

python如何爬取豆瓣电影TOP250数据

短信预约 -IT技能 免费直播动态提醒

这篇文章将为大家详细讲解有关python如何爬取豆瓣电影TOP250数据,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
在执行程序前,先在MySQL中创建一个数据库"pachong"。
import pymysqlimport requestsimport re#获取资源并下载def resp(listURL): #连接数据库 conn = pymysql.connect( host = '127.0.0.1', port = 3306, user = 'root', password = '******', #数据库密码请根据自身实际密码输入 database = 'pachong', charset = 'utf8' ) #创建数据库游标 cursor = conn.cursor() #创建列表t_movieTOP250(执行sql语句) cursor.execute('create table t_movieTOP250(id INT PRIMARY KEY auto_increment NOT NULL ,movieName VARCHAR(20) NOT NULL ,pictrue_address VARCHAR(100))') try: # 爬取数据 for urlPath in listURL: # 获取网页源代码 response = requests.get(urlPath) html = response.text # 正则表达式 namePat = r'alt="(.*?)" class="lazy" data-src=' imgPat = r'class="lazy" data-src="(.*?)" class=' # 匹配正则(排名【用数据库中id代替,自动生成及排序】、电影名、电影海报(图片地址)) res2 = re.compile(namePat) res3 = re.compile(imgPat) textList2 = res2.findall(html) textList3 = res3.findall(html) # 遍历列表中元素,并将数据存入数据库 for i in range(len(textList3)): cursor.execute('insert into t_movieTOP250(movieName,pictrue_address) VALUES("%s","%s")' % (textList2[i],textList3[i])) #从游标中获取结果 cursor.fetchall() #提交结果 conn.commit() print("结果已提交") except Exception as e: #数据回滚 conn.rollback() print("数据已回滚") #关闭数据库 conn.close()#top250所有网页网址def page(url): urlList = [] for i in range(10): num = str(25*i) pagePat = r'?start=' + num + '&filter=' urL = url+pagePat urlList.append(urL) return urlListif __name__ == '__main__': url = r"https://movie.douban.com/top250" listURL = page(url) resp(listURL)结果如下图:
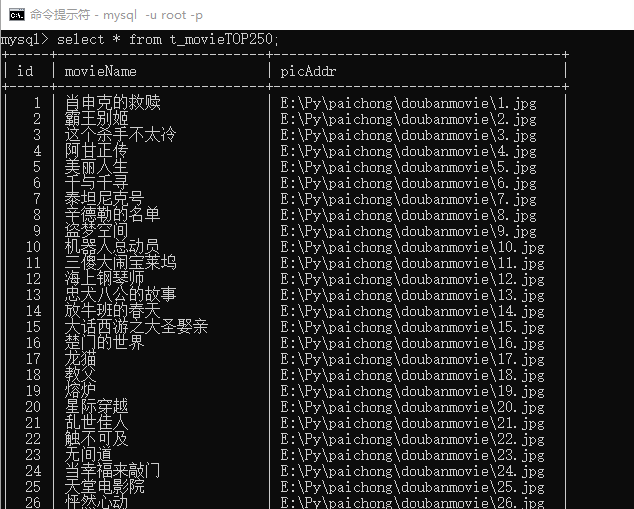
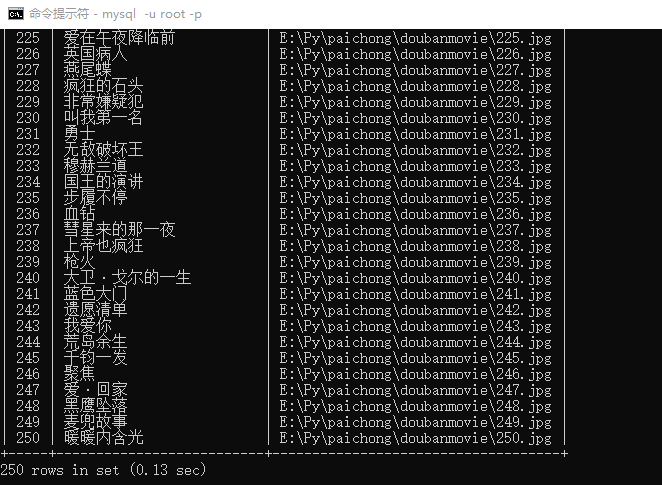
python是什么意思
Python是一种跨平台的、具有解释性、编译性、互动性和面向对象的脚本语言,其最初的设计是用于编写自动化脚本,随着版本的不断更新和新功能的添加,常用于用于开发独立的项目和大型项目。
关于“python如何爬取豆瓣电影TOP250数据”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341













