爬取豆瓣电影信息
昨天写了一个小爬虫,爬取了豆瓣上2017年中国大陆的电影信息,网址为豆瓣选影视,爬取了电影的名称、导演、编剧、主演、类型、上映时间、片长、评分和链接,并保存到MongoDB中。一开始用的本机的IP地址,没用代理IP,请求了十几个网页之后就收
2024-11-16
爬取豆瓣电影排行top250
爬取豆瓣电影排行top250功能分析:使用的库1、time2、json3、requests4、BuautifulSoup5、RequestException""" 作者:李舵 日期:2019-4-27 功能:抓取豆瓣电影t
2024-11-16
python爬取豆瓣电影TOP250数据
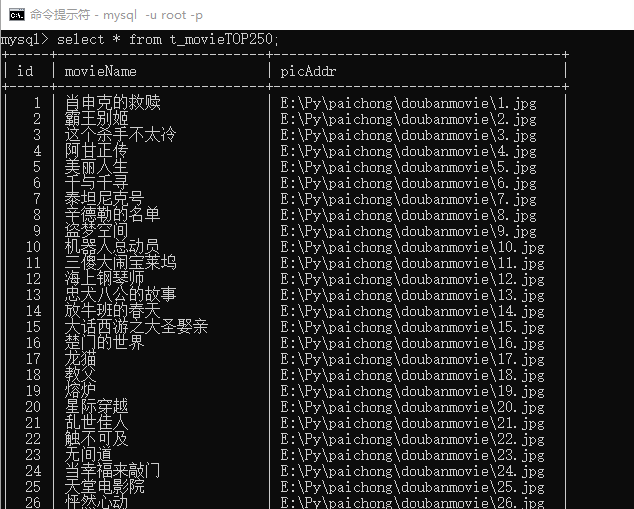
在执行程序前,先在MySQL中创建一个数据库"pachong"。import pymysql
import requests
import re#获取资源并下载
def resp(listURL):#连接数据库conn = pymysql.
2024-11-16
python爬取豆瓣top250的电影数
爬取网址: https://movie.douban.com/top250一:爬取思路(新手可以看一下) : 1:定义两个函数,一个get_page函数爬取数据,一个save函数保存数据,mian中向get_page函数传递url
2024-11-16
(转)Python3爬取豆瓣电影保存到
48行代码实现Python3爬取豆瓣电影排行榜代码基于python3,用到的类库有:标题文字requests:通过伪造请求头或设置代理等方式获取页面内容,参考文档BeautifulSoup:对页面进行解析,提取数据,参考文档PyMySQL:
2024-11-16
Python爬虫怎么爬取豆瓣影评
本篇内容主要讲解“Python爬虫怎么爬取豆瓣影评”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Python爬虫怎么爬取豆瓣影评”吧!一、学习开始前需安装模块pip install reques
2024-11-16
Python爬虫爬取豆瓣电影之数据提取值
工具:Python 3.6.5、PyCharm开发工具、Windows 10 操作系统、谷歌浏览器目的:爬取豆瓣电影排行榜中电影的title、链接地址、图片、评价人数、评分等网址:https://movie.douban.com/chart
2024-11-16
怎么用python爬取豆瓣前一百电影
这期内容当中小编将会给大家带来有关怎么用python爬取豆瓣前一百电影,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。python是什么意思Python是一种跨平台的、具有解释性、编译性、互动性和面向对象的
2024-11-16
使用Python怎么爬取豆瓣电影名
这期内容当中小编将会给大家带来有关使用Python怎么爬取豆瓣电影名,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。Python的优点有哪些1、简单易用,与C/C++、Java、C# 等传统语言相比,Pyt
2024-11-16
Python爬取豆瓣电影方法是什么
本篇内容主要讲解“Python爬取豆瓣电影方法是什么”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Python爬取豆瓣电影方法是什么”吧!主要目标 环境:MAC + Python3.6 ;
2024-11-16
python如何爬取豆瓣电影TOP250数据
这篇文章将为大家详细讲解有关python如何爬取豆瓣电影TOP250数据,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。在执行程序前,先在MySQL中创建一个数据库"pachong"。import pymy
2024-11-16
转载—Python抓取豆瓣电影
#!/usr/bin/python# -*-coding:utf-8-*-# Python: 2.7# Program: 爬取豆瓣电影 from bs4 import BeautifulSoupimport urllib2, json
2024-11-16
13行代码实现爬取豆瓣250电影榜单
原理很简单,通过发送resquest请求获取服务器的response,再使用xpath提取其中我们需要的数据,然后保存到文件中。先看看我爬取的结果:首先,需要用到的模块有两个:•requests•lxml第一步,我们先用Chrome的检查分
2024-11-16
如何使用Selenium爬取豆瓣电影前100的爱情片
小编给大家分享一下如何使用Selenium爬取豆瓣电影前100的爱情片,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!什么是SeleniumSelenium是一个用
2024-11-16
Python3 爬取豆瓣书籍 Xpat
#coding:utf8import timefrom urllib import requestfrom bs4 import BeautifulSoupnum = 1#用来计算一共爬取了多少本书start_time = time.tim
2024-11-16























![[mysql]mysql8修改root密码](https://static.528045.com/imgs/15.jpg?imageMogr2/format/webp/blur/1x0/quality/35)





