

Python基于决策树算法的分类预测怎么实现

短信预约 -IT技能 免费直播动态提醒
今天小编给大家分享一下Python基于决策树算法的分类预测怎么实现的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
一、决策树的特点
1.优点
具有很好的解释性,模型可以生成可以理解的规则。
可以发现特征的重要程度。
模型的计算复杂度较低。
2.缺点
模型容易过拟合,需要采用减枝技术处理。
不能很好利用连续型特征。
预测能力有限,无法达到其他强监督模型效果。
方差较高,数据分布的轻微改变很容易造成树结构完全不同。
二、决策树的适用场景
决策树模型多用于处理自变量与因变量是非线性的关系。
梯度提升树(GBDT),XGBoost以及LightGBM等先进的集成模型均采用决策树作为基模型。(多粒度联森林模型)
决策树在一些明确需要可解释性或者提取分类规则的场景中被广泛应用。在医疗辅助系统中为了方便专业人员发现错误,常常将决策树算法用于辅助病症检测。
三、demo
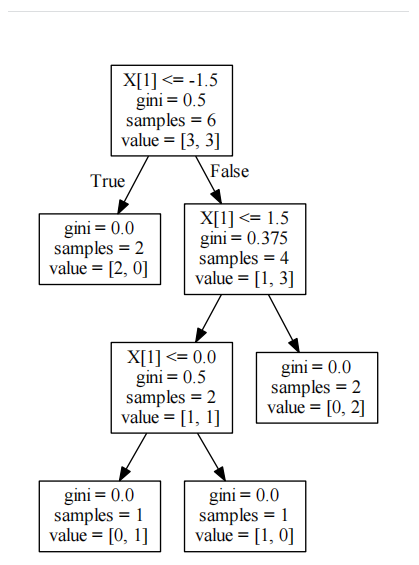
#%%demo## 基础函数库导入import numpy as np ## 导入画图库import matplotlib.pyplot as pltimport seaborn as sns## 导入决策树模型函数from sklearn.tree import DecisionTreeClassifierfrom sklearn import treeimport pydotplus from IPython.display import Image##Demo演示DecisionTree分类## 构造数据集x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]])y_label = np.array([0, 1, 0, 1, 0, 1])## 调用决策树回归模型tree_clf = DecisionTreeClassifier()## 调用决策树模型拟合构造的数据集tree_clf = tree_clf.fit(x_fearures, y_label)## 可视化构造的数据样本点plt.figure()plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')plt.title('Dataset')plt.show()## 可视化决策树import graphvizdot_data = tree.export_graphviz(tree_clf, out_file=None)graph = pydotplus.graph_from_dot_data(dot_data)graph.write_pdf("D:\Python\ML\DecisionTree.pdf") # 模型预测## 创建新样本x_fearures_new1 = np.array([[0, -1]])x_fearures_new2 = np.array([[2, 1]])## 在训练集和测试集上分布利用训练好的模型进行预测y_label_new1_predict = tree_clf.predict(x_fearures_new1)y_label_new2_predict = tree_clf.predict(x_fearures_new2)print('The New point 1 predict class:\n',y_label_new1_predict)print('The New point 2 predict class:\n',y_label_new2_predict)运行结果
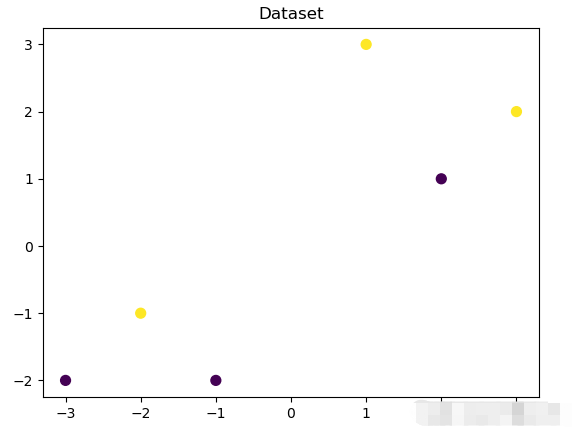
训练集决策树
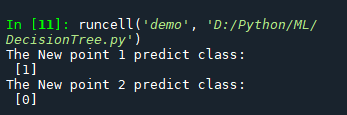
以上就是“Python基于决策树算法的分类预测怎么实现”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注编程网行业资讯频道。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341











