

如何调用Web API


本篇内容介绍了“如何调用Web API”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
第一步:打开开发者工具,找一个 JSON 响应
我浏览了 https://hangouts.google.com,在 Firefox 的开发者工具中打开“网络Network”标签,找到一个 JSON 响应。你也可以使用 Chrome 的开发者工具。
打开之后界面如下图:
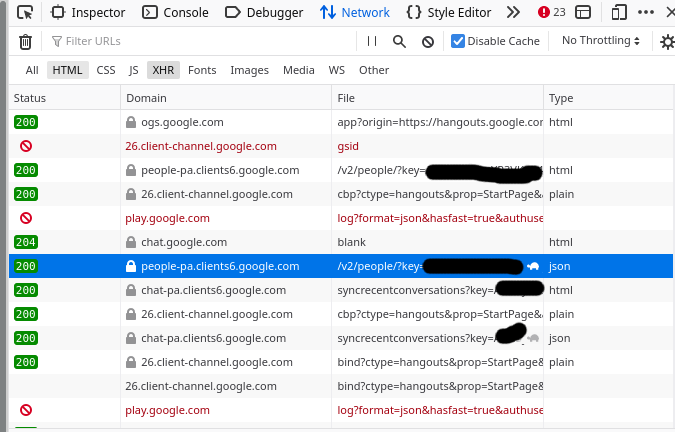
找到其中一条 “类型Type” 列显示为 json 的请求。
为了找一条感兴趣的请求,我找了好一会儿,突然我找到一条 “people” 的端点,看起来是返回我们的联系人信息。听起来很有意思,我们来看一下。
第二步:复制为 cURL
下一步,我在感兴趣的请求上右键,点击 “复制Copy” -> “复制为 cURLCopy as cURL”。
然后我把 curl 命令粘贴到终端并运行。下面是运行结果:
$ curl 'https://people-pa.clients6.google.com/v2/people/?key=REDACTED' -X POST ........ (省略了大量请求标头)Warning: Binary output can mess up your terminal. Use "--output -" to tell Warning: curl to output it to your terminal anyway, or consider "--output Warning: <FILE>" to save to a file.你可能会想 —— 很奇怪,“二进制的输出在你的终端上无法正常显示” 是什么错误?原因是,浏览器默认情况下发给服务器的请求头中有 Accept-Encoding: gzip, deflate 参数,会把输出结果进行压缩。
我们可以通过管道把输出传递给 gunzip 来解压,但是我们发现不带这个参数进行请求会更简单。因此我们去掉一些不相关的请求头。
第三步:去掉不相关的请求头
下面是我从浏览器获得的完整 curl 命令。有很多行!我用反斜杠(\)把请求分开,这样每个请求头占一行,看起来更清晰:
curl 'https://people-pa.clients6.google.com/v2/people/?key=REDACTED' \-X POST \-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:96.0) Gecko/20100101 Firefox/96.0' \-H 'Accept: */*' \-H 'Accept-Language: en' \-H 'Accept-Encoding: gzip, deflate' \-H 'X-HTTP-Method-Override: GET' \-H 'Authorization: SAPISIDHASH REDACTED' \-H 'Cookie: REDACTED'-H 'Content-Type: application/x-www-form-urlencoded' \-H 'X-Goog-AuthUser: 0' \-H 'Origin: https://hangouts.google.com' \-H 'Connection: keep-alive' \-H 'Referer: https://hangouts.google.com/' \-H 'Sec-Fetch-Dest: empty' \-H 'Sec-Fetch-Mode: cors' \-H 'Sec-Fetch-Site: same-site' \-H 'Sec-GPC: 1' \-H 'DNT: 1' \-H 'Pragma: no-cache' \-H 'Cache-Control: no-cache' \-H 'TE: trailers' \--data-raw 'personId=101777723309&personId=1175339043204&personId=1115266537043&personId=116731406166&extensionSet.extensionNames=HANGOUTS_ADDITIONAL_DATA&extensionSet.extensionNames=HANGOUTS_OFF_NETWORK_GAIA_GET&extensionSet.extensionNames=HANGOUTS_PHONE_DATA&includedProfileStates=ADMIN_BLOCKED&includedProfileStates=DELETED&includedProfileStates=PRIVATE_PROFILE&mergedPersonSourceOptions.includeAffinity=CHAT_AUTOCOMPLETE&coreIdParams.useRealtimeNotificationExpandedAcls=true&requestMask.includeField.paths=person.email&requestMask.includeField.paths=person.gender&requestMask.includeField.paths=person.in_app_reachability&requestMask.includeField.paths=person.metadata&requestMask.includeField.paths=person.name&requestMask.includeField.paths=person.phone&requestMask.includeField.paths=person.photo&requestMask.includeField.paths=person.read_only_profile_info&requestMask.includeField.paths=person.organization&requestMask.includeField.paths=person.location&requestMask.includeField.paths=person.cover_photo&requestMask.includeContainer=PROFILE&requestMask.includeContainer=DOMAIN_PROFILE&requestMask.includeContainer=CONTACT&key=REDACTED'第一眼看起来内容有很多,但是现在你不需要考虑每一行是什么意思。你只需要把不相关的行删掉就可以了。
我通常通过删掉某行查看是否有错误来验证该行是不是可以删除 —— 只要请求没有错误就一直删请求头。通常情况下,你可以删掉 Accept*、Referer、Sec-*、DNT、User-Agent 和缓存相关的头。
在这个例子中,我把请求删成下面的样子:
curl 'https://people-pa.clients6.google.com/v2/people/?key=REDACTED' \-X POST \-H 'Authorization: SAPISIDHASH REDACTED' \-H 'Content-Type: application/x-www-form-urlencoded' \-H 'Origin: https://hangouts.google.com' \-H 'Cookie: REDACTED'\--data-raw 'personId=101777723309&personId=1175339043204&personId=1115266537043&personId=116731406166&extensionSet.extensionNames=HANGOUTS_ADDITIONAL_DATA&extensionSet.extensionNames=HANGOUTS_OFF_NETWORK_GAIA_GET&extensionSet.extensionNames=HANGOUTS_PHONE_DATA&includedProfileStates=ADMIN_BLOCKED&includedProfileStates=DELETED&includedProfileStates=PRIVATE_PROFILE&mergedPersonSourceOptions.includeAffinity=CHAT_AUTOCOMPLETE&coreIdParams.useRealtimeNotificationExpandedAcls=true&requestMask.includeField.paths=person.email&requestMask.includeField.paths=person.gender&requestMask.includeField.paths=person.in_app_reachability&requestMask.includeField.paths=person.metadata&requestMask.includeField.paths=person.name&requestMask.includeField.paths=person.phone&requestMask.includeField.paths=person.photo&requestMask.includeField.paths=person.read_only_profile_info&requestMask.includeField.paths=person.organization&requestMask.includeField.paths=person.location&requestMask.includeField.paths=person.cover_photo&requestMask.includeContainer=PROFILE&requestMask.includeContainer=DOMAIN_PROFILE&requestMask.includeContainer=CONTACT&key=REDACTED'这样我只需要 4 个请求头:Authorization、Content-Type、Origin 和 Cookie。这样容易管理得多。
第四步:在 Python 中发请求
现在我们知道了我们需要哪些请求头,我们可以把 curl 命令翻译进 Python 程序!这部分是相当机械化的过程,目标仅仅是用 Python 发送与 cUrl 相同的数据。
下面是代码实例。我们使用 Python 的 requests 包实现了与前面 curl 命令相同的功能。我把整个长请求分解成了元组的数组,以便看起来更简洁。
import requestsimport urllibdata = [ ('personId','101777723'), # I redacted these IDs a bit too ('personId','117533904'), ('personId','111526653'), ('personId','116731406'), ('extensionSet.extensionNames','HANGOUTS_ADDITIONAL_DATA'), ('extensionSet.extensionNames','HANGOUTS_OFF_NETWORK_GAIA_GET'), ('extensionSet.extensionNames','HANGOUTS_PHONE_DATA'), ('includedProfileStates','ADMIN_BLOCKED'), ('includedProfileStates','DELETED'), ('includedProfileStates','PRIVATE_PROFILE'), ('mergedPersonSourceOptions.includeAffinity','CHAT_AUTOCOMPLETE'), ('coreIdParams.useRealtimeNotificationExpandedAcls','true'), ('requestMask.includeField.paths','person.email'), ('requestMask.includeField.paths','person.gender'), ('requestMask.includeField.paths','person.in_app_reachability'), ('requestMask.includeField.paths','person.metadata'), ('requestMask.includeField.paths','person.name'), ('requestMask.includeField.paths','person.phone'), ('requestMask.includeField.paths','person.photo'), ('requestMask.includeField.paths','person.read_only_profile_info'), ('requestMask.includeField.paths','person.organization'), ('requestMask.includeField.paths','person.location'), ('requestMask.includeField.paths','person.cover_photo'), ('requestMask.includeContainer','PROFILE'), ('requestMask.includeContainer','DOMAIN_PROFILE'), ('requestMask.includeContainer','CONTACT'), ('key','REDACTED')]response = requests.post('https://people-pa.clients6.google.com/v2/people/?key=REDACTED', headers={ 'X-HTTP-Method-Override': 'GET', 'Authorization': 'SAPISIDHASH REDACTED', 'Content-Type': 'application/x-www-form-urlencoded', 'Origin': 'https://hangouts.google.com', 'Cookie': 'REDACTED', }, data=urllib.parse.urlencode(data),)print(response.text)我执行这个程序后正常运行 —— 输出了一堆 JSON 数据!太棒了!
你会注意到有些地方我用 REDACTED 代替了,因为如果我把原始数据列出来你就可以用我的账号来访问谷歌论坛了,这就很不好了。
运行结束
现在我可以随意修改 Python 程序,比如传入不同的参数,或解析结果等。
我不打算用它来做其他有意思的事了,因为我压根对这个 API 没兴趣,我只是用它来阐述请求 API 的过程。
但是你确实可以对返回的一堆 JSON 做一些处理。
curlconverter 看起来很强大
有人评论说可以使用 https://curlconverter.com/ 自动把 curl 转换成 Python(和一些其他的语言!),这看起来很神奇 —— 我都是手动转的。我在这个例子里使用了它,看起来一切正常。
追踪 API 的处理过程并不容易
我不打算夸大追踪 API 处理过程的难度 —— API 的处理过程并不明显!我也不知道传给这个谷歌论坛 API 的一堆参数都是做什么的!
但是有一些参数看起来很直观,比如
requestMask.includeField.paths=person.email
可能表示“包含每个人的邮件地址”。因此我只关心我能看懂的参数,不关心看不懂的。
(理论上)适用于所有场景
可能有人质疑 —— 这个方法适用于所有场景吗?
答案是肯定的 —— 浏览器不是魔法!浏览器发送给你的服务器的所有信息都是 HTTP 请求。因此如果我复制了浏览器发送的所有的 HTTP 请求头,那么后端就会认为请求是从我的浏览器发出的,而不是用 Python 程序发出的。
当然,我们去掉了一些浏览器发送的请求头,因此理论上后端是可以识别出来请求是从浏览器还是 Python 程序发出的,但是它们通常不会检查。
这里有一些对读者的告诫 —— 一些谷歌服务的后端会通过令人难以理解(对我来说是)方式跟前端通信,因此即使理论上你可以模拟前端的请求,但实际上可能行不通。可能会遭受更多攻击的大型 API 会有更多的保护措施。
我们已经知道了如何调用没有文档说明的 API。现在我们再来聊聊可能遇到的问题。
问题 1:会话 cookie 过期
一个大问题是我用我的谷歌会话 cookie 作为身份认证,因此当我的浏览器会话过期后,这个脚本就不能用了。
这意味着这种方式不能长久使用(我宁愿调一个真正的 API),但是如果我只是要一次性快速抓取一小组数据,那么可以使用它。
问题 2:滥用
如果我正在请求一个小网站,那么我的 Python 脚本可能会把服务打垮,因为请求数超出了它们的处理能力。因此我请求时尽量谨慎,尽量不过快地发送大量请求。
这尤其重要,因为没有官方 API 的网站往往是些小网站且没有足够的资源。
很明显在这个例子中这不是问题 —— 我认为在写这篇文章的过程我一共向谷歌论坛的后端发送了 20 次请求,他们肯定可以处理。
如果你用自己的账号身份过度访问这个 API 并导致了故障,那么你的账号可能会被暂时封禁(情理之中)。
我只下载我自己的数据或公共的数据 —— 我的目的不是寻找网站的弱点。
“如何调用Web API”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!
免责声明:
① 本站未注明“稿件来源”的信息均来自网络整理。其文字、图片和音视频稿件的所属权归原作者所有。本站收集整理出于非商业性的教育和科研之目的,并不意味着本站赞同其观点或证实其内容的真实性。仅作为临时的测试数据,供内部测试之用。本站并未授权任何人以任何方式主动获取本站任何信息。
② 本站未注明“稿件来源”的临时测试数据将在测试完成后最终做删除处理。有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341











