949
30 y[3] = 28
31 return x, y
32
33 url = "http://www.presidency.ucsb.edu/data/sourequests.php"
34 x, y = crawler(url)得到的数据:
x:[41, 1947, 1948, 28, 1950, 1951, 1952, 1953, 1954, 1955, 1956, 1957, 1958, 1959, 1960,
1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 1970, 1971, 1972, 1973, 1974, 1975,
1976, 1977, 1978, 1979, 1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989, 1990,
1991, 1992, 1993, 1994, 1995, 1996, 1997]
y:[16, 23, 16, 17, 20, 11, 19, 14, 39, 32, 0, 14, 0, 16, 6, 25, 24, 18, 17, 38, 31, 27, 26,
17, 21, 20, 17, 23, 16, 13, 13, 21, 11, 13, 11, 8, 8, 14, 9, 7, 5, 5, 54, 34, 18, 20, 27,
30, 22, 25, 19, 26]
1 import numpy as np
2 import matplotlib.pyplot as plt
3 from matplotlib.pylab import frange
4
5 plt.figure(1)
6 plt.title("All data")
7 plt.plot(x, y, 'ro')
8 plt.xlabel('year')
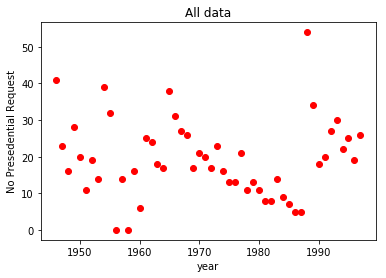
9 plt.ylabel('No Presedential Request')根据获取到的数据绘制出散点图,观察其分布情况,发现有一个极大的异常点,和两个为零的异常点(获取数据时的缺失值,默认填充为0).
1 # 使用numpy中的求分位数函数分别计算
2 perc_25 = np.percentile(y, 25)
3 perc_50 = np.percentile(y, 50)
4 perc_75 = np.percentile(y, 75)
5 print("25th Percentile = %.2f" % perc_25)
6 print("50th Percentile = %.2f" % perc_50)
7 print("75th Percentile = %.2f" % perc_75)
8
9 '''
10 结果:
11 25th Percentile = 13.00
12 50th Percentile = 18.50
13 75th Percentile = 25.25
14 '''上面已经求得各分位数值,分别在图中画出来,为了在上面原始图中画出,要放在一起执行:
1 # 在图中画出第25、50、75位的百分位水平线
2 # ----------------------------------------
3 plt.figure(1)
4 plt.title("All data")
5 plt.plot(x, y, 'ro')
6 plt.xlabel('year')
7 plt.ylabel('No Presedential Request')
8 # ----------------------------------------
9 plt.axhline(perc_25, label='25th perc', c='r')
10 plt.axhline(perc_50, label='50th perc', c='g')
11 plt.axhline(perc_75, label='75th perc', c='m')
12 plt.legend(loc='best')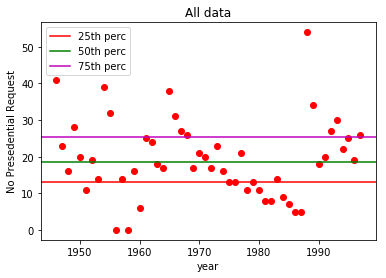
1 # 检查生成的图形中是否有异常点,若有,使用mask函数将其删除
2 # 0是在起初获取数据时候的缺失值的填充,根据图像看到y=54的点远远高出其他,也按异常值处理
3 y = np.array(y) # 起初发现y为0的点没有被删掉,考虑到他是对数组进行隐藏,而本来的y是个列表,因此又加了这一句,果然去掉了两个零点
4 y_masked = np.ma.masked_where(y==0, y)
5 y_masked = np.ma.masked_where(y_masked==54, y_masked)
6 print(type(y),type(y_masked))
7
8 '''
9 <class 'numpy.ndarray'> <class 'numpy.ma.core.MaskedArray'>
10 '''重新绘制图像:
1 # 重新绘制图像
2 plt.figure(2)
3 plt.title("Masked data")
4 plt.plot(x, y_masked, 'ro')
5 plt.xlabel('year')
6 plt.ylabel('No Presedential Request')
7 plt.ylim(0, 60)
8
9 # 在图中画出第25、50、75位的百分位的水平线
10 plt.axhline(perc_25, label='25th perc', c='r')
11 plt.axhline(perc_50, label='50th perc', c='g')
12 plt.axhline(perc_75, label='75th perc', c='m')
13 plt.legend(loc='best')
14 plt.show() 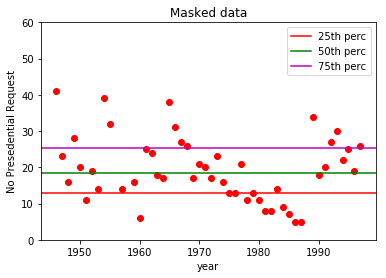
得到的最后的图像,就是去除了0和54的三个异常点后的结果。
plot
1 plt.close('all') # 关闭之前打开的所有图形
2 plt.figure(1) # 给图形编号,在绘制多个图形的时候有用
3 plt.title('All data') # 设置标题
4 plt.plot(x, y, 'ro') # "ro" 表示使用红色(r)的点(o)来绘图百分位数
一组n个观测值按数值大小排列。如,处于p%位置的值称第p百分位数。p=50,等价于中位数;p=0,等价于最小值;p=100,等价于最大值。
plt.axhline()
给定y的位置,从x的最小值一直画到x的最大值
label设置名称
c参数设置线条颜色
eg:perc_25 = 13.00
plt.axhline(perc_25, label='25th perc', c='r')
legend(loc)
plt.legend() 是将图中一些标签显示出来
loc参数让pyplot决定最佳放置位置,以免影响读图
numpy-mask函数
删除异常点
y_masked = np.ma.masked_where(y==0, y)
ma.masked_where函数接受两个参数,他将数组中符合条件的点进行隐藏,而不需要删除













