

Python人工智能中波士顿房价数据分析的案例


这篇文章主要为大家展示了“Python人工智能中波士顿房价数据分析的案例”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Python人工智能中波士顿房价数据分析的案例”这篇文章吧。
1.数据概览分析
1.1 数据概览
本次提供:
train.csv,训练集;
test.csv,测试集;
submission.csv 真实房价文件;
训练集404行数据,14列,每行数据表示房屋以及房屋周围的详细信息,已给出对应的自住房平均房价。要求预测102条测试数据的房价。
1.2 数据分析
通过学习房屋以及房屋周围的详细信息,其中包含城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等,训练模型,通过某个地区的房屋以及房屋周围的详细信息,预测该地区的自住房平均房价。
回归问题,提交测试集每条数据对应的自住房平均房价。评估指标为均方误差mse。
2. 项目总体思路
2.1 数据读取
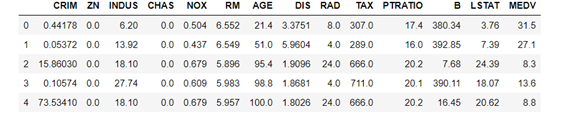
数据集:波士顿房间训练集.csv (404条数据)
数据集字段如下:
CRIM:城镇人均犯罪率。
ZN:住宅用地超过 25000 sq.ft. 的比例。
INDUS:城镇非零售商用土地的比例。
CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0)。
NOX:一氧化氮浓度。
RM:住宅平均房间数。
AGE:1940 年之前建成的自用房屋比例。
DIS:到波士顿五个中心区域的加权距离。
RAD:辐射性公路的接近指数。
TAX:每 10000 美元的全值财产税率。
PTRATIO:城镇师生比例。
B:1000(Bk-0.63)^ 2,其中 Bk 指代城镇中黑人的比例。
LSTAT:人口中地位低下者的比例。
MEDV:自住房的平均房价,以千美元计。
2.2 模型预处理
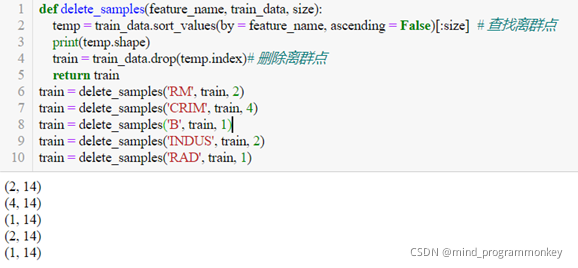
(1)数据离群点处理
首先对训练集进行拆分为子训练集与子测试集,利用train_data.sort_values对训练集进行排序,依次删除每个特征对应的离群样本,利用子训练集与子测试集对模型进行训练与测试并确定该特征下所需删除样本的最佳个数。
(2)数据归一化处理
利用sklearn.preprocessing. StandardScaler对数据集与标签分别进行标准化处理。

2.3. 特征工程
利用随机森林特征选择算法剔除不敏感特征。

2.4. 模型选择
使用GradientBoostingRegressor集成回归模型。
Gradient Boosting 在迭代的时候选择梯度下降的方向来保证最后的结果最好。损失函数用来描述模型的“靠谱”程度,假设模型没有过拟合,损失函数越大,模型的错误率越高
如果我们的模型能够让损失函数持续的下降,则说明我们的模型在不停的改进,而最好的方式就是让损失函数在其梯度方向上下降。


2.5. 模型评价
采用均方误差(MSE)评分标准,MSE: Mean Squared Error 。均方误差是指参数估计值与参数真值之差平方的期望值;
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。计算公式如下:
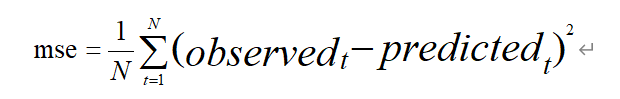
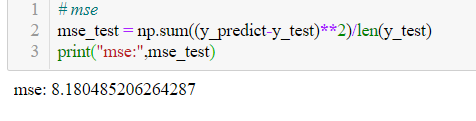
其在测试集上的MSE值为:
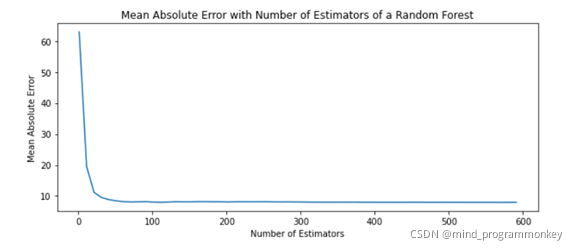
2.6. 模型调参
对n_ n_estimators的参数进行调参:
以上是“Python人工智能中波士顿房价数据分析的案例”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注编程网行业资讯频道!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341














